
What is Data Lake:
Data Lake is a centralized repository with many data in native and raw formats. The data lake has Distributed File Systems that provide cheap storage of large volumes of data. It supports different file formats like Parquet, CSV, JSON, etc. It supports massive parallel execution engines that do not require special hardware, which is completely separated from storage. It provides cheaper execution when compared to the Data warehouse.
In Data Lake, the data is ingested in raw format and moves to different zones like raw zone, exploratory zone, trusted zone, and refined zone before being consumed by the end user. End Users have access only to the refined zone. It uses ELT instead of ETL, which eliminates the need for data staging. Data Lake is preferred since we can put all the data in one location and use it as an optimal platform for all analytical needs.

Data Lakes has a very complex architecture. Extracting the data from diverse data sources requires complex transformations. Big data movements are too slow, and copying some sources like Mainframe data will be very complex. Data lineage to describe the data is not available. Refreshing and managing the data lake also adds complexity.
Data Virtualization:
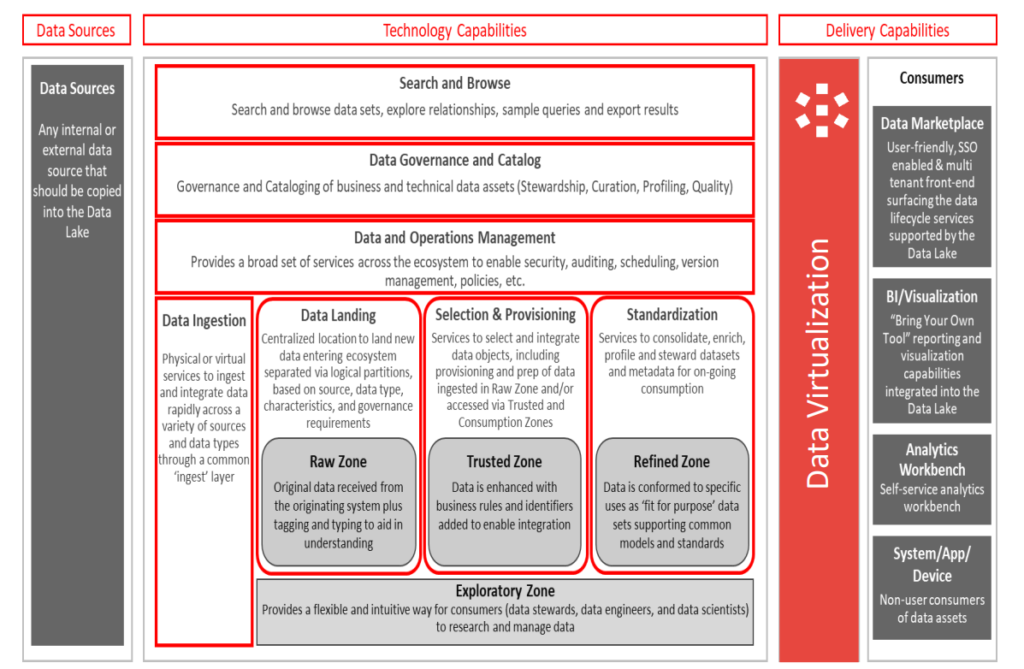
To maximize the benefits of Data Lake, we can use Denodo to implement Data Virtualization. A single, logical, multi-purpose Data Lake can be implemented using Data Virtualization. In Data Lake, the data virtualization can be used for Data collection, Data integration, Data Abstraction, and Data Delivery.
Data can be pulled to one common virtual layer from heterogenous sources without copying or migrating the code. The consuming application requires different data delivery styles and protocols for which the data lake repository is not enough to do it. Data virtualization act as a single data delivery layer for the data lake. Data virtualization abstracts the complexity of underlying sources from the consuming application. Denodo can also integrate with different data lake engines like Hive, Impala, Presto, and Athena, by which we can access and process the data inside the data lake file systems. Data virtualization provides improved governance, security, metadata management, and infrastructure for data lake implementation. It maximizes the processing power of the data lake clusters using Denodo’s optimizer. It allows for combining real-time data from the original data source with the historical data from the clusters. Data Virtualization helps to expose the data from the data lake to users like curated datasets for business users and virtual sandboxes for power users. Data virtualization is not just implemented as a data access layer or service layer but as a key component of the data lake.