
Azure Data Factory is a strong ETL tool, with the capacity of creating ETL pipelines using low code/no code approach. This can be achieved with using “Activities”. Activities are the tasks that are conducted on data within a pipeline.
In this post I demonstrate an ETL process which copies data from one source to another, and performs some tasks on data using Activities in Azure Data Factory as follows:
- Extracts files with a specific substring in their file names from a pool of data files as a source,
- Merges them into one file – data files have the same schema – and,
- Adds a “Created Datetime” column to the merged data file.
Let’s walk through the steps.
1. Extracting files with specific substring in their file names
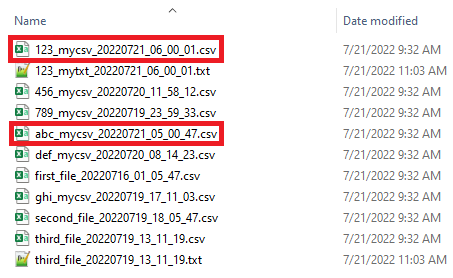
Depending on the structure of the source, pulling in the required files from source might be very straight forward, like extracting all the files in a folder, or all the files with a specific extension (*.txt or *.csv) in a folder. However, it is not always the case. Assume that you have a folder with variety of file types and file names as a source and you need to handpick specific files for your pipeline input. Figure below shows an example of such a folder that contains multiple csv and txt files. However, I am only interested in pulling in the csv files that have “mycsv” and today’s date 20220721, date I am writing this blog, in their file names (two highlighted files).
Someone may suggest using “Filter by last modified” of Copy activity, as we are looking for the today’s files.

But these files all are loaded on daily basis, and this option is not helpful since it pulls in irrelevant data into ETL process.
To have proper filtering on input files in this case, we use Filter activity under Iteration & Conditionals, which provides a tool to filter input variables based on a user-defined condition. Let’s see how.
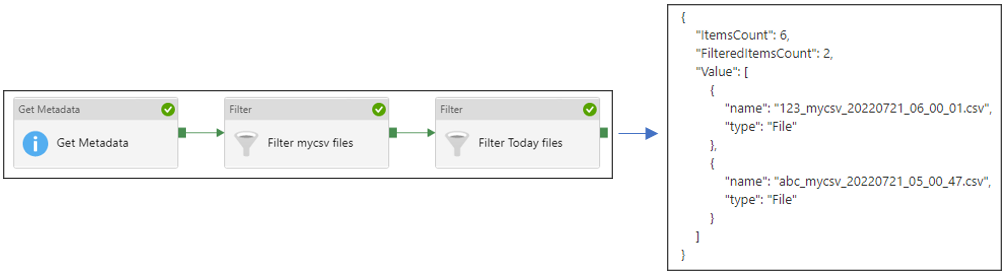
First, we should get the folder content metadata to obtain file names, using Get Metadata activity under General.
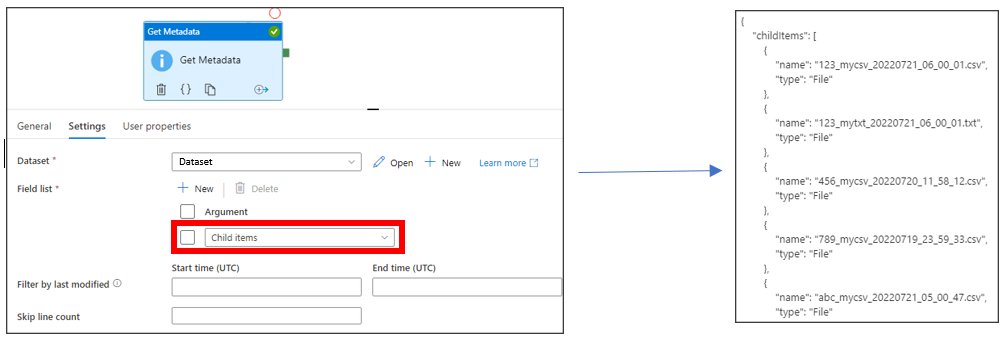
In Settings tab, after defining a dataset for Get Metadata activity, I add a Field List for Child Items. By selecting Child Items, Get Metadata activity returns name and type of the folder content, shown below.
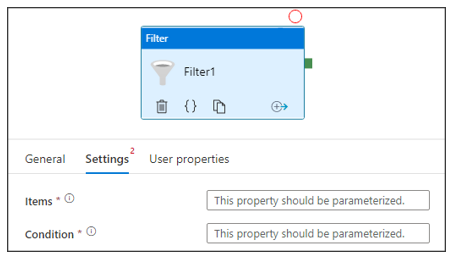
After collecting source folder’s metadata, I need to extract only the files with ‘mycsv’ substring in their file names, using Filter activity. When creating a Filter, there are two fields that should be provided in Settings tab:
- Items: The array of items that should be checked as input.
- Condition: The user-defined filtering condition which should be checked for input arrays.
For our purpose, Items is the output of Get Metadata activity, and Condition is specifying the substring of interest, as follows:
- Items: @activity(‘Get Metadata’).output.childItems
- Condition: @contains(item().name,’mycsv’)
As it is shown below, only files with “mycsv” in their names passed the filter.

Next, by adding a second filter, I extract the files with Today’s date, 20220721, in their file names. The input of the second filter is the output of the first ones, files with ‘mycsv’ in their names. Items and Condition are set as follows:
- Items: @activity(‘Filter mycsv files’).output.value
- Condition: @contains(item().name,utcNow(‘yyyyMMdd’))
Note: These tow filters can be combined in one filter as follows:
- Items: @activity(‘Get Metadata’).output.childItems
- Condition: @and(contains(item().name,’mycsv’),contains(item().name,utcNow(‘yyyyMMdd’)))
2. Merging files with the same schema into a single file, using ADF Copy Activity
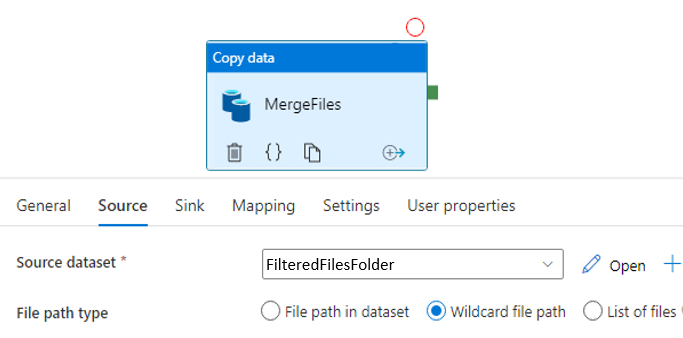
Next, I merge the filtered files in previous step into a single file using Copy activity. It is only doable when files have the same schema.
In Copy activity, Source dataset is the folder that contains filtered files.
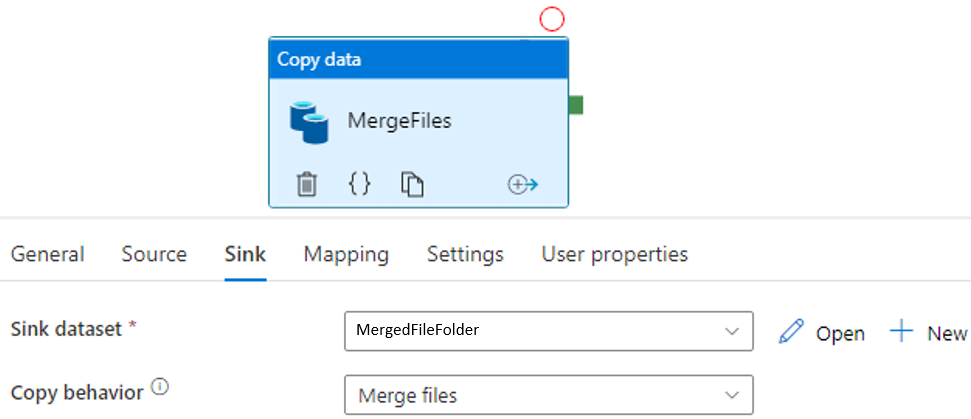
In Sink tab, I define the sink dataset which contains the merged file and set the Copy behavior to Merge files. This combines the files and creates a single file in destination folder.
3. Adding a new column “Created Datetime” to merged file, using ADF
After merging files into a single file, I’d like to capture the date and time the pipeline is executed, by adding a new column “Create Datetime” in CST to the merged file. So, in Source tab of Copy activity, at the very bottom, there is an option “Additional columns” which allows defining new column for the dataset before exporting it to destination. So, I click New, add Name as “Create Datetime” and Value (add dynamic value) to @convertFromUtc(utcNow(), ‘Central Standard Time’).
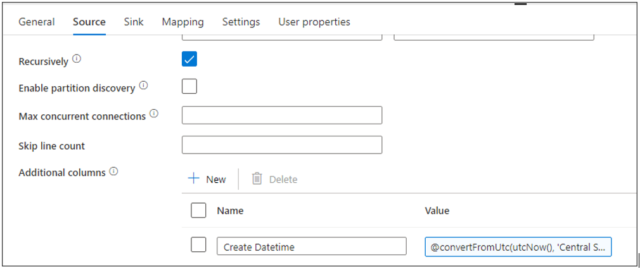
Using Mapping tab, I can map the new column to any existing column in destination table, if needed.
Hi,
Thanks for you time wrtting the blog.
I’ve one question regarding the copy activity. Once you have used the filter activity to get the list of file you need, do you save this anywhere?
I’m not sure what to put in the source dataset in the copy activity, because if I put the folder that contains filtered files, it also contains the other files.
Thanks and regards
Hi Miquel,
No, you don’t need to save it. “Filter” output is an array, and it will pass on to your next activity.