
Let’s suppose we have millions of records that need to be migrated from one system to another. In this case, we can use batch processing in MuleSoft.
An Overview of Batch Processing
Unlike other ways of processing records in batches, a batch job is asynchronous and uses parallel processing with fine-grained control over error handling. Below I will discuss the basic concepts of batch processing in MuleSoft 4.
The input for batch jobs should be a collection. Batch jobs break the data into individual records, perform actions on each record, and process each record asynchronously. It saves each record in persistent storage. In case the job crashes, it will resume from where it stopped and report on the result.
Here is an example of a batch job in MuleSoft, which will read files and process records in batches and insert records in the database:
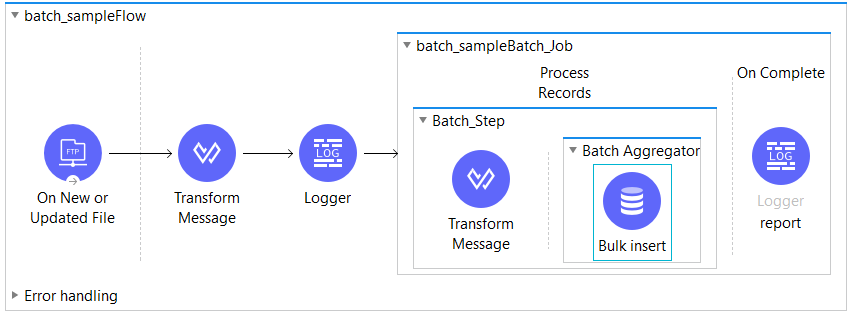
Batch Job Configuration and Batch Job Instance
A batch job is a scope that is comprised of three separate phases. These phases are load and dispatch phase, process phase, and on complete phase.
Batch job instance is generated during the load and dispatch phase. The ID represents an executive instance of a batch job and is stored in a persistent object store. The batch instance ID is associated with the persistent queue that also gets created in the load and dispatch phase.
The snippet below refers to batch job configuration as shown in Anypoint Studio:
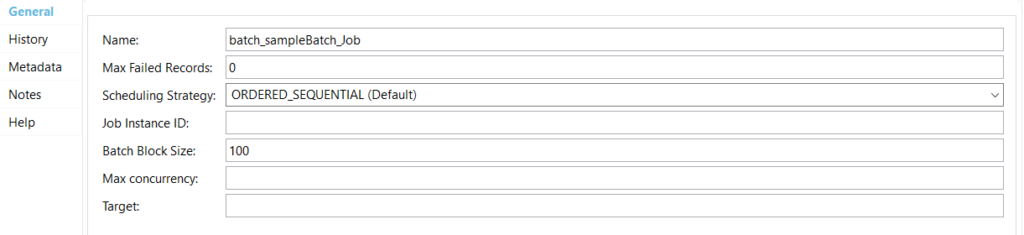
Max failed records show the number of failed records that should be allowed. By default, it is 0, which means no failed records will be allowed. In other words, it means no failure will be allowed.
Suppose you are processing a few records and you have set the failed records to 0. In case a failure occurs in Step 1, as we are processing thousands of records and it fails, it will continue to process these records, but it will skip the other steps. It won’t execute the remaining steps so all records will go to Step 1 and it will directly move on to the on complete phase.
If set to -1, it will continue with the other steps even though the failure occurred; you may be able to handle the failures in other steps.
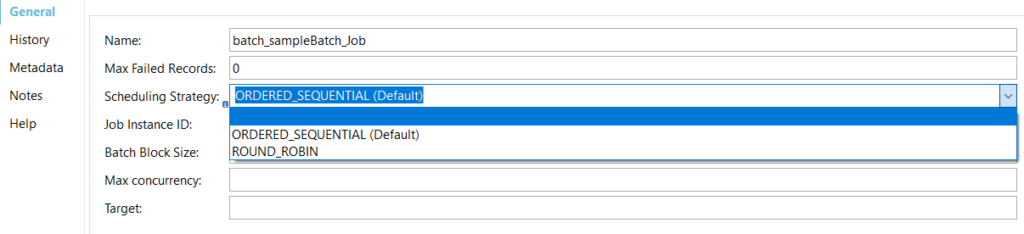
Scheduling Strategy: There may be multiple batch job instances that are in an executable state to reduce the computing resources so we can have a scheduling strategy. By default, it is ordered sequentially, which means that whichever comes first will get executed first, or you can use the round-robin scheduling strategy and it will work on a time-sharing basis.
By default, the batch block size is 100. In the load and dispatch phase, a persistent queue is generated and the records are persisted to this queue. Next, let’s assume we have four records in a queue, and the batch block size is set to 2, which means we have a batch job that has two steps.
Once the queue is populated in the process phase, it will take two records at a time and load them into the memory and start processing to get an IO operation. Using this IO operation, the records will move to the batch steps and they’ll get processed, pushed back to the queue again, and move onto Step 2. Subsequently, it goes to the next set of records. So the batch block size effectively tells the number of IO operations that are required for loading the records into the memory and then processing it. If you keep the record low, the batch block size will be low and there will be an increased number of IO operations. If it is on the higher side, the number of IO operations is reduced.
Max Concurrency is the parallelism that we want. By default, MuleSoft comes with two multiplied by the number of cores. If we have four core CPUs multiplied by two, it becomes eight; if it is hyper-threaded, it is double that.
Batch Steps Configuration

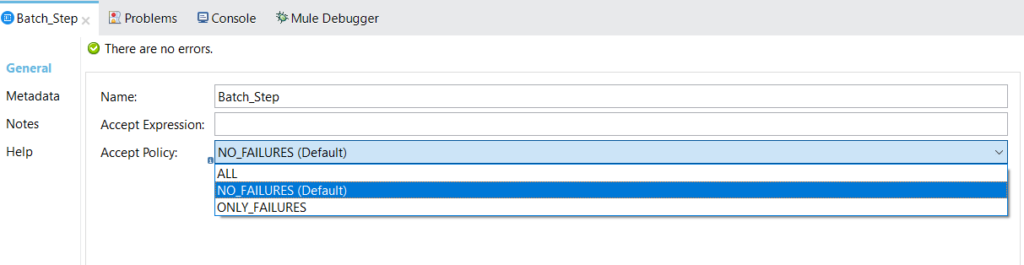
A batch step has the following configuration:
Name: The name you want to be displayed in the UI.
Accept expression: It will have the data of the expression, which when evaluated to true will allow the record to enter a particular batch step.
Accept policy: This will have three options: no failures, all, and only failures.
No failures are the default behavior if you do not want any failed records entering your batch steps. If you want all types of records – successful as well as failed records – to enter your batch step, you can choose all. If you want to handle only failures, you can choose only failures.
Make sure that you make the max failed records a value that you are comfortable with or make it -1, which means that it will allow all the failed records.
Batch Aggregator
This is an optional scope. Let’s suppose you want to push data to a database, and you can have a database inserted in the processing stage, but imagine there are 1000 records being processed. In this case, you can do a bulk insert and that’s where the batch aggregator comes into the picture.
Aggregator size and streaming: These two values are mutually exclusive, which means that you cannot fix the size of the aggregate along with streaming; either of these can be enabled at a time.
Aggregated size: You can hardcode the aggregate size and it becomes a fixed size aggregator, which means that if you put 1000, once the 1000 records are processed in Step 1 they will be collected in a batch aggregator. The payload will be available in a form of collection that, if it is a JSON, it’s an array and you can push the data to the database.
Streaming: If you are transforming data and want to push the data to some files, it’s a good idea to use streaming. In this case, the data will be streamed to the file. However, one of the major drawbacks of using a stream is that it is nonrepeatable. It’s a forward-only iterator.
Batch Processing Phases
As mentioned above, batch processing has three different phases. In this part, I will give more detail on the topic.
Load and dispatch phase:
This is an implicit phase and cannot be visible in the pallet. Data will be loaded in the persistent queue and the thread pool will be generated, where the thread will be two multiplied by the number of CPU cores.
Below are the steps that will be performed during this phase:
- Split the message, and the new batch job instance will be created.
- The persistent queue will be created and associated with the new batch job instance. We can see the queue in the runtime manager.
- For each record split from the message, MuleSoft will create an entry in the queue that contains two parts of data and metadata.
- Process all queued-up records and proceed to the first batch step.
Process phase:
The process phase includes the batch steps. It can include multiple batch steps and again the batch step is divided into two sections: the processing section and the aggregating section. The aggregating section itself is a scope that doesn’t have multiple phases. Steps are executed in sequential order for each record.
Below are the steps executed in this phase:
- The record moves through the processors in the first batch step and is sent back to the original queue while it waits to be processed. By the next batch step, metadata containing batch steps details what is completed.
- Repeat this procedure until every record has passed through every batch step.
- The records are picked out of the queue for each batch step, processed, and then sent back to the queue. Each record keeps track of the stages processed while it sits on this queue.
- MuleSoft keeps track of all records as they succeed or fail to process through each batch step.
On complete phase:
This section is optional and only executes when batch steps are executed for all the incoming records. This is mostly used to provide reports of batch processing. For example, total records processed, failed, successfully processed, etc. In this phase, MuleSoft updates the payload with batch job state values.
We get a batch result object that contains the number of successful records, failed records, and we find out the steps in which the records have failed. For reporting purposes, you can create a data view, get the details, and trigger an email notification or push it to another database.
If you need to migrate thousands of records from one system to another, the batch processing capability of MuleSoft 4 can help you automate the process with a few easy steps. Batch processing can help reduce the number of failed records your development team needs to handle manually.
Contact us to learn more about what you can do with MuleSoft.
Resources and references:
https://docs.mulesoft.com/mule-runtime/4.3/batch-processing-concept