In typical Migration Projects, data housed in Database Server A (provided by Vendor A) is extracted, transformed, and loaded into Database Server B (produced by Vendor B). Each of these servers offers a wide array of functions to query data. Though the function names and syntaxes may vary, all the DB servers in the market provide maximum querying power and flexibility.
A block of code is written comprising of many functions to perform an operation. Assume that in Server A, the action (Z1) can be performed by a combination of functions (x1,y1…). When migrating the code to Server B, we would usually be tempted to first find similar replacement functions (x2,y2…), which can then be put together to perform operation Z2. But by doing so, in many cases, we might not be able to reproduce the desired solution and consequently run into a dead-end.
Z1(x1+y1… ) ≠ Z2 (x2+y2…)
Instead, our aim must be to perform a top-down approach wherein we have to analyze Operation Z1 and visualize operation Z2. Then find functions (i1,j1…) specific to Server B which can, when put together, perform Z2
Z1(x1+y1… ) = Z2 (a2+b2…)
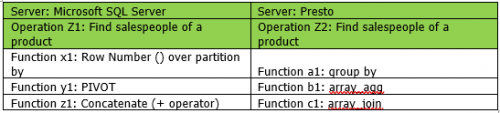
Use case: Microsoft SQL server
Let’s assume a sample of the Products table in the Microsoft SQL Server.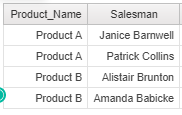 There are 2 Products, A and B, sold by 2 people each. Suppose that we want the list of sales-people for each product (separated by ‘;’). This can be achieved using the below SQL code.
There are 2 Products, A and B, sold by 2 people each. Suppose that we want the list of sales-people for each product (separated by ‘;’). This can be achieved using the below SQL code.
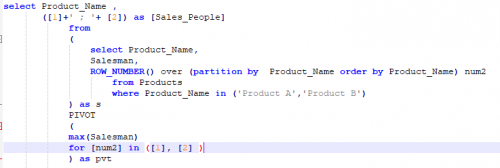

The code could be logically broken down into blocks of code as below:
- ROW_NUMBER() over (partition by): This function assigns a unique row number for each row within each partition. The partition here happens by Product_Name (logically equivalent to grouping)
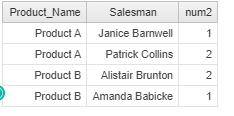
- PIVOT – Pivoting the result based on Salesman for num2, whereby rows become columns.
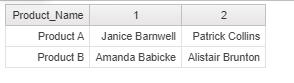
- Concatenate : Use + operator and delimiter to concatenate: ([1]+’ ; ‘+ [2]) as [Sales_People]
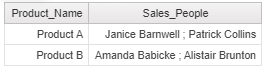
Note that the above code considers only a case where num 2 in (1,2). For situations where products have more than 2 Salespersons, the above system must be expanded to include all possible scenarios.
Conversion Use case: Presto
The above code in the SQL server could be converted into a code supported by Presto, as given below. It produces the same results as the SQL server code.

The code could be logically broken down into blocks of code as below:
- Group by: The rows are grouped by – based on Product_Name.
- Array_agg: An array is created with Salesman for each group
- Array_join: The array elements are joined using the ‘;’ operator.
Note that this can handle any length of Array in the X dimension.
To summarize, we could say that a top-down approach is more-effective in migrating queries. Whereby, the final functionality of a code Z1 is analyzed and then broken down into functions necessary to perform the last operation.