
Understand Data Warehouse, Data Lake and Data Vault and their specific test principles.
This blog tries to throw light on the terminologies data warehouse, data lake and data vault. It will give insight on their advantages, differences and upon the testing principles involved in each of these data modeling methodologies.
Let us begin with data warehouse.
What is Data Warehouse?
A data warehouse is a central repository of integrated data from one or more various sources. They store current and historical data in one place that are used for creating analytical reports for workers throughout the firm.
The data stored in the warehouse is sourced from the various operational data sources(ODS) which means that it can be sourced from heterogeneous systems and usually require data cleansing for additional operations to ensure quality of data before it is used in the DW for reporting.
The typical Extract, transform, load (ETL)-based data warehouse has staging, data integration, and access layers . The staging layer or staging database stores raw data extracted from each of the different source data systems. The integration layer integrates the different data sets by transforming the data from the staging layer often storing this transformed data in an ODS database. The integrated data are then moved to another database, often called the business warehouse database, where the data is arranged into classified groups, often called dimensions, and into facts and aggregate facts. The combination of both fact and dimension table is called a star schema. The Reporting layer helps users retrieve data.
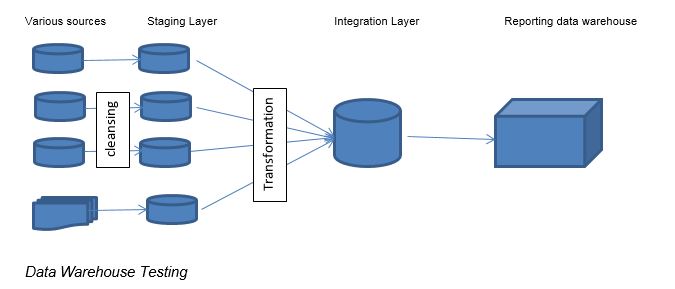
A data warehouse is a consolidated, organized and Structured repository for storing data. ETL testing essentially involves the verification and validation of data passing through an ETL channel. After all, if the data that ends up in the target systems is not precise, the reporting and certainly the business decisions can end up being incorrect.
The complexity and criticality of data warehouse testing projects is growing swiftly each day. Data warehouses need to be validated for functionality, quality, integrity, accessibility, scalability and security based on the defined business requirements by an organization.
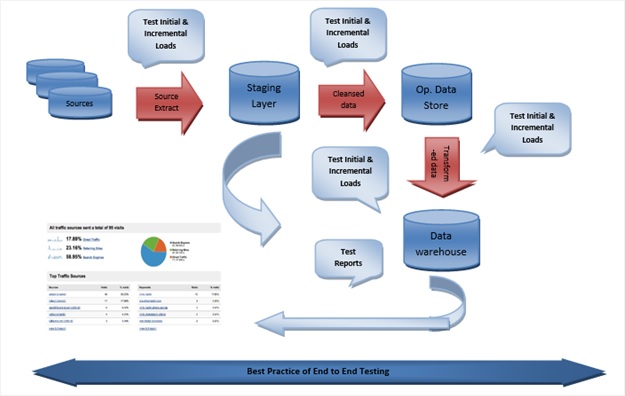
Some of the best practices for ETL testing:
- Ensure that the data has been transformed and loaded properly.
- Data should be loaded into the warehouse without any truncation or data loss.
- Ensure that ETL application appropriately rejects and replaces with default values and reports exceptional data that are not valid
- Confirm scalability and performance by ensuring that data had been loaded within the given time frame.
Some of the issues in ETL testing include:
- Data validation
- Constraint validation: ensuring the limitations for tables are properly defined
- Data completeness: checking all the data has been loaded as expected
- Data correctness: making sure the data has been accurately verified
- Validating dates
- Data cleanliness: removing unnecessary columns
Let’s now move on to data lake

What is Data Lake?
A data lake is usually a single place of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, analytics and machine learning. A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video).
 Data Lake Testing
Data Lake Testing
The four testing approaches:
- Migration testing: In the case of migration testing, data from the source is compared with the target to ensure that all data are loaded to data lake. Data quality and conception testing are also performed on the target database.
- End-to-end testing: The trends in big data implementations focus on creating new data lakes / data hubs, with big data replacing existing data warehouse systems to store data in different regions for easy recovery. Such executions require different testing methods.
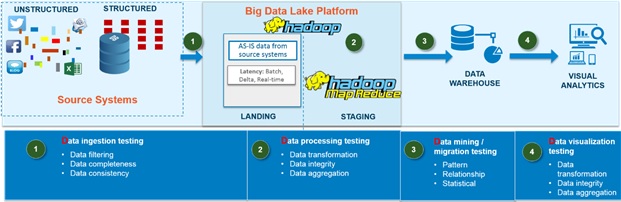
In fact, the complete data lake implementations require the following four testing approaches:
- Data ingestion testing: Data from various sources, like social media, web logs (unstructured), and sourcing systems like RDBMS (structured), are validated for transformation, format changes, masking, etc., to ensure that the right data is getting ingested into the data lake. As a result, data will be validated at every phase of data ingestion
- Data processing testing: Data quality analysis is the second test step to be followed to ensure data integrity and to validate business transformation rules. This needs to be performed in the big data, once the data is moved from the source systems
- Data mining testing: Data available in data lakes will be retrieved based on specific business logic to ensure that the right data is filtered and made accessible for other data stores or relational databases. This takes care of validating the transformation query logic
- Data visualization testing: Reports and visualization testing is related to end users, where output is validated against actual business user stories and design. Reports are the basics for many decisions but are also the critical components of the control framework of the organization. As a result, reports, dashboards, and mobile outputs are verified and validated
- Reports testing: In this kind of testing, reports which get data from data warehouses are modified to get data from big data backend stores. Two validations are performed: Comparison of data getting displayed in reports versus data available in big data. Reports are visually compared or validated against a predefined format or template designed by users or architects
- Data archival testing: This kind of testing is seen in rare and mainly big data stores used for storing data for audit and compliance purposes. The data is not processed and is stored ‘as is’ to ensure that it can be recovered easily. The validation approach involves source-to-target reconciliation, where data is validated from source databases with target big data stores.
What is Data Vault?
Data Vault Definition
A data vault is a system made up of a model, methodology and architecture that is explicitly designed to solve a complete business problem as requirements change.
Data Vault data is generally RAW data sets. So, in the case of the Data Vault, reconciling to the source system is a recommended for testing. This can be reconciling to the flat-files that arrive or comparing to the source databases. Sometimes there is no “system” to reconcile, because the data arrives on a web service. In this case, would suggest storing the data in a staging layer.
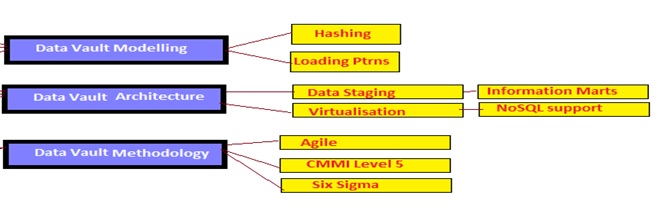 These are characteristics of DATA Vault modeling which separates it from other approaches
These are characteristics of DATA Vault modeling which separates it from other approaches
It serves to structure the data warehouse data as systems of permanent records, and to absorb structural changes without requiring any alterations
Data Vault requires to load data exactly as it exists in the source system. No edits, no changes, no application of business rules (including data cleansing). This ensures that Data Vault is 100% auditable.
If the data is altered on the way into the Data Vault, it breaks the ability to trace the data to the source in case of an audit because we cannot match the data warehouse data to source data. EDW (Enterprise Data Warehouse) is the enterprise store for historical data too. Once the data is removed from the source systems, the EDW may also be the Source of Record. So, it is critical the data remain clean.
The process of building a Data Vault in 5 simple steps.
Step 1: Establish the Business Keys/Hash keys, Hubs
Step 2: Establish the relationships between the Business Keys/Hash keys, Links
Step 3: Establish description around the Business Keys/ Hash keys, Satellites
Step 4: Add Standalone objects like Calendars and code/descriptions for decoding in Data Marts
Step 5: Tune for query optimization and add performance tables such as Point-In-Time structures
Testing with an Empty Data Vault, followed by Initial Single Day load, followed again by a Second day load is a must. A Day-2 Load will allow you test Delta/Incremental data, and duplicate removal from the staging area. General testing strategy best suits for any Data Vault adopted projects. However, by using raw Data Vault loads we can confine transformations to a minimum level in the entire ETL process through “Permissible Load Errors”.
ETL/Data Warehouse Testing should highlight on:
- Data quality of Source Systems
- Data Reconciliation between Source and Target
- Performance/Scalability/Upgrade issues of BI Reports
Following are the prominent 5 proposals to execute tests for a Data Vault – ETL/DWH project to adhere the above baseline pointers:
- Design a small – static test database derived from the actual data to run the tests quickly and expected results can be identified in the former stage.
- Early execution of system testing to ensure the connecting boxes in ETLs interface.
- Engage Business users while generating and deriving the real data to a small test database to ensure the data profiling and data quality.
- Simulate the test environment as is of the Production to cut down the cost issues.
- Execute the ETLs, capture logs and validate all the data flows (Bad/Rejected/Valid/Negative)
We can summarize the differences as shown
| Attribute | Data Warehouse | Data Lake | Data Vault |
| Define in a line | Stores the truth | Stores all kind of data | Stores the facts |
| ETL Involved | Yes | No | No |
| Source | Disparate (But cleansing is done) | Disparate | Disparate (But only for a particular business scenario) |
| Security | High | Low | Medium |
| Flexibility (in terms of data quality) | Low | High | Medium |
| Flexibility (in terms of usage) | Medium | High | High |
| Data Quality involved | Yes | No | No |
| Support for unstructured data | No | Yes | No |
| Key Testing principle | Data correctness | Data volume and variety of source support | Data availability |
| Advantages | Reliable
Secure Good performance |
Vast support
High availability Huge volume |
Flexible
Scalable |