
We have been familiar with machine learning for several years. It has been used in many aspects of business and life such as natural language recognition, fraud detection and autopiloting. While deep learning is a branch of machine learning, it is a big part of the machine learning family based on data representation other than task-specific learning. Intel has open sourced its deep learning framework that is built upon Spark cluster nodes and computation engine.
The deep learning algorithm aims to build the model of abstractions in data. It could be based on artificial neural network topologies and can scale with larger data sets. And the learning can be supervised, partially supervised or unsupervised.
There is a simple flow to show the basic steps to extract a dog feature via the deep learning toolkit. Deep learning introduces more depth by creating a pipeline of feature extractors in the training model. It will increase the overall prediction accuracy of the resulting model through hierarchical feature extraction.
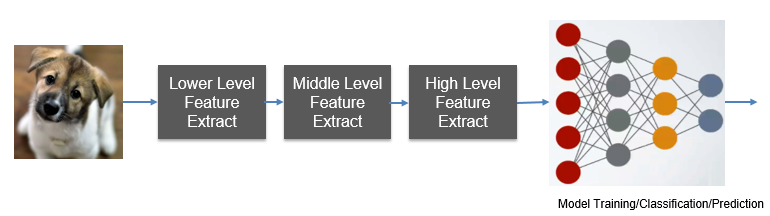
“Neural network” is not a new term and you probably learned it decades ago. The limitation to the AI evolvement in the past is a lack of sufficient data and powerful computation. In my previous blog entries, I introduced Spark, which is an in-memory distributed engine written in Scala. Hence, combined with Spark, the deep learning algorithm has shown its power in business use case utilization.
If you are a Spark practitioner, you should be pretty familiar with the following architecture where several components such as Spark SQL, Spark Streaming, Spark R, MLLib, GraphX are built on Spark Core. Now BigDL joins them in the structure. It is interesting that MLLib is provided by the Spark targeting for machine learning and provides more options for the user with BigDL.
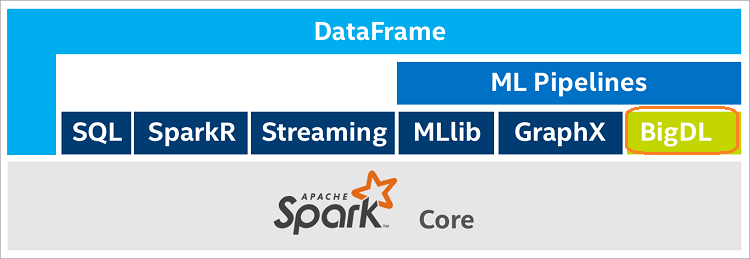

(The graph is from Intel Software Developer Zone}
In the BigDL, the optimized learning algorithms of Neon, Caffe, TensorFlow, Torch, Theano were added into the library for developers to use. Caffe and TensorFlow are popular in the machine learning field, so we will talk a little about them.
Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR) and by community contributors.
TensorFlow™ is an open source software library from Google. It is for numerical computation using data flow graphs. It has been adopted by many start-up companies who are focused on Artificial Intelligence applications and business development.
What features & advantages does BigDL bring to the community?
1. As mentioned above, it provides plenty of deep learning modules;
2. It seamlessly integrates with Spark and Hadoop, and has the ability to tackle distributed and huge data volume;
3. Cost-effective. This is open source and provides many options for the user to customize. If the enterprise already has a Spark cluster, you can just add the BigDL to that cluster;
4. Scalability. It is easy to scale up or down on the nodes;
5. The deep learning algorithm has been optimized and applies multithreaded programming in each Spark task, so it speeds up out-of-the-box open source Caffe, Torch, or TensorFlow on a single-node.
Just go to https://github.com/intel-analytics/BigDL to check out the installation and other useful tutorials.