Here, we’ll cover the ability to use ODI for one its basic features: extracting data from Essbase and using the exported file to load to a table. It turns out that ODI was not recognizing the file generated by Essbase. Let’s see what we were missing:
We have a calc script exporting level 0 data from an Essbase cube. We were using Dataexport command in the calculation script to export the data from Essbase BSO cube. In ODI, while building the file datastore, we placed a sample file at the desired location. The exported file from Essbase was a comma delimited file. We built a model to the file location and then a datastore. We reverse engineered the columns by using a sample of exported file.


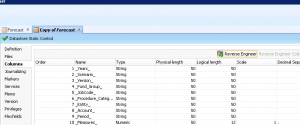

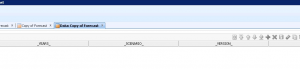
Even though we were able to reverse engineer the columns successfully when we tried to pull data / view data from the datastore, the result was a blank.

The view data always resulted in a blank output as shown. It did not generate any error message.
It turns out the record separator in file generated from Essbase uses a Unix record separator which is easy enough for a Windows user like me to miss. (Just mind you – file looks perfectly normal when you open it in Notepad++ or Word or excel since MS office converts the file when you open it. And ODI doesn’t generate any error message – So quite easy to miss)
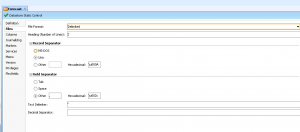
As soon as we changed the record separator to Unix, Voila- It all started working as expected. The file was pulling data just fine. And we didn’t have to reverse engineer the columns again either.