
Structure of Hadoop
- HDFS (Hadoop distributed file system) is going to distribute our data across nodes depending upon the replication factor configured.
- Since data needs to be distributed across systems, all the systems are established with an ssh connection by the software installed in it and it uses tcp protocol.
- Since data is distributed, there should be a place in the process to determine where its data is available. Those processes are taken care by the name node.
- When a file is given to the client to process, the client contacts the name node and the name node returns the Data node and the block it can use to store that file.
- The client can now contact the appropriate data node and it will store the file in blocks. Depending on the replica factor, the data node will pass the data to the next data node.

6. Once all of the data is written to the necessary blocks, the client node closes the connection and the name node will have the entry in the namespace that this file is stored in this data node and in this block.

The Future of Big Data
With some guidance, you can craft a data platform that is right for your organization’s needs and gets the most return from your data capital.
7. Every data node will report frequently to the name node with a health check such as how much memory or blocks are available, CPU utilization, throughput and so on.
8. If the client needs to run a process by using the file stored, it will get the data node and the block location from the name node and it will contact the appropriate data node, the data node in-turn will provide the data. The containers will be given for processing by the appropriate application master. If containers can’t get it in same node, it will check whether any node container is free in that rack. If the container is not available in the rack it will check whether the available container in that data centre is in different rack. If it is not available it will check for a different data centre.
9. In most cases it will end up in the same data node or in the same rack where the data node is available and depending on the block size number of the map and reduce task will be created.
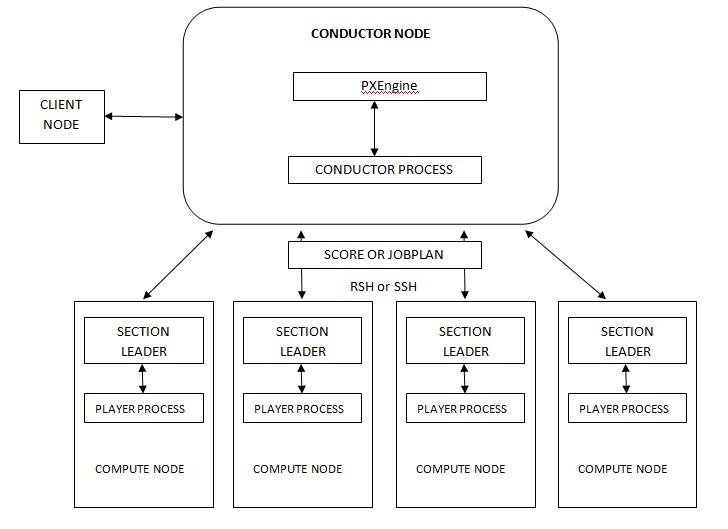
Structure of ETL
- The conductor node can connect to all the compute nodes since SSH or RSH connection would have been established through tcp protocol.
- In most of the cases the software will be installed in conductor node and all its binaries will be copied to compute node and most probably only project directories will be cross mounted across compute nodes.
- So now compute node can act as a slave to conductor node it can execute whatever the conductor need to process. Since the project/code is cross mounted it can open the job whichever conductor node asks and execute for those record which is given by conductor node since all the binaries is also available.
- Depending upon the configuration number of compute nodes will be assigned for each process and once processing is done the conductor will take care of regrouping the data.
- Each compute node can’t interact with each other in this structure. The compute node will be used only for processing.
- The throughput, I/O, latency of compute nodes are not captured by the conductor node it will just split the data to the compute node depends upon the configuration. But the latest ETL processes they have include balance optimizer.
Hadoop vs ETL (Datastage)
- Hadoop uses HDFS so that it can use all the file systems of a data node in one umbrella. Whereas the ETL process it will use only conductor nodes file system.
- Since the file comes in one umbrella large files can be stored easily in blocks and access it easily. But in ETL process if you are going to get large file and your conductor node only save less than then there is only one way you need to increase file system space we can’t use the space available in compute nodes.
- In Hadoop if one node is not performing well automatically name node will assign different node since it knows about it. But in ETL process if it is configured to run on that node which is not performing well we can’t stop it.
- Since data are stored in data node only the processing need happen there in hadoop structure. But in ETL process the data need to virtually send to the compute nodes and then the processing should happen.
- Since Data node can communicate each other while loading data according to the replica it will sequentially load the packets to the next data node without waiting for the data to come from client. In ETL only the conductor node will have the data but the data load time will more probably similar to hadoop.
- If name node goes down any one of the data node can act as name node and this will ensure high availability always even during DR since data centre will be in different place. In ETL if conductor goes down we would have gone with whole server down or we would configure secondary node and DR node with the same configuration of conductor node and we need have that available all the time.
- In Hadoop regrouping the data is easy since most of the part is taken care by HDFS and mostly processing is going to take care in the same node/rack. In ETL we need to regroup the data after processing from the compute node completes.
- Since all the backend codes are return in java any unix/linux machine will support hadoop. But for ETL tools it should be high configured server.
- Hadoop performance will be good on unstructured data since it doesn’t need any normalization back of it, If data is normalized this structure is going to have performance issues. ETL process will give good performance in normalized data since we have one processing area where we can do all type of join and groups supported by rdbms database.

