VisualDxHealth is a website that provides pictures and text information on skin and visual diseases. The site is meant to be a resource to help people identify or better understand a skin problem affecting them or a family member. The site was first made live in January 2007 and officially launched in April 2007 (OK, so maybe the site isn’t “old”, but hey, it’s an article series!).
In May of 2007, Perficient Digital started working with the company (Logical Images is the publisher of the site) to implement an SEO plan to grow the site’s traffic. In this case study, we will outline a bit about where the site was when we started, what we did, and the results (greater than a 4.5x gain in traffic!).
When we first looked at the site we found a high-quality site that had a lot to offer from an end user perspective. The general navigation was good, the content rich, and the overall value to end users was already high. The Logical Images team had already done an excellent job of putting together a great site. So what were the problems?
Challenges and Solution Summary
1. Unique Content:
- Based on how VisualDxHealth was initially architected, duplicate content existed in many forms on the site. This issue ranged from common missteps such as not implementing canonical redirects to more site-specific issues related to how VisualDxHealth was serving up images. At the most fundamental level, canonical redirects relate to how different URLs resolve.
Both http://visualdxhealth.com and http://www.visualdxhealth.com resolved separately and showed the same home page. This is a well known duplicate content problem where the search engines can find both URLs for the home page of the site, and considers them different pages that are copies of each other. The same holds true for all pages on the site (e.g., http://visualdxhealth.com/someotherpage.html was seen as a duplicate of http://www.visualdxhealth.com/someotherpage.html)
In addition to this common problem, the site also had duplicate content at www.visualdxhealth.net and visualdxhealth.net. From a marketing perspective, this makes a lot of sense. It’s actually very smart to lock up common variants of your domain to prevent them from being usurped by domain squatters. Unfortunately, this technique also creates additional duplicate content — the same pages can be seen at multiple URLs.
The real problem here is that external links get divided up among the “www” version of your site, the “non-www” version of your site, and any other variants (such as the “.net” version of your site). Usually, more go to the “www” version of your site, and therefore the external links to the other versions of the site provide no SEO value.
Want to pick up some fast links? – implement a “canonical redirect”. If you have an Apache web server, you can see canonical redirect instructions here.
You should also set the preferred domain to be your full, canonical domain (usually the www form of your domain) in Google Webmaster Tools to help Google better understand your preferences.
- A closely related problem is the default document duplicate content problem. You can read about this problem in more detail here. The short summary is that the home page of the site at http://www.visualdxhealth.com was also accessible at http://www.visualdxhealth.com/index.html. This is in fact quite common.
The web server needs to know what file to open when you go to the home page. In the case of the VisualDxHealth site, this was the document “index.html”. The problem that arises in many CMS systems is that they refer to the home page using the default document name. Such was the case on this site, so the internal links back to the home page linked to: http://www.visualdxhealth.com/index.html.
Just as with the canonical problem above, this is seen as duplicate content. Worse still, all the internal link power of the site links to the version of the page that the search engines will ignore (largely because most of the rest of the world links to the URL for the home page that does not include the default document name.
The solution here is also simple – tweak the code for your site, or your CMS, to link to your site without the default document name (e.g. http://www.yourdomain.com).
- Next up, we found that the site had different navigation trees to show the various diseases for adults, teens, and children, as well as versions for males and females. This is important from an end user perspective because often times the manifestation of the disease is different based on the person’s age or gender.
However, those differences were reflected primarily in the images shown, and not in the text on the page. In addition, the meta descriptions were normally the same on these pages as well. As a result, there was no distinction visible to the search engine crawler between the various versions of the pages. So once again, we had duplicate content.
The solution was to implement additional content on all the pages to differentiate the pages in the search engine crawler visible text. This included the user-visible content and the meta description tags.
- There was even more duplicate content to be found. The site would cross-link to pages on the site using strings of parameters. Here is an example of what it looked like:

http://www.visualdxhealth.com/adult/poisonIvyDermatitis.htm?st=Male_1244,1249,1271, 1248,23517,1247,1246
The parameters were used to tell the web application which images to show to the end user based on which page the user was coming from. Here is an example of what one of the VisualDxHealth pages looks like:
 |
The result of this approach was that the site internally linked to the same URL many times, but with different parameters to display different images. Once again, we had a situation where the search engine crawler saw multiple pages with the same content because the only differences between the pages was the set of images loaded.
To resolve this issue, we worked closely with the development staff, and came up with a functionally equivalent solution that used cookies, instead of URL parameters, to carry the image selection information. With this approach, all links to a given page used the same URL, and the duplicate content problem was resolved.
For this problem, the solution was either to restrict each page to a fixed image set, or if it was different enough, to move it to a different actual URL and make sure that the text elements of the page talked about the unique aspects of the page. Of course, we 301 redirected the old retired URLs to the new ones.
2. Internal Linking With Images:
Many of the pages on the site used images for their links instead of text links. This is really a lost opportunity because on-site anchor text is very, very powerful. The anchor text informs the search engine what a page is about.
However, images can be very valuable in communicating to users, so the solution did not involve removing the images and replacing them with text. What we did here was implement text links that also serve as captions for the image. Using a slice of the home page, here is an example of what we are talking about:
 |
3. Missing alt attributes on images:
As we have said already, search engines can’t identify the content within an image. One thing that you can do to tell a search engine a bit about what is in the image is to make use of the alt attribute. When we first began working with the VisualDxHealth site, few of the images on the site had any alt attributes associated with them.
We implemented the alt attributes with good descriptive text. For example:
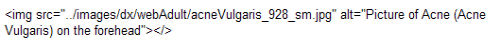 |
4. Not enough inbound links:
When we began working with Logical Images the VisualDxHealth site had 168 external links to the domain. We worked closely with Logical Images to promote the site. We implemented programs to get links from colleges and universities, major health industry bloggers, and many other related sites.
Our expertise in these campaigns is identifying and packaging valuable content, and finding creative means of reaching out to webmasters who might be interested. For example, Logical Images highlighted MRSA as a “hot topic” for students and their families, and we were able to develop campaigns that resulted in links from the health departments of colleges and universities, and from numerous grade school web sites.
Logical Images also succeeded in getting the attention of several national institutions and sites that could provide value to their visitors by linking to the content and information presented on the VisualDxHealth site. We worked with Logical Images to make sure that these links were implemented in clean HTML text, and linked to the most relevant pages on the VisualDxHealth site.
As a result of these campaigns, the inbound link count went from 168 to 1030. Given the richness of content for this site, there remain many, many opportunities for additional link building. We have a number of campaigns underway now to gain additional high-quality links.
The Results
This remains a work in progress, but the results are already excellent. Here is a snapshot:
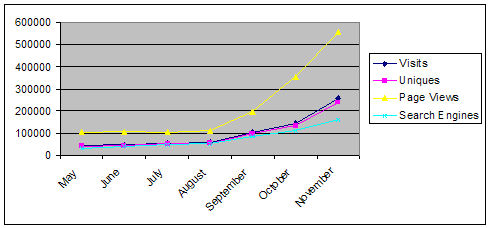 |
The charts show an overall growth of traffic for November over May of more than 5 X. Look a little deeper to see the numbers for traffic (visits) directly from search engines (the light blue line). That’s more than a 450% growth in search engine referrals, from about 34,000 to about 160,000!
Needless to say, we are all pleased with the results. One of the major projects that we remain focused on is further growing the quality inbound links into the site. We don’t buy links or implement reciprocal linking campaigns. The focus is entirely on exposing the high-quality content of the site to those webmasters who would be interested in it. The other area of focus is the development of more text related content on the site.