
Rand Fishkin

Ben Hendrickson

Nick Gerner
Rand Fishkin is the CEO & Co-Founder of SEOmoz, a leader in the field of search engine optimization tools, resources & community. In 2009, he co-authored the Art of SEO from O’Reilly Media and was named among the 30 Best Young Tech Entrepreneurs Under 30 by BusinessWeek. Rand has been written about it in The Seattle Times, Newsweek and the NY Times among others and keynoted conferences on search around the world. He’s particularly passionate about the SEOmoz blog, read by tens of thousands of search professionals each day. In his minuscule spare time, Rand enjoys the company of his amazing wife, Geraldine.
Ben Hendrickson graduated from the Computer Science Department at the University of Washington, he then rather enjoyed being a developer at Microsoft, although not quite as much as his current position serving the SEOmoz corporation. Nick Gerner leads SEOmoz API development and worked on solutions for historical Linkscape data tracking prior to leaving SEOmoz about 1 month ago.
Interview Transcript

Eric Enge: Can you provide an overview of what Linkscape is, for the readers who aren’t familiar with you all and what you have been developing?
Rand Fishkin: Linkscape is an index of the World Wide Web, built by crawling tens of billions of pages and building metrics from that data. The information Linkscape provides is something webmasters have cared about and wanted to see but search engines have been reluctant to expose.
Linkscape is a way to understand how links impact a website and how they impact the rankings given by search engines. Our aim is to expose the data in two formats. One for advanced users to perform some of the complicated analyses they have longed to do but couldn’t, and a second to provide simple recommendations and advice to webmasters who don’t necessarily need to learn the ins and outs of how metrics are calculated.
Ultimately Linkscape will provide actionable recommendations that go beyond raw data to explain a site’s ranking and the rankings of competitors. It routes the source of the links and shows a user who is linking to a competitor, but could link to them. Our tools also expose which links are more useful and which ones are less so.
Eric Enge: One interesting aspect of your tools is that in addition to collecting a large dataset of pages and links across the web, you do your own calculations to approximate trust value and rank value as in mozRank or mozTrust. Can you talk a little bit about that?
Rand Fishkin: For those who are interested in the technical details and methodologies, the patent applications are now available. For the less technical webmaster, mozRank is a way to think about raw popularity in terms of how many links point to a page and how important those links are and consequently how important that page is. It leverages the classic PageRank concept.
MozTrust similarly asks the same question, but with a trust base bias. Instead of analyzing how important the page is among all other pages on the web, it looks at how important the page is to other trustworthy websites and pages. The link graph is biased to discount what mikes-house-of-viagra.info thinks and focuses instead on how sites such as WhiteHouse.gov, NASA, smithsonian.org, and Loc.gov (the Library of Congress) regard the page. They are powerful metrics to analyze how trustworthy or how spammy a website or page is.
Eric Enge: The original definition of trustrank was founded on a concept that there was a distance in number of clicks between you and a feed set of websites.
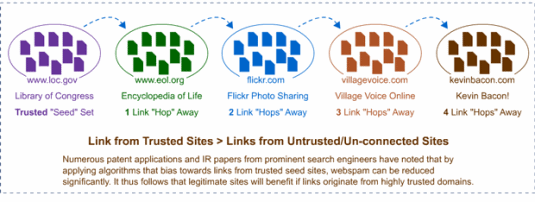 |
Rand Fishkin: Ours is a little more complex than that in the sense that if you are three clicks from one trusted site versus being four clicks from multiple sites, perhaps the guy that is four clicks from multiple trusted site is, in fact, more trusted.
It’s not only the source route but a more complex interaction. It’s similar to the mozRank or PageRank style of the iterative algorithm where the metrics are combined.
Eric Enge: Can you dive into some examples of what Linkscape and its companion product Open Site Explorer can do?
Rand Fishkin: One of my favorite applications is a tool called Link Intersect. Given a site and a few competitors, it shows who links to the competitors, but does not link to the page of interest.
Nick Gerner: Someone can quickly find exactly which links they could easily target to go out and pick up. It also communicates the types of communities in which competitors are engaging. It’s great for a site that’s new in an established community to learn the fundamentals of the community. In addition to high-level market data, it provides information on actual sites in the community and the blogs attracting other players in the field. These are the people that they need to build relationships with or participate within forums and blogs.
It’s similar to any competitive backlinking effort, but with the extra twist of quickly isolating the major communities. It can give a list of targets but it can also be used for link building strategy.
By using the metrics and prioritizing the data, we are indicating not only communities where everyone is engaging but the communities that are the most influential and important targets.
Rand Fishkin: The corollary to this is another powerful tool called Top Pages, which can be seen in Open Site Explorer. When given a website it provides a list of pages that have attracted the highest number of unique linking root domains. It doesn’t only give pages with the highest number of links, it also shows pages with the greatest diversity of people linking to them.
This enables a business to understand how a competitor attained their ranking and links, and what was on their page that attracted the interest and link activity. A site owner can not only see what the competition is doing right but perhaps what they themselves are doing wrong. They can see which pages on their site are attracting the majority of links and which are attracting few. It’s a powerful system for competitive and self-analysis.
Eric Enge: Basically it’s a filter that creates a link dataset for a given site, but it’s easily executable. I would call both examples of Link Analytics. Yahoo has tools that will extract data but the resulting list of links isn’t well-prioritized and there aren’t any additional tools for filtering.
Nick Gerner: Having an index to the web is only part of the story. The larger part is building scenarios and tools that go beyond data pukers. Beyond raw data, Link Analytics provides a site owner with an understanding of what the data means and what they can do to improve their placement. The data we provide is prioritized and has metrics to understand what’s going on that’s placing them where they are.
Rand Fishkin: We have been developing ways to make metrics actionable. PageRank is maybe 5% better than random guessing for ordering the search rankings and mozRank is not much better. They are both interesting metrics and are useful for indexation, but they don’t tell the whole story.
By combining a ton of metrics and knowing the number of unique linking domains a page has as well as the anchor text distribution, mozRank, mozTrust, domain mozRank, and domain mozTrust are able to build models of how important a page is and how able it is to rank against something with x competitiveness, and that goes so far beyond a link graph or calculating metrics, and speaks to the heart of the SEO problem which is how to make pages accessible and have the ability to do keyword research and find pages that can compete for those keywords or build pages that can compete for those keywords. To tackle the problem, the site owner needs to know who their competition is and how to implement a solution.
That’s where domain and page authority are so amazing. They’ve been under the radar but are the best and most correlated) metrics we’ve built for ordering the results.
Ben Hendrickson: When Linkscape first launched, we had a lot of metrics. We made mozRank and mozTrust and we had counts of how many links were of various sorts. There were also some we couldn’t exactly classify and didn’t know how to use them.
We can look at these metrics now, and analyze popular pages. It’s usually more interesting to look at external mozRank than normal mozRank. Typically if the number of unique linking domains is low, but other metrics are high that’s incredibly suspicious. Being able to make even these simple comparisons gives a very complex view of how one could use all of our metrics to look at any given problem.
Our numbers can be used in a holistic fashion to compare two pages. By considering the Page Authority (PA) and Domain Authority (DA), strong inferences can be made.
Nick Gerner: mozRank and mozTrust are technical, very low-level algorithmic measures that do a very specific task which is great. On the other hand, they are not terrifically well packaged for human consumption.
Page Authority and Domain Authority are more closely matched with intuition. Big thinkers in the field look at our product and say it makes sense. To them, mozRank is not that different than PageRank and is not packaged in a way that the user understands. Page Authority and Domain Authority, however, are packaging the data in a consumable and extremely useful way.
Ben Hendrickson: The older tools that provide the number of unique linking domains are rather obsolete because it is easy to determine where that number came from and how to make it higher, or lower. The new numbers are derived from very complex formulas that even if everyone knew them, would be very hard to utilize. The simpler information has a whole lot of value because it’s understandable and usable
Eric Enge: Conceptually, how would you approach an arbitrary search query such as digital cameras to create a simple visual of the top ten results and the metrics driving the Page Authority, Domain Authority, and consequently the ranking?
Rand Fishkin: Linkscape and the tools built on top of it, Open Site Explorer and the Keyword Difficulty Tool, are designed to answer that question. If someone runs a query, they can quickly pull up the list of digital cameras and a list of pages.
 |
Looking at the rankings, there are questions that would be interesting to know but couldn’t be answered before such as if some rank lower because they are less important pages on powerful domains or if a higher ranking is a function of exact match keyword domains with lots of anchor text, or if they obtained their ranking because they are very powerful pages on moderate domains. It would also be useful to know if they have collected links from a number of sources, or a few of exactly the right sources.
Linkscape starts to answer those questions, which speaks to the true question every site owner wants to know which is what they need to do to move up the list.
Eric Enge: You have created a formula for evaluating this?
Rand Fishkin: You are definitely on the phone with two guys who love formulas for solving problems like these. As far as ranking the competitiveness of a keyword, this is exactly what the Keyword Difficulty Tool does. Typically, the process is to look at how many people are bidding in AdWords and how many people are searching for the keyword. Also, knowing how many root domains are ranking for it as opposed to internal pages is important. Those are all second order effects that correlate with competitive rankings, but they don’t answer the question of how a site compares with the competition.
Eric Enge: Your tool is giving a site a sense of where they will get the best results for their efforts. If they have to climb a huge mountain to win on one keyword or could win a different one with significantly less effort even though it may have less total volume, the decision could be quite easy. Difficulty tools often use simpler, and I never used them because they really didn’t tell me what I wanted to know.
Rand Fishkin: It’s frustrating for tool builders to build a Keyword Difficulty Tool that still doesn’t get at the real answer. We could look at toolbar page rank or number of links that come through Yahoo, but we still don’t know how powerful or important those are. To get to that takes building ranking models.
Ben Hendrickson: PA knits together metrics that our Keyword Difficulty Tool is based on in order to figure out how to combine our metrics to be predictive of Google ordering of results. The major missing piece in Page Authority is the keyword features in terms of defining the content on the page.
If in comparing two pages, one ranks higher, and you are trying to determine if the guy outranking has more/better links, Page Authority helps to answer that. If it’s not link strength, it could be an anchor text issue in terms of the anchor text distribution and how well that matches the keyword being analyzed and also on-page features.
Eric Enge: That holds a lot of value because it’s a meaningful metric that the client can get advice on. If they are in position five and want to go to position three, it tells them how big of a move that is which couldn’t be done with the earlier tools. That’s really cool.
Ben Hendrickson: A useful feature of using the Keyword Difficulty Tool is that even though there is a degree of error in our models because we don’t understand Google a hundred percent, it should average out that error.
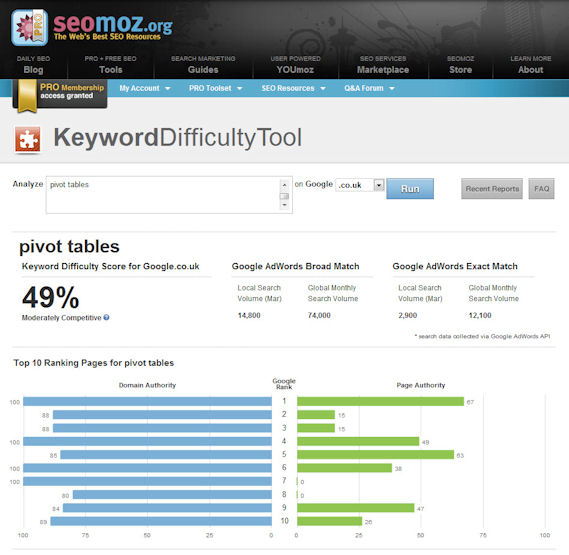
Rand Fishkin: I pulled up the search on digital cameras. It has 91% difficulty which is extremely competitive. I am looking down the accordion chart and I see that the Domain Authority is consistently in the mid to high 90’s for almost all of these sites with one exception, the guy ranking #4. Looking over his Page Authority, I see he has an 88% for Page Authority, so it’s a pretty important page, but still some questionability there. Going down I see that #4 is digitalcamera-hq.com, and it makes sense because all his anchor text to that homepage likely says digital cameras, so it’s not surprising that he is doing so well, and is beating out Amazon.com, and usa.canon.com, and Overstock.com, and Ritz Camera. Clearly, he is winning the battle.
Another case is RitzCamera.com which is at #9. They have a little ways to go in Domain Authority. Their Page Authority is strong, but perhaps anchor text is their weak area. They could focus on getting links to their homepage with the exact match to the anchor text. To boost the Domain Authority, they could add link bait or run a blog or have a UGC portal on the site, or get people creating profiles, and contributing, and linking to lots and lots of different pages on their site.
Using this example of digital camera’s shows how our tool starts to answer the question of how competitive a page is, but more importantly, it sheds light on the missing pieces behind a ranking and what a site can do to fill the gap.
Eric Enge: Given the model that you are creating, have you been applying machine learning techniques to better approximate Google?
Ben Hendrickson: That’s where our authority numbers now come from. When we control for page features, it depends on what you are trying to model at the given time, Domain Authority obviously has fewer inputs than Page Authority (DA only knows the domain you’re on, PA knows the exact page), and we are going to try to model everything. We’re working even now on topic modeling, which we think can help get us a significant step closer to accuracy and prediction.
Nick Gerner: In the search engine ranking factors survey which we do every three years, each feature area is covered by a number of independent low-level features. At a high-level, we cover the number of links, the authority of the links, the trust of the links, and the domain on the page is on, and if there a keyword in the URL. There are ultimately dozens of features.
Ben Hendrickson: We can tell people whether or not the more important factor is the overall domain mozRank or the individual page mozRank.
Eric Enge: Have you done anything in terms of using other trusted datasets to train your algorithms? Rand Fishkin: We did early modeling on datasets from places like Wikipedia, but as we’ve expanded out to the broad web, we’ve been training our rank modeling on Google.com’s search results. We think that’s what most SEOs care about.
Ben Hendrickson: There are issues building tools with external data because these numbers are harder for us to obtain. We haven’t found anything useful enough yet to go out of our way to figure out how to approximate it internally
Rand Fishkin: Getting access to Twitter data either through their fire hose directly or a third party is going to be useful and interesting for us because there is little doubt in my mind that Google is using it in some interesting ways.
Ben Hendrickson: The most interesting one that we have seen was Delicious Bookmarks, but in terms of filling in the gap in our data it wasn’t big enough for us to actually look into how to guess their methodology.
Rand Fishkin: We are all working on showing webmasters and SEOs these metrics because a lot of people still want to know the importance of PageRank, Compete Rank, Alexa Rank, and the number of links via Yahoo. It’s against our core beliefs to not expose that data since we’ve got it, so we are going to make an effort to show people the ability of each of these metrics to predict rankings, and how useful combinations of those metrics are, and Domain Authority, and Page Authority, and ranking modeling.
Eric Enge: Can you outline another interesting scenario?
Rand Fishkin: It’s exciting to see people doing an analysis of links that matter. A lot of people are concerned about which of their campaigns are providing them a return on their investment, whether that’s a public relations campaign, a link acquisition campaign, or even something like a link buying campaign.
People look intently at which links provide value and metrics like Domain Authority, Page Authority, and even mozTrust. With our API or through a CSV, some users are applying Excel to see all their links, their competitor’s links, the domains where the links are from and determine if they are worth getting. They are also able to see if a given link acquisition campaign they conducted had a positive impact.
In the past, we have been able to use the second order effects of traffic and rankings to analyze ranking but the problem with that approach, especially for competitive rankings, is if a site moves up only one or two places, there’s no way to know if they are stagnating because the link building campaign isn’t working or if competitors are gaining links faster. Nick Gerner: We now have hundreds of people sucking down our API and integrating it into their own toolsets, which is really exciting because the data is getting out there and people are looking at it, being critical about it, and integrating it into their processes. Rand Fishkin: We have a number of metrics we focus on, but as human beings, we are excited about our projects, which is why we are giving away so much data and doing API deals. We want people to use our data and be critical of it because that’ll make it better, that’ll make SEO less of a dark art and bring some science to this marketing practice.
Eric Enge: Yes. There is a real shortage of science in the whole process, that’s for sure.
Rand Fishkin: There are practitioners in the search marketing field who aren’t going to be digging into formulas and looking at patent applications, but for the population that does care and wants to dig in deeply, we owe it to them, and to ourselves to be transparent. It’s always frustrated me that Google encourages SEO but gives no information on how or why their rankings are calculated.
The answers Google provides to questions are often surface-level and are filtered through a PR lens. I believe, along with a lot of other people, that they could open source their algorithm because exposing it is not dangerous if you have smart engineers and tons of people who care. Wikipedia is open for anyone to edit, and yet it still has phenomenal quality because most of the community are good players.
Google is the same thing. Most of the players are good players. The spammers can do a lot of interesting things if they know everything, but, hiding data via a “security through obscurity” policy is not the way that we should act. Therefore, I want to share the math and the daily processes underneath and be open about how we calculate data. Even if we can’t share the model and its thousands of derivatives, we can explain all the content behind it. Eric Enge: Let’s talk briefly about the API. You’ve mentioned it a couple of times, but could you go into more detail on the kinds of technology involved and what data you can get and ways to use it?
Nick Gerner: The API is a huge part of our engineering and infrastructure. We run a large cluster of machines out of Amazon Web Services, and all of our tools are powered by this API. We opened a lot of new information in our API which is the same API that’s powering Open Site Explorer. If someone approaches us that thinks they can do a better job with our data than we are with Open Site Explorer, they can actually build it themselves; we are encouraging this and are always looking for partners because getting our data out there and sharing that mentality with as many people as possible helps the industry and helps us also.
Rand Fishkin: The API has two implementations: the free one, up to a million calls a month, and the paid one, beyond a million calls a month. There are definitely times when someone is doing interesting things and needs to test above and beyond the million calls per month, and we can make an exception and allow them to do it for free
Nick Gerner: We are really flexible about that. We have a forum where people ask questions and we are super responsive to that. It’s on the API wiki which is apiwiki.seomoz.org. We have documentation there as well as sample applications. Dozens and dozens of agencies and software developers are there.
Rand Fishkin: Nick, could you give a few examples of public applications?
Nick Gerner: There is the search status bar that integrates some of our metrics. I know a lot of people have this one because of the traffic to the API on it. More recently the SEO bar for Chrome has been a hit. It started as a YOUmoz post on SEOmoz and it was huge. It was easily one of the most popular blog posts that month when it launched.
These other directories are using mozRank or Page Authority, which is in the free API.
Virante has donated open source code to the community about how to use the API. They are using our data to find issues on sites that go beyond simple linking issues, into more architectural and technical problems. They are essentially using our data to create technical solutions to the problems. Someone can plug in their site and indicate their issues, click a button, and get an .htaccess file to solve them.
Rand Fishkin: And basically, 301 Redirects a bunch of 404s and error pages which is nice for non-technical webmasters who don’t want to go through the process. Virante plugs in the API and comes out with a tool that does it. They had been using it for their clients, who loved it, so they put it out for free.
Nick Gerner: HubSpot also integrates some of our data in their product.
Eric Enge: Can we talk about more comparison service tools?
Rand Fishkin: There are several sources of link data on the web. Yahoo Site Explorer, which relies on Yahoo’s web index, has been the most popular for the longest time. Some are concerned that the data will go away when Bing powers their search results.
Site Explorer is an awesome source with pros and cons in comparison to Linkscape data. Yahoo Site Explorer’s data is fresher than Linkscape data. Linkscape crawls the web every two to three weeks and has a couple of weeks of processing time to calculate metrics and sort orders for the tools, and API. Therefore, Linkscape produces a new index every three to five weeks. However, Yahoo is producing multiple indices, multiple times per day. When you query Site Explorer, chances are the data will be much fresher. If a site was launched last week, Yahoo is a better tool to see who is linking to it in this first week. We are working on fresh data sources, but for now, Yahoo is great at that. Yahoo is great at size as well; but even though they are bigger than Linkscape, they only expose up to 1,000 links to any URL or domain, so much of the time, Linkscape actually has a greater quantity of retrievable links. One weakness of Site Explorer is that it doesn’t show which links are followed versus not-followed. It is also not possible to see which links contain what anchor text or see the distribution of those anchor texts. It also doesn’t show which pages are important or not important or which ones are on powerful domains or not. Those metrics are, in our opinion, critical to the SEO process of sorting and discovering the right kinds of links.
Another player in this space is a company called Majestic-SEO. They have a distributed crawl system similar to the SETI at Home Project. Lots of people are helping them crawl the web. In terms of raw numbers of retrievable links, their data set is tremendously large, in fact substantially larger than Yahoo which makes some webmasters raise an eyebrow. They’ve been crawling the web for many years and storing all of that data.
Something that needs to be considered in respect to this is that in looking at the Internet, it has been shown that if the good pages continue to be refreshed, 50% of the web disappears every year, and 80% disappears over a couple of years. Majestic has a great deal of historical information that may or may not be in existence. Some people like having that ability to see into their past. Though that segment of the information is dated, since they don’t calculate or process a lot of metrics, some of their data is very fresh along with the older stuff. We certainly consider them a competitor and work to have better features but we respect what they are doing and a lot of webmasters like their information as well.
Those would be the three big ones, Linkscape, Yahoo, and Majestic. It’s also possible to do a link search or Google blog search and find some good links there as well. Alexa also has some linking information but it’s not terrific.
Eric Enge: For heavy-duty SEO, if Yahoo Site Explorer does disappear, the real choices are Linkscape and Majestic?
Rand Fishkin: That’s absolutely right. The great thing about both of these two companies is that they will push each other to be better. Majestic is working hard as are we and pouring a lot of money and resources into smart people to try to be the best and provide webmasters with the absolute best data. I think that’s great. I lament the day that there is one search engine. If Google does ever take a 90%+ market share, I don’t think innovation will happen.
Eric Enge: Could we cover a few interesting metrics such as how many pages you’ve crawled, and links you are aware or anything along those lines?
Nick Gerner: That is a hard question because our tools focus on a timeframe of approximately a month, but in that timeframe, roughly 50 billion pages and on the order of 800 billion links. Those 50 billion pages are across roughly 270 million sub-domains and around 80 million root domains. That’s a good ballpark figure and represents maybe 800 billion links.
That data we are refreshing stacks on itself when going back in history. We do have the historical data, but we aren’t doing anything externally with it right now. Historical data is useful, but in terms of important links, what matters is where competitors are engaged today, what communities they are engaged with, and what a site looks like now. Including historical data could increase our numbers tremendously, but the numbers that we publish are indicative of what data is serving our users. Looking at that, we have 50 billion pages, 270 million sub-domains, 80 million root domains, and in the neighborhood of 800 billion links.
Rand Fishkin: Some users don’t like that our numbers are smaller than Yahoo, or that Yahoo’s numbers are smaller than Majestic. People think bigger numbers have a bigger impact. That desire for bigger numbers needs to be balanced against the usefulness and value of the information for webmasters.
We also want to provide the most transparent story. Sure, we have crawled two trillion pages, but that doesn’t matter if we only serve data on the 50 billion URLs through Open Site Explorer that we saw in the last 30 days. Maintaining this outlook has been tough because branding-wise, big numbers are a big selling point.
Eric Enge: The other tradeoff is how often refresh you can refresh the data.
Nick Gerner: Since we want to make our cycles shorter, we might actually err on the other side and end up with smaller numbers. We might have a two and a half or three-week cycle with slightly smaller index sizes. We want to have multiple indexes and match things up rather than link things in a cycle. If we really want our number bigger than Yahoo’s, than we can make an index covering the last 90 days or 4 months.
Rand Fishkin: As we start to seriously address the historical data of the last six months or two to three years, our numbers are going to reflect that. Right now we are showing the latest snapshot instead of showing the latest snapshot for every month over the last 5 years for instance.
Eric Enge: Any metrics on how no-follow usage has dropped?
Nick Gerner: We don’t have data to suggest that it’s dramatically dropped, but we do have data that suggests that rel canonical is taking off amazingly. The first time we looked, there were a million pages out of our 43 billion that were using it. Now, it’s being used at least as much as no-follow is being used.
Ben Hendrickson: So, about 3% of pages are rel canonical.
Nick Gerner: Some smaller proportion of large sites use it on all their pages, but for those big sites that have jumped on that bandwagon, it’s great for webmasters and SEOs because it’s another tool to use.
Rand Fishkin: Rel=canonical is absolutely phenomenal, and I almost always recommend it by default because it protects against pages getting weird stuff on them or people adding weird tags. What’s your philosophy Eric?
Eric Enge: I am a big believer in rel=canonical. In the recent interview I did with Matt Cutts, he clearly stated that it’s perfectly acceptable to have rel=canonical on every page of a site. Doing that offers protection from people linking with weird parameters on the end, by essentially de-duplicating those pages, which otherwise might not be de-duplicated.
Nick Gerner: It’s exciting to see the web pick it up and have datasets with a snapshot every month. It is somewhat surprising that no-follow usage hasn’t dropped. I don’t know if people saw the negative impact of putting no-follow on links on their pages internally or externally, or if they felt that removing it can have a strong positive impact at least generally speaking.
Eric Enge: I wonder if it says that at this point use of no-follow in blogs and forums is dominating the sculpting.
Rand Fishkin: In the near future, we could potentially expose where no-follow is being used, and whether it is a small number of domains with a large number of pages or the reverse, and how widespread it is. If I can offer a hypothesis about the no-follow matter, a lot of the recommendations have been if it’s working, don’t change it. There hasn’t been a huge mass migration, but maybe new sites that are being built are more conscious of that. On the other hand, with rel canonical, it’s basically big, huge sites that make up large portions of all the pages on the web so it’s not a surprise that it’s taking off in a dramatic way. No-follow, people are still unsure about if they should change, how they should change or if it’s even worth investing in thinking about it at all.
Eric Enge: What do you have in the pipeline for future developments?
Rand Fishkin: By this summer, users will have the ability to look back in time at previous Linkscape industries and compare link growth rates. We think webmasters are interested in what links they have gained or lost over the last few months, particularly important links, which is the information we will try to provide.
We are also going to do more with visualization. Open Site Explorer is a good place to be more visual about the distribution of page authorities and anchor text. Having pretty charts and graphs to show the information can help users see dips. Visually it can highlight what may be an opportunity, or something they missed, or an outlier prompting them to dig deeper. That’s an area of significant growth rates.
Index quality and size is going to get a tremendous amount of attention as well. It’s gotten a great deal of attention over the last 6 or 9 months, but we still have a long way to go in terms of size, freshness, quality, what we crawl, how we crawl it, and how much of it makes it into the index.
Nick Gerner: The Page Authority and Domain Authority have been incredible for us so far and we are going to do more along those lines too.
Rand Fishkin: The data points get better every month, and the Page Authority and Domain Authority get more accurate in predicting Google rankings. There is some internationalization we need to consider for the long-term such as a scenario where if someone is in google.co.uk, or google.com.au, google.com.de, the Page Authority, Domain Authority might not stack up perfectly. We still need to take those into account.
Eric Enge: Do you have a lot of usage internationally?
Rand Fishkin: We do. Right now something in excess of 40% of all pro members at SEOmoz are from outside the US.
Eric Enge: Thanks Rand, Nick, & Ben!