As Oracle BI Cloud Service (BICS) starts to become popular, I am going to write a series blogs about best use of the Data Sync to upload data to BICS schema service. In this post, I am going to share with you a best practice to use Data Sync for ETL.
As an ETL tool, Data Sync does have its strength which is
- Very simple to install, configure, and run data mappings
- Written in Java, runs on any platform that has a Java VM
- Able to connect to any database that has a JDBC driver
- Built in connection support for most commonly used databases
But Data Sync has its own limitations
- No advanced data transformation capabilities as that seen in Informatics and ODI
- Custom SQL query (SQL override) doesn’t work with flat files and data across multiple data sources
- Only SQL Server and Oracle databases are allowed for data writing

If source data are well defined and structured, Data Sync will work perfectly to extract and upload the source data to BICS schema service. If data requires transformation, such as data lookup across multiple datasources, it seems pretty helpless. Although it could be achieved by writing PL/SQLs in Apex BICS schema service, but it’s not a best practice to have the data transformation logic scattered, part in Data Sync as custom SQL query, and part in Apex as PL/SQLs.
A best practice is to introduce a staging database, a common central area for Data Sync to first load all source data for necessary data transformation, then load the transformed data to the BICS schema service. This approach will remedy all the Data Sync’s limitations without loosing its strength, as long as the staging database is either SQL Server or Oracle.
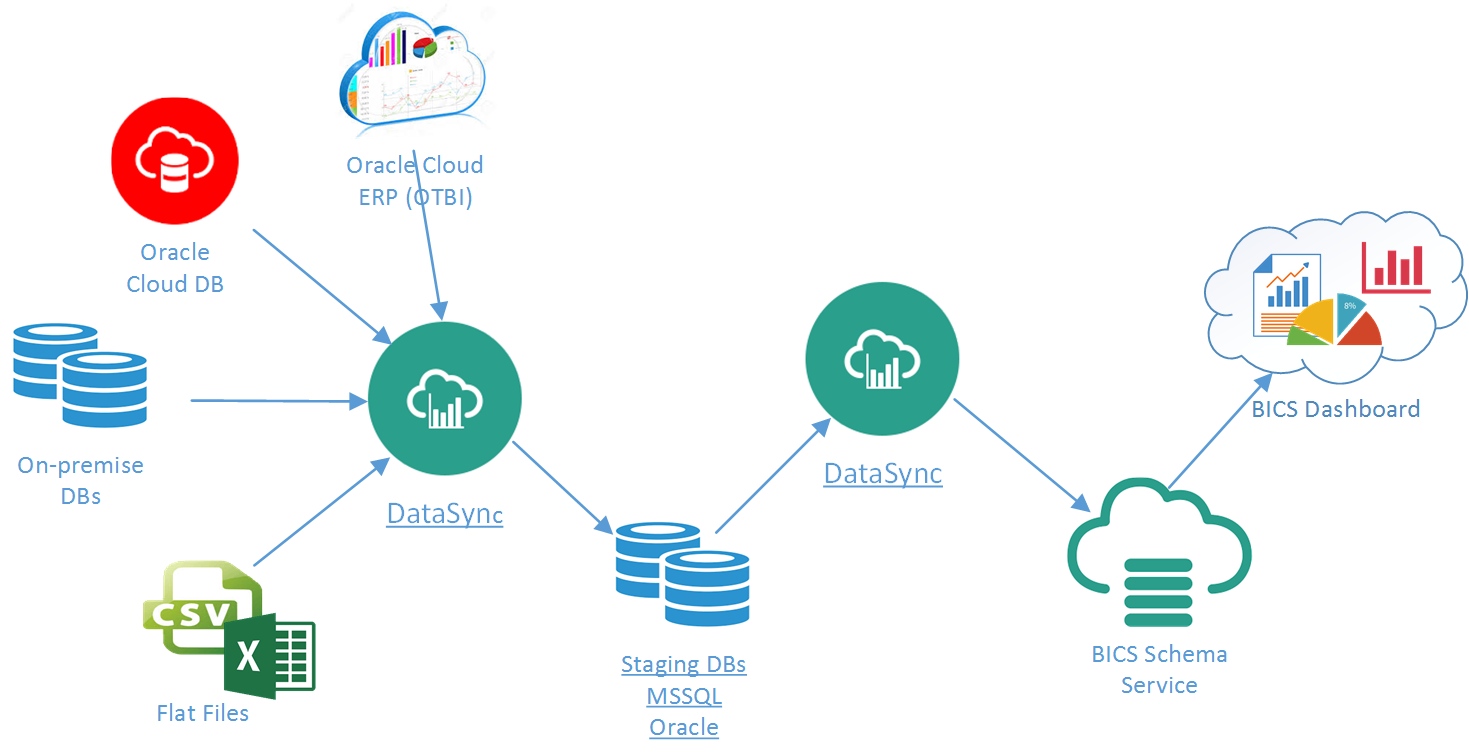
Continue with the Configure Data Sync (BICS) to Load Staging Database for how to set up Data Sync to load staging database.
In my next blog post, I will talk about “3 Ways to Integrate Oracle ERP Cloud (OTBI) with Data Sync (BICS)“.
One of the warnings I used to repeatedly see in Data Sync documentation that Data sync tool stores sensitive information, including connection to your on-premises database. Recommendation was to make sure it is only installed in production in a highly controlled environment.
Questions:
1. Does it still contain connection info ?
2. What other sensitive information does the tool contain ?
3. If #1 and #2 is true, then have such sensitive information in the tool affected the acceptance of the tool ?
Although Data Sync encrypts and stores the sensitive connection info in a file-based credential store – cwallet.sso – the same type of credential store is used by Weblogic, it should always be a best practice to lock down the access to the Data Sync install regardless the connected database is on-premsis or DBaaS.
Thanks Daniel. I do have a related question.
Why would you use one or the other if the choices were Oracle Data Integrator and Data Sync ?
Can you use ODI instead of Data Sync to load data from on-premises to BICS schema as a service via REST APIs ?
Looks like we can load into database as service using ODI. See here:
http://www.ateam-oracle.com/integrating-oracle-data-integrator-odi-on-premise-with-cloud-services/
Data Sync is provided as a lightweight data tool, extremely easy to install and use, almost with zero maintenance, but is designed to do one thing specifically well that is to move data to Oracle BICS schema service and DBaaS. This makes Data Sync support a numbered source and target databases, and the framework not to be easily extendable.
ODI is a full-blown ELT tool, with all the bells and whistles that can be seen in an off-shelf ETL tool. New data transformation can be easily written and run as inline SQL scripts or Java codes. Its Knowledge Module (KM) framework is extremely extendable, custom KMs can always be built to support any types of data source such as social media, makes it future proof. It’s designed to work with any system and perform data integration in a more complex environment.
For a corporation already using ODI for its data integration work, it should leverage the same ODI skills for its BICS data integration. Otherwise, Data Sync should still be the best way to go due to its simplicity.
Thanks again Daniel.
So in Data Sync we can do the following, please confirm :
1. Do incremental loads, meaning, only put into staging records that have changed in the source since the last load.
2. Then, when moving from staging to target, if the record exists in target, update the target record else insert a new record in target. Can use primary key to determine if record exists or not. The target in this case will be db in the cloud. Staging db may be on premises.