
I have written about the importance of migrating to Unity Catalog as an essential component of your Data Management Platform. While Unity Catalog is a foundational component, it should be part of a broader strategic initiative to realign some of your current practices that may be less than optimal with newer, better practices. One comprehensive model to use for guidance is the Databricks well-architected lakehouse framework.
Well-Architected Lakehouse
Databricks borrowed from the AWS Well-Architected framework (minus the Sustainability pillar) and added Data Governance as well as Interoperability and Usability.
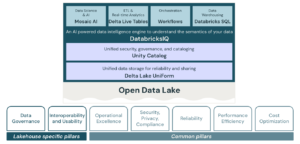 This gives us seven pillars to be concerned with. Realistically, this is a lot to be concerned about before migrating to Unity Catalog. This is a migration so I’m assuming you are at some point in your journey climbing each of these pillars. I also think that its best way to think about these pillars as a journey rather than a destination. But I do believe that a Unity Catalog migration is a great opportunity to revisit where you are and where you want to be from a strategic and organization standpoint and build your migration accordingly. Also, from a practical perspective, some of these pillars just make sense to address before others. I always lead with Cost Optimization because every organization has an imperative to control costs and this is usually the most straightforward initiative to fund. Its been my experience that Performance and Efficiency are a close second because this is how your users perceive the platform during regular use. Operational Excellence reflects how your users perceive the platform during new requests, outages, and other non-regular usage events. Security keeps the lights on. Reliability is what happens when the lights go off. Finally, we can concentrate on the pillars most enabled by Unity Catalog: Governance and Interoperability.
This gives us seven pillars to be concerned with. Realistically, this is a lot to be concerned about before migrating to Unity Catalog. This is a migration so I’m assuming you are at some point in your journey climbing each of these pillars. I also think that its best way to think about these pillars as a journey rather than a destination. But I do believe that a Unity Catalog migration is a great opportunity to revisit where you are and where you want to be from a strategic and organization standpoint and build your migration accordingly. Also, from a practical perspective, some of these pillars just make sense to address before others. I always lead with Cost Optimization because every organization has an imperative to control costs and this is usually the most straightforward initiative to fund. Its been my experience that Performance and Efficiency are a close second because this is how your users perceive the platform during regular use. Operational Excellence reflects how your users perceive the platform during new requests, outages, and other non-regular usage events. Security keeps the lights on. Reliability is what happens when the lights go off. Finally, we can concentrate on the pillars most enabled by Unity Catalog: Governance and Interoperability.
Pillar One: Cost Optimization
The most important element of cost optimization is monitoring. While the same can be said of Operational Excellence and Performance Efficiency, no other metric is as effective in making a case for, and evaluating the effectiveness of, the business value of the Data and Intelligence Platform. Optimizing workloads and tuning resource allocation is an ongoing process, but its almost a wasted effort without proper monitoring. Unity Catalog unlocks system tables, which in turn enables billing monitoring and forecasting. We’re go over the technical components of cost optimization, but make sure you have at some mechanism for monitoring your spend. Every implementation may be different, but there are core concepts in cost optimization that are universal.
Pillar Two: Performance and Efficiency
Improving the performance and efficiency of the Databricks platform will result in both reduced costs and enhanced user experience, but is even more reliant of effective monitoring. Performance and efficiency is more concerned with how the system is used rather than just how the resources are allocated. Designing workloads for performance requires the ability to test and monitor performance characteristics as much as it does knowing the underlying concepts behind the platform to make informed choices around storage and memory consumption. There are some core best practices that can guide your development teams.
Pillar Three: Operational Excellence
Your team as well as your users and your management should have a lot more confidence in the platform’s operation at this point in your migration journey. Now its time to optimize your build and release processes, automate deployments and workflows, manage capacity and quotas and tire everything into continuous monitoring, logging and auditing. This is the part of the journey where Ops comes into play; automation though infrastructure and configuration as code, CI/CD, etc. While there are some common best practices in this area, Databricks has some distinct considerations.
Pillar Four: Security, Compliance and Privacy
This fourth pillar will be directly impacted by Unity Catalog around identity and access control. There are other basic considerations, like protecting data at rest and in transit and meeting compliance and regulatory compliance that are already likely in place. The steps that were taken in operational excellence should have had secuirty in mind. This is a good time to just revisit those ops pipelines as you review and implement other best practices.
Pillar Five: Reliability
Reliability builds and expands upon some of the topics covered in other pillars, like automation, monitoring and autoscaling. It goes even further into managing for data quality, designing for failure and, ultimately, designing and testing real-world disaster recovery scenarios. Its been my experience that enterprises are very weak in disaster recovery and are acutely aware of this weakness. There are some foundational practices around reliability that can provide a concrete roadmap to reliability.
Pillar Six: Data and AI Governance
Finally, we are dealing with the topic of governance, which is frequently the motivation for Unity Catalog migration in the first place. After all,
Databricks Unity Catalog is the industry’s only unified and open governance solution for data and AI, built into the Databricks Data Intelligence Platform. With Unity Catalog, organizations can seamlessly govern both structured and unstructured data in any format, as well as machine learning models, notebooks, dashboards and files across any cloud or platform.
Governance at this level requires established data quality standards and practices as well as a unified data and AI management, security and access model. Preferably automated. There are very distinct best practices around data, machine learning and artificial intelligence that would prove difficult to achieve if not for the foundational work of the prior pillars, particularly pillars one through four.
Pillar Seven: Interoperability and Usability
This final pillar is essentially the business value of your Databricks platform; its ability to service users and systems. Usability is a measurement of users ability unlock business value from your plaform in a safe, efficient and effective manner. Interoperability is a key component of a lakehouse in that it measures the systems ability to interact with other systems, also in a safe, effective and efficient manner. The hallmarks of such a system include open and defined standards for integration, data formats and governance. Interoperability should include the ability so safely publish data to and consume data from external systems. New use case implementation should have a bias towards self-service. As you can see, all of the pillars have been leading up to supporting the highest degree of interoperability and usability. There are even additional best practices that can take this to another level.
Conclusion
This discussion of a well-architected framework came from the topic of Unity Catalog migration. This was not a tangent; this is a reflection of how many of our Unit Catalog migrations have worked in practice. Strategically, the goal is to quickly, safely and effective unlock business value from data using reporting, analytics, machine learning and AI in a consistent, reliable and cost-effective manner across the enterprise. Unity Catalog unlocks a lot of these capabilities from the Databricks Data and AI platform. However, these capabilities in the absence of a well-architected framework will dilute the results by increasing the cost of administration, decreasing the quality and quantity of use case fulfilment and increasing risk exposure.
Contact us for a complimentary Migration Analysis and let’s work together on your data and AI journey!