
In this blog post, we’ll dive into two powerful features of Snowflake: Snowpipe and Streams. Both Snowpipe and Streams are crucial components for real-time data processing and analytics in Snowflake. We’ll explore what each feature entails and how they can be leveraged together to streamline data ingestion and analysis workflows, harnessing the Power of Snowflake’s Snowpipe and Streams.
Snowpipe
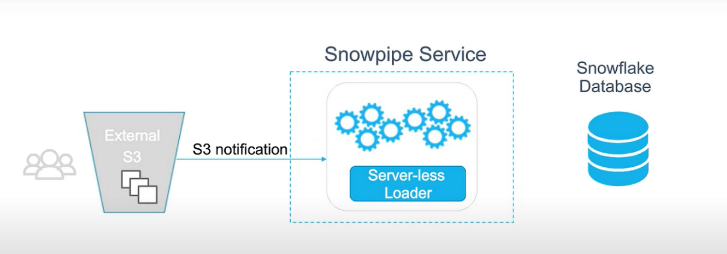
Snowpipe is a vital feature of Snowflake that automates the process of loading data as soon as new files appear in a designated location, such as a cloud storage bucket. This eliminates the need for manual intervention and ensures that fresh data is readily available for analysis without delay. Snowpipe operates as a serverless function, managed by Snowflake itself, thus alleviating the burden of managing virtual warehouses.
Streams in Snowflake
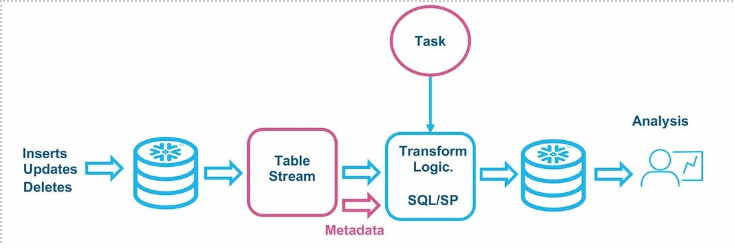
Streams in Snowflake provide a continuous, ordered flow of changes made to a table. Whenever a DML (Data Manipulation Language) operation is performed on a table, such as INSERT, UPDATE, or DELETE, the corresponding change data is captured and made available through the stream. Streams are invaluable for capturing real-time changes to data, enabling downstream processing and analytics in near real-time.
Setting up Snowpipe and Streams
Creating the Table
-- Create table to store employee data CREATE OR REPLACE TABLE SNOW_DB.PUBLIC.employees ( id INT, first_name STRING, last_name STRING, email STRING, location STRING, department STRING );
Creating a Stream
Before setting up Snowpipe, we need to create a stream on the target table to capture the changes.
-- Create a stream on the target table CREATE OR REPLACE STREAM my_stream ON TABLE SNOW_DB.PUBLIC.employees;
Configuring Snowpipe
Now, let’s configure Snowpipe to automatically load data from an external stage into our target table whenever new files are added.
-- Create a stage object CREATE OR REPLACE STAGE DATABASE.external_stages.csv_folder URL = 's3://snowflakebucket/csv/snowpipe' STORAGE_INTEGRATION = s3_int FILE_FORMAT = DATABASE.file_formats.csv_fileformat; -- Create a pipe to load data from the stage CREATE OR REPLACE PIPE DATABASE.pipes.my_pipe AS COPY INTO SNOW_DB.PUBLIC.employees FROM @DATABASE.external_stages.csv_folder;
Example Scenario
Imagine we have a stream of customer transactions being continuously ingested into our Snowflake database. With Snowpipe and Streams configured, we can seamlessly capture these transactions in real time and analyze them for insights or trigger further actions, such as fraud detection or personalized marketing campaigns.
Output from Stream
The stream “my_stream” captures the changes made to the “employees” table. We can query the stream to see the change data using the SELECT statement:
-- Query the stream for change data SELECT * FROM my_stream;

This query will return the change data captured by the stream, including the operation type (INSERT, UPDATE, DELETE) and the corresponding data changes.
Example Output
Suppose there have been some insertion operations on the “employees” table. The query to the stream might return something like this:
| METADATA$ACTION | METADATA$ISUPDATE | METADATA$ROW_ID | ID | FIRST_NAME | LAST_NAME | EMAIL | LOCATION | DEPARTMENT |
|—————–|——————-|—————–|—–|————|———–|————————|————–|————|
| INSERT | false | 1 | 101 | John | Doe | john.doe@example.com | New York | Sales |
| INSERT | false | 2 | 102 | Jane | Smith | jane.smith@example.com | Los Angeles | Marketing |
| INSERT | false | 3 | 103 | Bob | Johnson | bob.johnson@example.com| Chicago | Engineering|
In this example, each row represents an insertion operation on the “employees” table. The “METADATA$ACTION” column indicates the action performed (in this case, INSERT), while the “ID”, “FIRST_NAME”, “LAST_NAME”, “EMAIL”, “LOCATION”, and “DEPARTMENT” columns contain the inserted employees’ data.
This stream output provides insight into the changes made to the “employees” table, enabling real-time monitoring of operations.
Additional use cases
Real-Time Monitoring of Financial Transactions
Financial institutions can utilize Snowpipe and Streams to monitor financial transactions in real time. By setting up Streams on relevant tables, they can capture and analyze changes in transaction data, enabling them to detect potential fraudulent activities or financial risks promptly. For example, they can set up automated alerts to identify suspicious transaction patterns and take corrective actions immediately.
Analysis of User Behavior in Web and Mobile Applications
Technology companies can leverage Snowpipe and Streams to analyze user behavior in their web and mobile applications. By capturing user events such as clicks, interactions, and purchases in real-time through Streams, they can gain valuable insights into user experience, identify areas for improvement, and dynamically personalize user experiences. This enables them to offer personalized recommendations, targeted marketing campaigns, and features tailored to individual user needs.
Conclusion
By harnessing the power of Snowpipe and Streams in Snowflake, organizations can achieve efficient real-time data ingestion and analysis, enabling timely decision-making and unlocking valuable insights from streaming data sources.
This blog post provides an overview of both Snowpipe and Streams, followed by a step-by-step guide on setting them up and an example scenario demonstrating their combined usage.