
Introduction
In the previous blog post, we showed you how to scrap a website, extract its content using Python, and store it in Azure Blob Storage. In this blog post, we will show you how to use the Azure Blob data and store it in Azure Cognitive Search (ACS) along with vectors. We will use some popular libraries such as OpenAI Embeddings and Azure Search to create and upload the vectors to ACS. We will also show you how to use the vectors for semantic search and natural language applications.
By following this blog post, you will learn how to:
- Read the data from Azure Blob Storage using the BlobServiceClient class.
- Create the vectors that ACS will use to search through the documents using the OpenAI Embeddings class.
- Read the Data from Azure Blob Storage.
- Load the data along with vectors to ACS using the AzureSearch class.
Read Data from Azure Blob Storage:
The first step is to read the data from Azure Blob Storage, which is a cloud service that provides scalable and secure storage for any type of data. Azure Blob Storage allows you to access and manage your data from anywhere, using any platform or device.
To read the data from Azure Blob Storage, you need to have an Azure account and a storage account. You also need to install the Azure Storage, which is a library that provides a simple way to interact with Azure Blob Storage using Python.
To install the Azure Storage SDK for Python, you can use the following command:
pip install azure-storage-blob
To read the data from Azure Blob Storage, you need to import the BlobServiceClient class and create a connection object that represents the storage account. You also need to get the account URL, the credential, and the container name from the Azure portal. You can store these values in a .env file and load them using the dotenv module.

For example, if you want to create a connection object and a container client, you can use:
STORAGEACCOUNTURL = os.getenv("STORAGE_ACCOUNT_URL")
STORAGEACCOUNTKEY = os.getenv("STORAGE_ACCOUNT_KEY")
CONTAINERNAME = os.getenv("CONTAINER_NAME")
blob_service_client_instance = BlobServiceClient(account_url=account_url, credential=credential)
container_client = blob_service_client_instance.get_container_client(container=container)
blob_list = container_client.list_blobs() Load the Documents and the Vectors to ACS:
The final step is to load the documents and the vectors to ACS, which is a cloud service that provides a scalable and secure search engine for any type of data. ACS allows you to index and query your data using natural language and semantic search capabilities.
To load the documents and the vectors to ACS, you need to have an Azure account and a search service. You also need to install the Azure Search library, which is a library that provides a simple way to interact with ACS using Python.
To install the Azure Search library, you can use the following command:
pip install azure-search
To load the documents and the vectors to ACS, you need to import the AzureSearch class and create a vector store object that represents the search service. You also need to get the search endpoint, the search key, and the index name from the Azure portal. You can store these values in a .env file and load them using the dotenv module.
For example, if you want to create a vector store object and an index name, you can use:
from azure_search import AzureSearch
from dotenv import load_dotenv
import os
# Load the environment variables
load_dotenv()
# Get the search endpoint, the search key, and the index name
vector_store_address : str = os.getenv("VECTOR_STORE_ADDRESS")
vector_store_password : str = os.getenv("VECTOR_STORE_PASSWORD")
index_name : str = os.getenv("INDEX_NAME")
# Create a vector store object
vector_store: AzureSearch = AzureSearch(
azure_search_endpoint=vector_store_address,
azure_search_key=vector_store_password,
index_name=index_name,
embedding_function=embeddings.embed_query,
) Then, you can load the documents and the vectors to ACS using the add_documents method. This method takes a list of documents as input and uploads them to ACS along with their vectors. A document is an object that contains the page content and the metadata of the web page.
For example, if you want to load the documents and the vectors to ACS using the stored in blob storage, you can use below code snippet by utilizing container_client and blob_list from above:
def loadDocumentsACS(index_name,container_client,blob_list):
docs=[]
for blob in blob_list:
# Read the blobs and parse them as JSON
blob_client = container_client.get_blob_client(blob.name)
streamdownloader = blob_client.download_blob()
fileReader = json.loads(streamdownloader.readall())
# Process the data and creating the document list
text = fileReader["content"] + "\n author: " + fileReader["author"] + "\n date: " + fileReader["date"]
metafileReader = {'source': fileReader["url"],"author":fileReader["author"],"date":fileReader["date"],"category":fileReader["category"],"title":fileReader["title"]}
if fileReader['content'] != "":
doc = Document(page_content=text, metadata=metafileReader)
else:
pass
docs.append(doc)
#Loading the documents to ACS
vector_store.add_documents(documents=docs) You can verify whether your data has been indexed or not in the indexes of the Azure Cognitive Search (ACS) service on the Azure portal. Refer to the screenshot below for clarification.
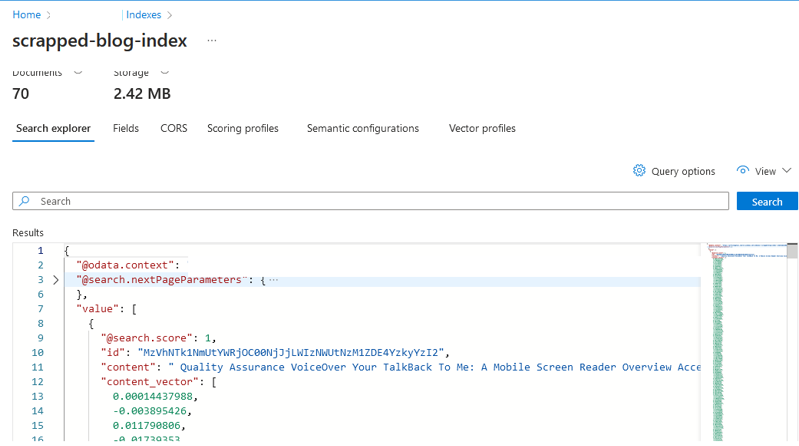 Conclusion:
Conclusion:
This blog post has guided you through the process of merging Azure Blob data with Azure Cognitive Search, enhancing your search capabilities with vectors. This integration simplifies data retrieval and empowers you to navigate semantic search and natural language applications with ease. As you explore these technologies, the synergy of Azure Blob Storage, OpenAI Embeddings, and Azure Cognitive Search promises a more enriched and streamlined data experience. Stay tuned for the next part, where we step into utilizing vectors and generating responses and performing vector search on user queries.
Thank you for sharing good information.