
Introduction Automatic Speech recognition:
In the world of artificial intelligence, one of the most fascinating advancements is the ability to convert spoken language into written text. This process, known as Automatic Speech Recognition (ASR), has a wide range of applications, from transcription services and voice assistants to real-time captioning and more. In this blog post, we’ll explore how to use OpenAI’s Whisper ASR system to transcribe an audio file into text using Python.
What is Whisper?
OpenAI developed Whisper as an Automatic Speech Recognition (ASR) system. It trained on a substantial volume of multilingual and multitask supervised data gathered from the web. Whisper offers a Python library that makes it easy to transcribe audio files into text.
Getting Started :
Before we can use Whisper, we need to install the openai-whisper Python package. This can be done using pip:

The ! at the beginning is used to run shell commands in Jupyter notebooks. If you’re running this in a regular Python environment, you can omit the !.
Loading the Model :
Once you install the package, you can import the whisper module and load the model:
Whisper provides different model sizes to balance between speed and accuracy as follow :-
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |

Whisper’s model sizes, computational power is a key consideration when assessing the system’s ability to handle different model sizes efficiently. The required VRAM and relative speed mentioned in the table showcase how different model sizes demand varying computational resources, impacting performance and the ability to process tasks with differing degrees of efficiency and accuracy.
In our case, we’re loading a “small” model.

Transcribing an Audio File :
With the model loaded, we can now transcribe an audio file. Here’s how:

The transcribe method takes the path to the audio file as its argument. Furthermore, the fp16=False argument specifies that the model should not use half-precision floating-point format (FP16) for computations. Consequently, this can speed up the process but might slightly reduce accuracy.
The transcribe method returns a dictionary that includes the full transcription and other information.
Detailed Transcription :
Additionally, Whisper offers a detailed breakdown of the transcription, encompassing the start and end times of each segment. This feature can be particularly beneficial for comprehending the chronological occurrence of each part within the audio file:
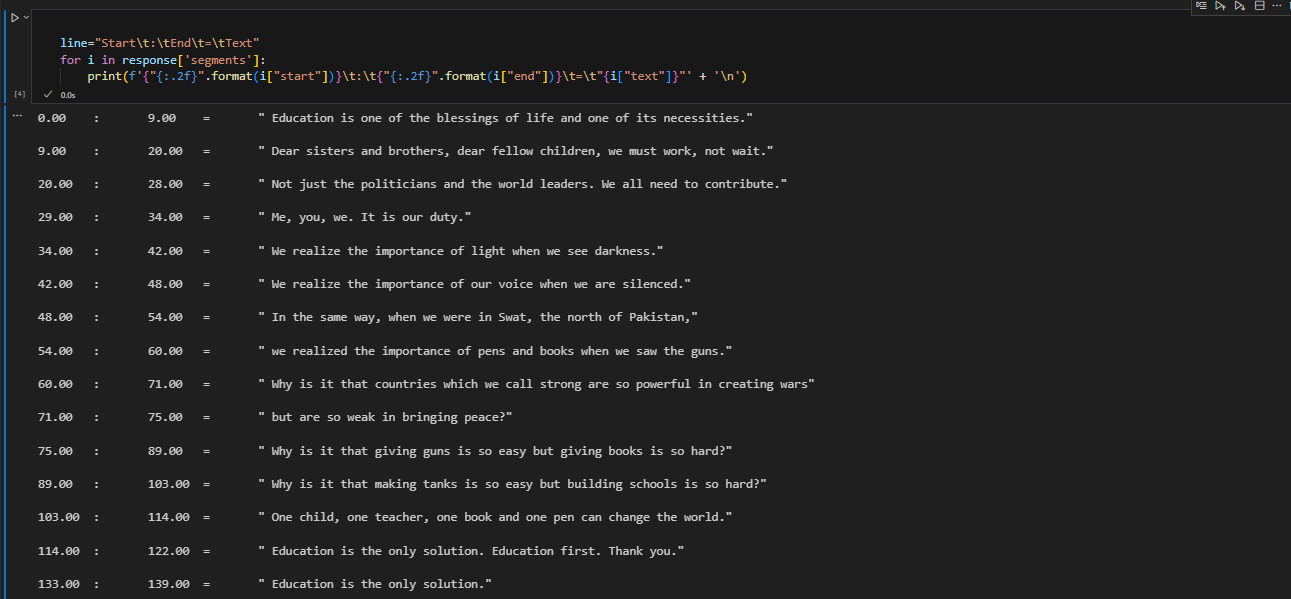
Conclusion:
OpenAI’s Whisper Automatic Speech Recognition (ASR) system provides a powerful and easy-to-use tool for transcribing audio files into text. If constructing a voice assistant, developing a transcription service, or requiring transcription for audio files in a project, Whisper is adept at handling these tasks. If you have any query, you can directly discuss in with the community link
Happy transcribing!
Your insights here really got me thinking!
This topic is so timely, thanks for addressing it!
I never looked at it that way before—great perspective!
Thank you for sharing good information.