
Hello everybody! I am Brandon Hernández Flores, an intern working at Perficient offices in Mexico. This time, I am focusing on Artificial Intelligence, a cutting-edge technology offered by Azure. Since my professional career started, I affirmed that everything related to Tech was for me. However, I did not know what I was certainly going to dedicate myself to. Therefore, these first looks at AI are key to my professional development. Furthermore, why not do it and at the same time add value to the company? Let’s take a look.
What is Artificial Intelligence?
According to IBM, “Artificial intelligence leverages computers and machines to mimic the problem-solving and decision-making capabilities of the human mind”. This topic has become very relevant, and I trust it will become more relevant as time goes by. So, why is it important to keep up with the evolution of AI? It depends on what the company is looking for, for example: to save time and money, efficient and effective processes, to increase incomes, and others. And who knows? Maybe developers will discover more innovative technologies to work on that have never been thought of before.
Definition of our Study Case
In our case study, the Talent Fulfillment department is looking for the best candidates, where results are based on a description provided by a client, to continue with the Assignation process. What is the matter? Imagine navigating through an ocean of information called CVs. Then, you must find those candidates who match their profile with someone that a client is looking for, but you have more than two hundred documents to search on. Maybe there is a filter by departments or areas, but what if we have a thousand documents? Currently, this part of the process takes one day to complete. Here is where AI comes into play.
Which Technologies We Use for the Solution?
The Search Engine is developed with Azure AI Services due to data security (company privacy), maintenance, support assistance, documentation, functionalities, and other features. On the one hand, Azure has a service called “Azure Cognitive Search” where features were precisely what the project needed, such as document/vector database, types of searches, weighting information, and text analysis (comprehending context and similarities). On the other hand, Azure offers “Azure OpenAI” where different models can be built, each one for a certain function. For example, we use the Ada model to generate embeddings and the GPT3.5 model to create attractive descriptions for candidates selected.
Before we started to build the official project, we decided to code examples to test the technology. Once we made the decision to stay with Azure due to its affinity towards the project, a plan was established.
The Beginning of our Solution
First, the curriculum (let’s call it “CV”) of each employee is extracted from a SQL Server and re-built to Json format (let’s call it “CV Json”), and this Json goes to an Azure Blob Storage container. Then, the Search Engine connects to the Blob Storage container and collects its information, then it is vectorized, which means transforming specific fields (descriptions or large text as an “Overview field”, for example) to vectors. Finally, we store them in the same Json.
At this point, for example, the CV Json of each person has an “Overview field” and an “Overview Vector field”, and the same with other applicable fields. The reason is that we must search in both fields: the normal and the vectorized. And for example, we are not going to vectorize “technologies field” because those are key words and not long descriptions. All CV Jsons are uploaded and stored in an index in Azure Cognitive Search, where also the search is executed.
Search Types: Full Text Search, Vector Search and Hybrid Search,
We must use Full-Text Search and Vector Search together, called “Hybrid Search”.
Full Text Search
First, Full-Text Search is the one we all know: search for a keyword in a large text, and the word must be in there. For example, Brandon has the word “Python” in the technologies field on his CV Json and if I search “python”, Brandon’s Profile will appear. Something easy.

All searchable text fields apply for this Full-Text Search, not the vectorized ones. Finally, a scoring profile needs to be set up. This helps assign weight to the different text fields and influences the score (the number that refers to the relevance of the results with respect to the search); for example, the responsibilities of a person involved in a job carry more weight than the brief overview in its profile.
Vector Search
Vector Search is a different concept: search for similarity between a vector against each vector in a vector database. First, let’s define what a vector is. A vector is a numerical representation of a word or phrase, made by AI, meaning that AI software understands the natural language somehow. An example can be the next one: “[1.4123, 3.2310, 0.4240, 0.0932…]”. The minimum dimensions are 1536, which means positions in the vector.
AI software can understand the context of a sentence or similarities between words thanks to clusters in a multi-dimensional coordinate system. For example, the word “hospital” is more related to the cluster “Health” than the cluster “Technology”.
A vector database is a collection of vectors where, using Azure Cognitive Search, a vector can be compared against each vector of the database (calculating the distance between two vectors, which gives the score). It is mandatory to use the OpenAI ada model to create these vectors, both for each input query and for information in the database.
Vector Search starts to compare the vectorized query against all vectorized fields in each CV Json and takes back the most relevant results for each vectorized field; for example: the top 10 profiles from “Overview Vector field” comparison (the output is a one list), Top 10 profiles from “Responsibilities Vector field” comparison (the output is a second list), etc. So, one or many lists can be retrieved from here with ranked results according to the score.
Likewise, Full-text Search creates its own list of the most relevant results that match with the normal query.
Hybrid Search
Hybrid Search uses these two last techniques together. The unique difference is that the full input query is vectorized for Vector Search, but then the Engine cleans up input query and uses the result for Full Text Search. With this, we prevent getting wrong results and not search terms like “and”, “but”, “or”, “a”, “the”, etc. The purpose of Hybrid search is to interpret large queries and use key words to ensure the context.
To obtain hybrid search score, each item of all these lists created (Full-Text Search list and Vector Search list/s) receives a score based on its position on its own list by a formula (1/(P+k), where P is the position of the item in its list and k = 60 is a variable by default), as you can see in the image below. Therefore, to make this clear, the first item of each list is going to have the same score, the second item of each list the same, and so on. After that, all the items are collated among themselves and when a profile appears, as many times as possible in these lists, then a sum is applied to merge its scores in such a way that a new list of results is created and sorted. At the end, only one unique list exists, and it is the one that cares.
Finally, a percentage of match is made considering the “perfect candidate” (the hypothetical case when someone appears as first place in all the lists mentioned before, so it is a 100% match).
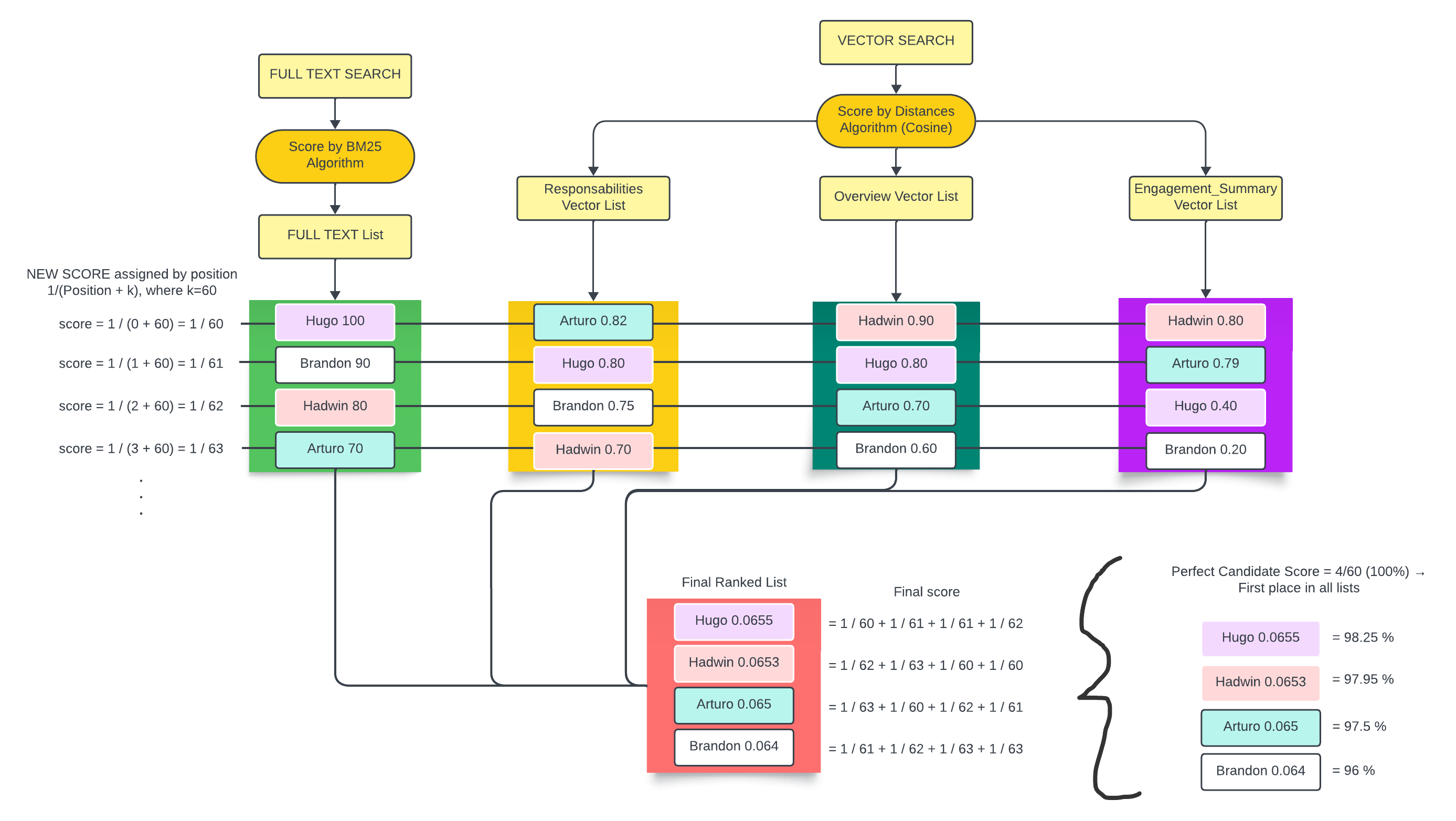
Figure 1 Diagram to explain the score of Hybrid Search.
Observations
- First, we tried to use only Vector search for the Engine. However, we noticed that some results were irrelevant considering the query. The reason could have been that sometimes the context is not only what you need to match with a profile in this case, because there are some key words that can be more related to certain employees. So, we took the best part of both search types.
- Using only Full Text search is a complementary idea because we receive both descriptions and key words.
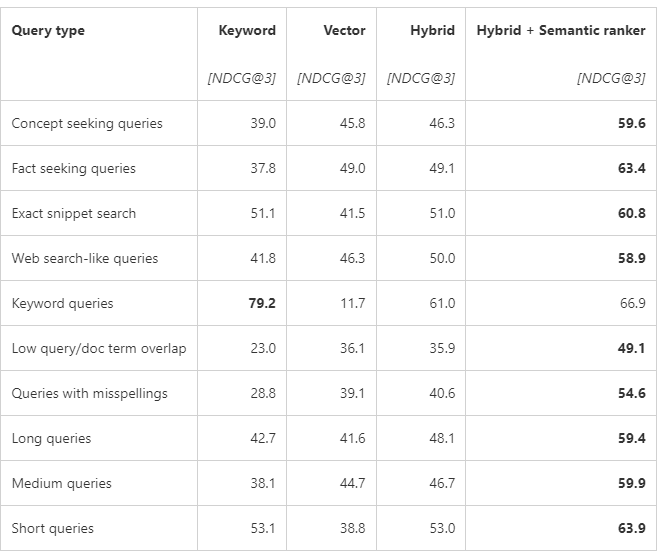
Figure 2 Comparison between Full text, Vector and Hybrid searches, with specific configurations
- Also, we needed to define the scoring profile well to help us to get better results given what Talent Fulfillment considers more relevant in a CV.
- A word filter is so necessary to clean up long queries because most of the cases the query has useless words, for example: “as”, “or”, “for”, “has”, “a”, “and”, etc. This helps a lot to assign an accurate score for candidates in the Full Text Search.
- Queries have to be preferably formatted, just as plain text to prevent extra irrelevant special characters.
- At the beginning, we wanted to connect the index in Azure Cognitive Search directly to the Azure Blob Storage as a data source and get the Jsons. However, this approach was incorrect because the index couldn’t parse the Json and make the fields properly. Mandatory, all the data coming directly from Blob Storage is parsed into two fields: content and metadata. And then, the “content field” (a complex type field) has all the correct fields of the Json inside. The problem is that it is not allowed to do Vector Search to fields inside a complex type field and scoring profiles doesn’t apply. Therefore, we decided to download data from the Blob Storage container into the Search Engine and then upload the Jsons correctly to the index from the Search Engine.
Once Concepts are Known, Testing Comes
At this point, you know the concepts involved in this project. Now, what is next? That is right, time to introduce an input query.
- Let’s say you are looking for a Product Owner, so you give a brief description of what are you looking for this PO (Product Owner) to do. So, we execute a Hybrid Search.
- Then, internally, a vectorized query is created from this input query in such a way that a Full-Text Search is done by the input query, and the Vector Search is executed by the vectorized query.
- Up to here, the results of each search are ready.
- Then, the score process described before, for Hybrid Search Score, is carried out.
- And then, the best profiles that match with the petition are retrieved.
- Finally, the information from the best profiles is given to the GPT3.5 model which is responsible for creating the best marketing description for each person, and thus selling the best image of each candidate. Generative AI is what gives us, the creation of texts according to what you want it to produce in seconds.
By creating this entire program, some benefits are acquired such as: less search time for searching profiles (1 day before à # minutes after), better delivery for clients, profit increase, and agile processes. You can get the most out of these technologies by learning and developing a project.
Thanks for reading until here. I hope you enjoyed it!
References:
- IBM. What is artificial intelligence (AI)? URL Web: https://www.ibm.com/topics/artificial-intelligence
- Microsoft. Vector search in Azure Cognitive Search. URL Web: https://learn.microsoft.com/en-us/azure/search/vector-search-overview
- Microsoft. Hybrid search using vectors and full text in Azure Cognitive Search. URL Web: https://learn.microsoft.com/en-us/azure/search/hybrid-search-overview
- Microsoft. Full text search in Azure Cognitive Search. URL Web: https://learn.microsoft.com/en-us/azure/search/search-lucene-query-architecture
- Microsoft. Learn how to generate embeddings with Azure OpenAI. URL Web: How to generate embeddings with Azure OpenAI Service – Azure OpenAI | Microsoft Learn
- Berntson, A. (2023) Azure Cognitive Search: Outperforming vector search with hybrid retrieval and ranking capabilities. URL Web: Azure Cognitive Search: Outperforming vector search with hybrid retrieval and ranking capabilities – Microsoft Community Hub
Thank you for sharing good information.