Pre-requisite
Before going through SCD Type 2, I would suggest visiting my earlier post with respective to SCD Type 1 in here for better understanding of this blog.
Dynamic Merge in Snowflake using Stored Procedure and Python – For SCD Type 1 / Blogs / Perficient
SCD Type 2
It helps in tracking the history of updates to your dimension record. The best example is to hold the history of employee in an organization. Below is an example where we have source system as source while data warehouse table as our target which maintains history.
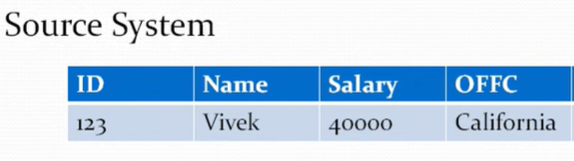
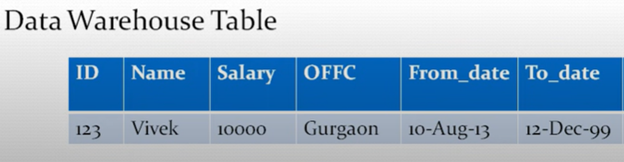
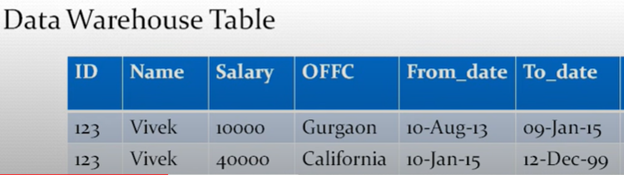
Expected Output
Initially Vivek was in Gurgaon office but moved to California after 10 Jan 2015. So, the key is we had to update the existing record to have an updated To_Date and then insert the new record in the target table with the right From_Date and To_Date.
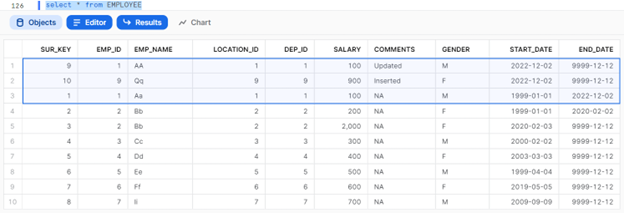
Dynamic Merge for SCD Type 2
Source – EMP_STG Table looks like below.

Target – Employee Table looks like below. I have used AUTOINCREMENT for SUR_KEY column. So each time a record is inserted this column generates an automatic sequence.
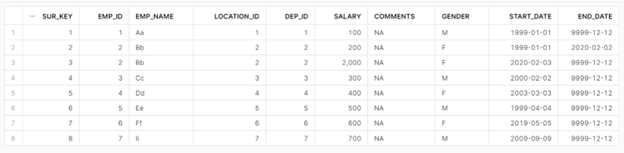
MAP Table – We define our mapping fields between source and target tables as below.
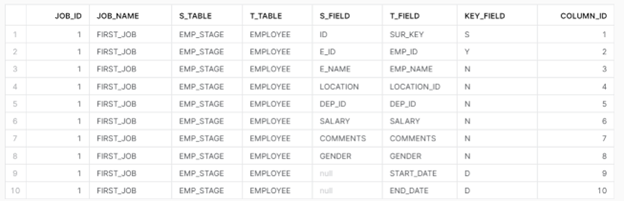
KEY_FIELD – ‘S’ denotes Surrogate Key of both tables. Make sure ID is the column name by default for Source as Source table don’t have Surrogate key normally)
KEY_FIELD – ‘Y’ denotes normal primary key field of the table.
KEY_FIELD – ‘N’ denotes the non-primary key field columns
KEY_FIELD – ‘D’ denotes the normal START/END DATEs of the TARGET table (source table usually don’t have those – so can have that as BLANK)
Code Logic
The construction might be bit similar like earlier post. The key logic is to build the Merge Statement for SCD type 2 by preparing a source query as below.
SELECT NULL as ID, E_ID,E_NAME,LOCATION,DEP_ID,SALARY,COMMENTS,GENDER,CURRENT_DATE() ,TO_DATE(’12/12/9999′,’MM/DD/YYYY’) FROM
EMP_STAGE
UNION ALL
SELECT SUR_KEY, EMP_ID, EMP_NAME, LOCATION_ID, DEP_ID, SALARY, COMMENTS, GENDER, START_DATE, END_DATE
FROM EMPLOYEE
WHERE (EMP_ID) IN (SELECT E_ID FROM EMP_STAGE )
With this query, we get the matching record for E_ID: 1 from EMPLOYEE table as well and look like something below.

We consider this as Source Table and then apply MERGE on top of this to write the data to Target Table – Employee.
For this example, first 2 rows should be inserted with start_date as today and end _date as future date as they have blank Surrogate Key. For last record, it should update the end_date as today based on the Surrogate_Key column.
We can leverage stored procedure, python, and pandas dataframe concepts from last post with a little tweak to match the above logic.
Code Snippet
Let us go from bottom of the stored procedure to understand better.
Below is the final Merge which contains various ‘strings’ for which we must find the respective statements.
mrg_sql = “MERGE INTO ”
mrg_sql = mrg_sql + f”{t_tab}” + ” USING ” + f”{s_query}”
mrg_sql = mrg_sql + ” ON ” + f”{arr_surr_key_fields}”
mrg_sql = mrg_sql + ” WHEN MATCHED THEN UPDATE SET ”
mrg_sql = mrg_sql + f”{arr_update_fields1}”
mrg_sql = mrg_sql + ” WHEN NOT MATCHED THEN INSERT (”
mrg_sql = mrg_sql + f”{arr_tgt_key_fields}” + “) VALUES (”
mrg_sql = mrg_sql + f”{arr_src}” + “)”
t_tab – comes from the parameter value for Target table
s_tab – comes from parameter value for the Source Table
s_query – contains the new source query we need as below.
s_query = “(SELECT NULL as ID, ” + f”{arr_src_key_fields}” + ” FROM ” + f”{s_tab}” + ” UNION ALL ”
s_query = s_query + “SELECT ” + f”{arr_tgt}” +” FROM ” + f”{t_tab}” + ” WHERE (” + f”{arr_tgt_k_fields_1}” + “) IN ”
s_query = s_query + “(SELECT ” + f”{arr_src_k_fields_1}” + ” FROM ” + f”{s_tab}” + ” ) ) Source”
arr_src_key_fields / arr_tgt_key_fields – to get the source/target fields of all non-surrogate keys, have used below code.
df_key = session.sql(f”’
SELECT S_FIELD as S_FIELD, T_FIELD as T_FIELD FROM MAP_TABLE WHERE S_TABLE='{s_tab}’ AND T_TABLE='{t_tab}’ AND KEY_FIELD!=’S’ ORDER BY COLUMN_ID
”’)
count_1 = df_key.count();
var_filter = ”;
df2 = df_key.to_pandas()
df2[‘colB’] = “,”;
df2[‘colB’].iloc[count_1-1] = ” ”

df2[‘S_FIELD’].iloc[count_1-1] = “TO_DATE(’12/12/9999′,’MM/DD/YYYY’) ”
df2[‘S_FIELD’].iloc[count_1-2] = “CURRENT_DATE() ”
df2[‘SRC’] = df2[‘S_FIELD’]+df2[‘colB’]
df2[‘TGT’] = df2[‘T_FIELD’]+df2[‘colB’]
df_src = df2[‘SRC’]
df_tgt = df2[‘TGT’]
arr_source = df_src.to_numpy()
arr_src_key_fields = ”.join(arr_source);
arr_target = df_tgt.to_numpy()
arr_tgt_key_fields = ”.join(arr_target);
arr_tgt/ arr_src – to find all the source/target fields, have used below code.
df_temp = session.sql(f”’
SELECT T_FIELD, ‘Source’||’.’||S_FIELD AS SOURCE FROM MAP_TABLE WHERE S_TABLE='{s_tab}’ AND T_TABLE='{t_tab}’ ORDER BY COLUMN_ID
”’)
total=df_temp.count()
df_insert=df_temp.to_pandas()
df_insert[‘colB’] = “, “;
df_insert.iloc[total-1, 2] = ” ”
df_insert[‘SRC’] = df_insert[‘SOURCE’]+df_insert[‘colB’]
df_insert[‘SRC’].iloc[total-1] = “TO_DATE(’12/12/9999′,’MM/DD/YYYY’) ”
df_insert[‘SRC’].iloc[total-2] = “CURRENT_DATE(), ”
df_insert[‘TGT’] = df_insert[‘T_FIELD’]+df_insert[‘colB’]
df_tgt = df_insert[‘TGT’]
df_src = df_insert[‘SRC’]
arr_tgt_col = df_tgt.to_numpy()
arr_tgt = ”.join(arr_tgt_col);
arr_src_col = df_src.to_numpy()
arrayy=np.delete(arr_src_col,0)
arr_src = ”.join(arrayy);
arr_update_fields1 – to get the string for update part, have used below code.
df_update_fields = session.sql(f”’
SELECT ‘{t_tab}’||’.’||T_FIELD||’=’||’CURRENT_DATE()’ as E_DATE FROM MAP_TABLE E WHERE S_TABLE='{s_tab}’ AND T_TABLE='{t_tab}’ AND KEY_FIELD=’D’ ORDER BY COLUMN_ID DESC LIMIT 1
”’)
c = df_update_fields.count();
var_filter = ”;
df1_update_fields = df_update_fields.to_pandas()
df2_update_fields = df1_update_fields[‘E_DATE’]
arr_update_fields = df2_update_fields.to_numpy()
arr_update_fields1 = ”.join(arr_update_fields);
arr_surr_key_fields – to get the string for ON condition part, have used below code to get the Surrogate key fields.
df_surr = session.sql(f”’
SELECT ‘Source’||’.’||S_FIELD||’=’||'{t_tab}’||’.’||T_FIELD as FILTERS FROM MAP_TABLE WHERE S_TABLE='{s_tab}’ AND T_TABLE='{t_tab}’ AND KEY_FIELD=’S’
”’)
cc_surr = df_surr.count();
var_filter = ”;
df1_surr = df_surr.to_pandas()
df1_surr[‘colB’] = ” AND “;
df1_surr.iloc[cc_surr-1, 1] = ” ”
df1_surr[‘FILTER’] = df1_surr[‘FILTERS’]+df1_surr[‘colB’]
df2_surr = df1_surr[‘FILTER’]
arr_surr = df2_surr.to_numpy()
arr_surr_key_fields = ”.join(arr_surr);
arr_tgt_k_fields_1/ arr_src_k_fields_1 – to get the primary key field, have used the below code.
df = session.sql(f”’
SELECT S_FIELD, T_FIELD FROM MAP_TABLE WHERE S_TABLE='{s_tab}’ AND T_TABLE='{t_tab}’ AND KEY_FIELD=’Y’
”’)
cc = df.count();
var_filter = ”;
df1 = df.to_pandas()
if cc>1:
df1[‘colB’] = “, “;
df1[‘colB’].iloc[cc-1] = ” ”
df1[‘SRC’] = df1[‘S_FIELD’]+df1[‘colB’]
df1[‘TGT’] = df1[‘T_FIELD’]+df1[‘colB’]
elif cc==1:
df1[‘SRC’] = df1[‘S_FIELD’]
df1[‘TGT’] = df1[‘T_FIELD’]
df2_SRC_1 = df1[‘SRC’]
arr_SRC_1 = df2_SRC_1.to_numpy()
arr_src_k_fields_1 = ”.join(arr_SRC_1);
df2_TGT_1 = df1[‘TGT’]
arr_TGT_1 = df2_TGT_1.to_numpy()
arr_tgt_k_fields_1 = ”.join(arr_TGT_1);
Final Leg
Once you constructed the Merge statement, you have to run it as below.
df = session.sql(f”’
{mrg_sql}
”’)
df.collect()
return f”{mrg_sql} is the MERGE QUERY and ran successfully”
To run the Stored Procedure: CALL AUTO_MERGE_SCD2(‘EMP_STAGE’,’EMPLOYEE’);
Output
END_DATE is updated for EMP_ID: 1 (SUR_KEY: 1) for today.
SUR_KEY 9 and 10 are newly added with START_DATE as today and END_DATE as future date.