
Today we will dwell into some basics and best practices to follow for any database design as well as for Coding. The key topics that I would like to emphasize today are following
- Coding Best Practices
- Data model Design Principles
- Best Query writing practices.
Before I move on to the topics, I would like to thank my previous organization manager, mentor @Kevin Owens who Is my best-known Architect and learnt quite a lot from Design aspects and following principles.
Coding Practices
Have you ever encountered queries or a code that is not formatted properly or written a code in hurry that does not follow standards and later you are asked to re-visit for either a bug-fix or enhancement? At that point of time what could have gone through you mind? You would say,” Yikes that’s a one crazy query/code that needs time for me to understand and fix/enhance it”.
Over the years of experience, I had come across such queries or code and gave me hard time to read and understand. This is the precise reason why some coding best practices are designed by Organizations and asked teams to follow. In the earlier days, there were no tools to format the code or Intelligent IDE’s that tell you better ways, now with technology evolving we are getting better suggestions to write the code.
Database languages such as Oracle PL/SQL, T-SQL does not have strict guidelines to code or format whereas languages like Python have strict guidelines to follow the format, but we still tend to ignore and follow some incorrect practices. So, lets dig into some examples and explore some good and best practices.
Now let’s say we see a query like this below.
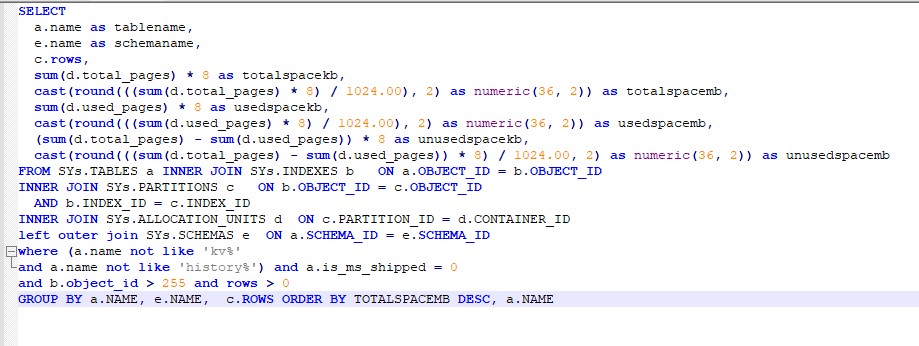
What do we observe from the above?
- The query is not formatted for better readability.
- Usage of mixed case in fields, Table, Schema.
- Usage of Alias with a,b,c.. which does not signify the Table Name
- Lacks readability in the query.
Now let’s look at the below formatted query and analyze what best practices were performed
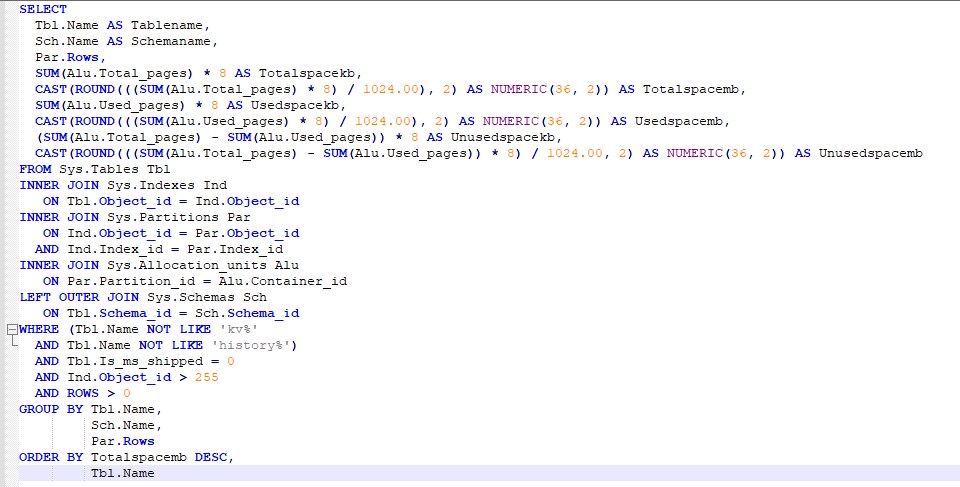
- The query is much readable with proper indentation followed
- Each Table is aliased properly, Say for Tables is given an alias as Tbl.
- The Alias names are much readable and signify what the underlying table meant to be.
- Keywords are Capitalized, Joins are properly aligned

Now let’s look at a simple Trigger that is not formatted properly
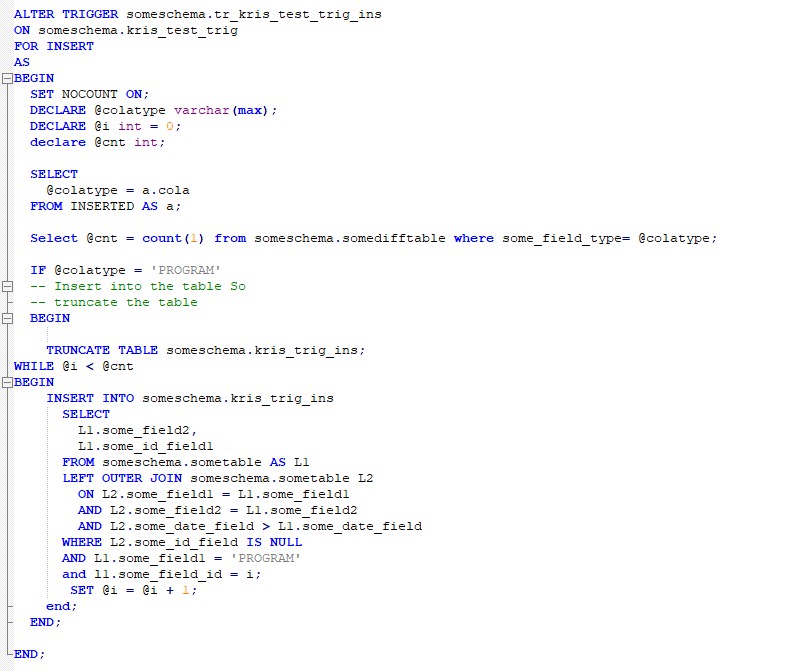
What do we observe here?
- No proper formatting of the code
- Using some variables that have no meaning
- No proper documentation to understand why looping is done.
Now, let’s look at the properly formatted code
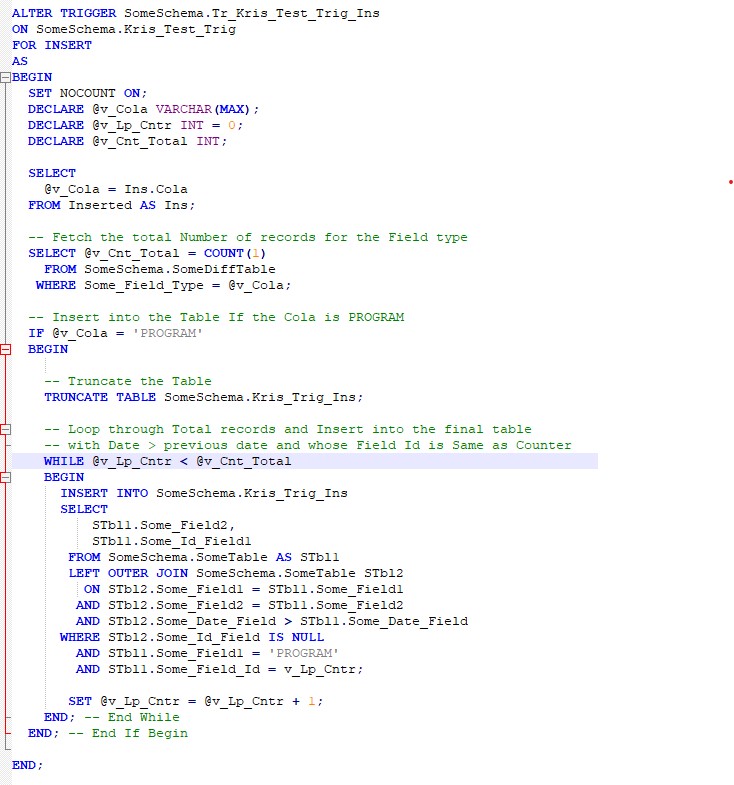
We do see following
- Properly formatted and Indented code
- Variable names are declared with proper meaning.
- Necessary documentation has been provided for code readability.
- Begin and End have been tagged accordingly.
- Tables are Properly Aliased.
- Order of the conditions were followed properly.
So finally based on the above let’s list some of the best practices at the coding level, this can be applied to any language as such
- Follow proper indentation in the code.
- Avoid using variables names with single character as they do not signify any meaning to them. So, use some fully qualified name Example for Counter declare it as either Cntr or v_Cntr (Where V => local variable)
- Give a brief one- or two-line description of what the program or the Query does if needed (Be brief).
- Init Capitalize the Variables for better readability.
- Make all keywords in Capitals.
- Default the variables as best practice.
- Remove any un-necessary variables that are not used in the code
- Init Capitalize the Function/Procedure/Trigger Names.
- Declare any parameter variables in the Function/Procedure starting with “p_ “
- If the language offers the direction of the parameter then signify the direction explicitly in the Procedure/Function as (Example: If we are passing Customer ID as Input then call the parameters as “P_In_Cust_Id” , If we are returning then call it as “P_Out_Cust_Id”, if Bi-directional then call it as “P_In_Out_Cust_Id”)
- If a variable has multiple scopes, then use the scope accordingly like l_<Variable> (l –> Local).
- Declare procedure with either sp_<Meaningful Procedure Name> Or up_<Meaningful Procedure Name>, Similarly for functions f_<Meaningful Function Name>
Data Model Design Principles
Every application stores their data in one or other form, traditionally certain databases are designed with Relational databases like Oracle/MY SQL/PostgreSQL. With evolving trends in data pattern and business requirements there has been instance where business and technology teams were looking towards No-SQL databases like Mongo DB etc. No matter which database that we choose from each of the database should follow some basic principles in defining the tables and others.
Let’s focus first on a relational database (Where this is predominantly used for various reasons like flexible SQL Queries, Analytics etc). When we talk about relational database we tend to talk about Normalization of the data, which implies organizing your data in the database. We come across 4 Normal forms
- 1NF: First Normal form, where you cannot have multiple attribute values but hold Single -valued attribute, you can see repetition of the data in the table (Example, if an employee has two phone Numbers you will see two records for same Employee ID, causing duplicity)
- 2NF: Second Normal form, it says Non-Key attributes should be dependent on a Unique Key (Called primary Key). So given a Key I should get just one record and not multiple, so if an employee has say two address, we will have two tables one with Employee and his/her details (That does not repeat) and Employee and Address.
- 3NF: Third Normal form, this allows or reduces data duplication and used to achieve data integrity. For instance, if two banking customers hold same address then we could see the Same address repeating twice in the Customer table for two unique Customers. If there is a change in address you end up updating two rows, so to avoid such situation you will have Address information in another table with Primary Key associated with that address and then tag the ID in the Customer table. This way when you need to update address you will only touch one table but not the other, keeping data integrity in view.
We also have other form called BCNF (Boyce Codd Normal form) which is advanced 3NF that talks about relationship between two parent tables.
Some regularly talked data model methodologies are
- Flat Model — single, two-dimensional array of data elements
- Hierarchical Model — records containing fields and sets defining a parent/child hierarchy
- Network Model — similar to hierarchical model allowing one-to-many relationships using a junction ‘link’ table mapping
- Relational Model — collection of predicates over finite set of predicate variables defined with constraints on the possible values and combination of values
- Star Schema Model — normalized fact and dimension tables removing low cardinality attributes for data aggregations
- Data Vault Model — records long term historical data from multiple data sources using hub, satellite, and link tables
Now, no matter whether we create data structures in Relational or Non-Relational (No-SQL), we need to follow some principles or practices to follow.
- Lets first focus on the table and fields
- Give a meaningful name to the table and avoid any acronyms. Example
- Good: CUSTOMERS/CUST_MASTER
- Avoid: CUST (Table that holds Customer details)
- Give a meaningful field name to the fields and should be self-explanatory (But avoid a long field). Example:
- Good: CUSTOMER_ID
- Bad: CUST_ID (Field that holds Customer Identification Number)
- Follow some of the below best practices on naming the fields.
- For any identification fields have the suffix of the field with _ID (Example: for Orders order ID give it as ORDER_ID)
- For any field that holds Date have the suffix of the field _DATE/_DT. Example Employee Start Date : EMPLOYEE_START_DATE/EMPLOYEE_START_DT Or Record End date as: TERMINATED_DATE/TERMINATED_DT
- Please note: If the database has field limit, then try to go with _DT to have meaningful name to the field.
- For any field that holds Time Stamp have the suffice of the field as _TIMESTAMP/_TS. Example: Updated Time Stamp UPDATED_TIMESTAMP/UPDATE_TS
- Please note: If the database has field limit, then try to go with _TS to have meaningful name to the field.
- For any field that holds Boolean have the field starting with IS_/HAS_. Example: Has Employee Mobile: HAS_MOBILE.
- For any field that holds Amount have field suffix as _AMT/_AMOUNT. Example: Order Amount: ORDER_AMOUNT/ORDER_AMT.
- Please note: If the database has field limit, then try to go with _AMT to have meaningful name to the field.
- For any field that holds Count have field suffix as _CNT/_COUNT. Example: Order Amount: ORDER_CNT/ORDER_COUNT
- Please note: If the database has field limit, then try to go with _CNT to have meaningful name to the field.
- For any field that says Primary key have a field suffice as _KEY. Example Customer Key (A field formed by combination of multiple fields like Customer Id and Create Date), CUSTOMER_KEY.
- Avoid defining the Primary Key field as Just “ID” this would not give a meaningful name to the column and not self-explanatory.
- Always give comments to the Table and Fields as part of the Design. This allows anyone looking at the dictionary from the tool can understand the context of the table and fields. Example: (Oracle Table)
- Give a meaningful name to the table and avoid any acronyms. Example
CREATE TABLE CUSTOMERS
(
CUSTOMER_ID NUMBER,
CUSTOMER_NAME VARCHAR2(100 CHAR),
CUSTOMER_ADDRESS_1 VARCHAR2(1000 CHAR),
CUSTOMER_ADDRESS_2 VARCHAR2(1000 CHAR),
CUSTOMER_ADDRESS_3 VARCHAR2(1000 CHAR),
CUSTOMER_STATE VARCHAR2(10 CHAR),
CUSTOMER_CITY VARCHAR2(100 CHAR),
CUSTOMER_ZIP VARCHAR2(20 CHAR),
CUSTOMER_PHONE VARCHAR2(20 CHAR),
CUSTOMER_RELATIONSHIP_START_DATE DATE,
CONSTRAINT PK_CUSTOMER_ID PRIMARY KEY (CUSTOMER_ID)
);
COMMENT ON TABLE IS 'This table holds Customer Information.'
COMMENT ON COLUMN CUSTOMERS.CUSTOMER_ID 'This holds the Customer ID, Unique Identifier of the Customer.'
COMMENT ON COLUMN CUSTOMERS.CUSTOMER_ADDRESS_1 'Holds the Customer First line of Address.'
COMMENT ON COLUMN CUSTOMERS.CUSTOMER_ADDRESS_2 'Holds the Customer Second line of Address.'
COMMENT ON COLUMN CUSTOMERS.CUSTOMER_ADDRESS_3 'Holds the Customer Third line of Address.'
COMMENT ON COLUMN CUSTOMERS.CUSTOMER_STATE 'Holds the Customer State.'
COMMENT ON COLUMN CUSTOMERS.CUSTOMER_CITY 'Holds the Customer City.'
COMMENT ON COLUMN CUSTOMERS.CUSTOMER_ZIP 'Holds the Customer Address Zip Code.'
COMMENT ON COLUMN CUSTOMERS.CUSTOMER_PHONE 'Holds the Customer Phone Number.'
COMMENT ON COLUMN CUSTOMERS.CUSTOMER_RELATIONSHIP_START_DATE 'Holds Customer relation start date.'
- Avoid breaking tables into too granular way, this causes more Joins and un-necessary complexity. Example
-
- Do: If you want to hold Organization information then create one table called ORGANIZATION and Key it by a Unique ID and with other Org Details. So, the table name would look like this
-
CREATE TABLE ORGANIZATION
(
ORGANIZATION_ID NUMBER
ORGANIZATION_NAME VARCHAR2(100 CHAR),
<ANY OTHER FIELDS>
CONSTRAINT PK_ORGANIZATION_ID PRIMARY KEY (ORGANIZATION _ID)
);
-
-
- DO NOT create one table that contains Just Organization Id and Name and other Table that holds Organization Id and other Details, this causes Un-necessary maintenance of the tables and Joins. As below
-
CREATE TABLE ORGANIZATION
(
ORGANIZATION_ID NUMBER
ORGANIZATION_NAME VARCHAR2(100 CHAR)
CONSTRAINT PK_ORGANIZATION_ID PRIMARY KEY (ORGANIZATION _ID)
);
CREATE TABLE ORGANIZATION_DETAILS
(
ORGANIZATION_ID NUMBER
ORGANIZATION_TYPE VARCHAR2(100 CHAR),
ORGANIZATION_ADDRESS VARCHAR2(100 CHAR),
<ANY OTHER FIELDS>
CONSTRAINT FK_ORGANIZATION_ID FOREIGN KEY (ORGANIZATION _ID) REFERENCES ORGANIZATION(ORGANIZATION_ID)
);
- Define and compute the summarization into their own tables and partition them accordingly to the desired grain and avoid dynamic complex computation for performance.
- De-Normalize the tables accordingly and as needed based on the Business functionality.
- Choose a Data-model and technology as per the business requirements. Example
- If the application is more performing OLTP then pick desired Normal Form and avoid constant updates on Indexed field.
- If its more of OLAP, then look towards Fact and Dimension table with pre-computed data for Analytical purpose.
- Where possible and if Materialized views supported by the database, try to use them. These are like a fixed tables which allow better performance. These are used for summarization. These can be used for both types like OLTP/OLAP.
- Use views very sparsely, as they are expensive and avoid any computation logic in the views and keep them as light as possible.
- Do not add too many indexes on a table this will cause slow down for the Inserts and Updates and there will be quite a maintenance behind scenes.
- Try to Partition the tables as necessary this allows the queries to run efficiently. Example, say we have a Transaction table which gets data daily then Partition the table by Date.
- Create Indexes with meaningful name and have them based on the Query that is been accessed but follow the step of Number of Indexes as listed above.
- For a NO-SQL database
- Form the Key where queries use most to retrieve the data in a well-defined range of rows. So start with most common values and end with granular. Say, you have a table that tracks the flights (Both arrival and departure) then define the key with Direction(Arrival/Departure), Followed by City and Time Stamp. This allows search on Arrival/Departure on a given city and timestamp in better manner. Separate with #.
- Try to consolidate related data into a Column Family for better consolidation of the data.
Query Writing Practices
In very simple terms a Query is simple request from the database that will return data that you asked. So, if we ask a simple question the answer would be quick and efficient, but when a query is asked on a complex topic, we end up answering back takes time. In terms of database the simple the query the faster the response, the complex the query the slower the response.
Say, if you want to fetch all employees in a department you can simply join necessary tables (Say Employee and Department) and return, but what if you try to overly complicate it by joining un-necessary table? The query will take while to return the data. In addition, there are some ground rules or best practices to write better and Optimal queries.
Let’s look some of the best practices in writing the query.
- Avoid fetching all columns from the tables Joined but fetch only those that are really needed. Example
- DO:
SELECT Tbl1.Field1, Tbl1.Field10, Tbl2.Field2 FROM SomeTable Tbl1 INNER JOIN SomeTable Tbl2 ON Tbl1.Key_Field = Tbl2.Key_Field WHERE Tbl1.Field1 = <Some Condition> - DON’T:
SELECT * FROM SomeTable Tbl1 INNER JOIN SomeTable Tbl2 ON Tbl1.Key_Field = Tbl2.Key_Field WHERE Tbl1.Field1 = <Some Condition>
- DO:
- Start with the table that is the primary focus is on (Example where we have an input) then follow the trail to fetch other data as desired.
- Join the tables in the order data is accessed rather Joining them haphazardly.
- Use ANSI Standard Joins to make the queries more compatible with various Relational databases and helps in minimizing touching the code during migration. Examples being
- INNER JOIN: Natural Join fetches only those that match on both sides (Based of a Key)
- LEFT OUTER JOIN: Fetches all records of the table on left hand side that match with right and fetches additional data that does not match to Right from the Left table.
- RIGHT OUTER JOIN: Fetches all records of the table on right hand side that match with left and fetches additional data that does not match to Left from the right table.
- FULL OUTER JOIN: Fetches all records from both left and right that match and does not match.
- Perform Joins on the tables as per the Index Column ordering to the best possible way to use the proper Index.
- Avoid user defined functions in Where clause as much as possible, they tend to slow down the queries. If need arises, ensure that the table that is used in the function is Indexed with no additional summarization or conditions.
- When joining two set of data together, if there are no duplicates in both data sets then use UNION ALL and avoid UNION. As Union tries to remove duplicates and sort the data which is costly in performance.
- Do not use DISTINCT clause in Sub-Query or UNION Clause in a Sub-query as they will be more expensive.
- Use Exists clause if the volume of your sub-query is high rather doing IN.
- Use IN in your Where clause where your sub-query has records less than 10.
- Use Merge (UPSERT) for optimal performance to update the Non Key values or Insert into the table.
- Use NVL (Oracle/Hive) Or ISNULL (SQL SERVER) if your where condition needs to fetch data on a field with Or Condition. Example
- DO:
WHERE NVL(Tbl1.Field1, Tbl1.Field2) = Tbl2.Field3This gives better performance - DON’T:
WHERE (Tbl1.Field1 = Tbl2.Field3 OR Tbl1.Field2 = Tbl2.Field3)This has slower execution due to OR Condition.
- DO:
- While writing the queries focus on the table volume and how much data is considered Vs thrown away due to Filter condition.
- If needed use Work tables to speed up the process (Only possible when in Procedures or Batch jobs) rather querying high volume by loading filtered data for usage later.
- Always perform Insert INTO with columns specified. See below some Good/Bad practices.
- Good: Having columns specified will allow table to grow horizontally with out effecting the insert (as long as new fields are Nullable)
INSERT INTO Customers (Customer_Id, Customer_Name, Customer_Address_1, Customer_Address_2, Customer_Address_3, Customer_State, Customer_City, Customer_Zip, Customer_Phone, Customer_Relationship_Start_Date) VALUES (Seq_Customers.NextVal, 'Krishna Vaddadi', '7231 Skiles River', 'Apt. 929', Null, 'MI', '29032', '789-456-2903', SYSDATE); - Bad: Any new field added will cause the Insert fail and needs amended.
INSERT INTO Customers VALUES (Seq_Customers.NextVal, 'Krishna Vaddadi', '7231 Skiles River', 'Apt. 929', Null, 'MI', '29032', '789-456-2903', SYSDATE);
- Good: Having columns specified will allow table to grow horizontally with out effecting the insert (as long as new fields are Nullable)
That’s it for today and hopefully this gives some insight on best practices and have a good read!