
There is a lot of confusion and hype out there regarding persistence technologies. It can be difficult to choose the right one. There are many considerations, and each situation requires thoughtful investigation. In this post, we’ll take a 10,000-foot view to help orient you in this landscape. To get the most out of this discussion, you’ll need a basic understanding of relational (SQL), document, and graph databases. We’ll discuss the trade-off between flexibility and performance and identify where these technologies fall on this spectrum. And finally, I’ll provide some recommendations and other resources to help you determine the best tech for the job.
What’s in a Name? Flexibility vs. Performance
SQL stands for “Structured Query Language,” and NoSQL stands for “Not Only SQL,” but for our purposes, it’s more useful to think of it as “No Structured Query Language.” SQL databases support a rich query language, and the data is structured in a generic form to support asking a wide variety of questions. Many NoSQL databases have a limited query language, and the data is structured to answer a limited number of questions. NoSQL is faster because it is optimized to answers fewer questions.
It’s really that simple. There isn’t a secret sauce that makes NoSQL faster than SQL. Query performance is a product of how closely your data structure matches the questions being asked. If the structure of the data matches the question, then the query provides the answer quickly. But when the question asked looks different from the structure of the data, transformations are applied, and “rendering” the answer takes longer. NoSQL databases can be faster than SQL because the question and answer are pre-rendered or baked-in into the data structure. So instead of querying the data with NoSQL, we are retrieving pre-defined answers to well-known questions. The degree to which queries are baked into the data structure varies by technology. Obviously, there are many factors to consider when evaluating performance, but recognizing that performance comes at the cost of query flexibility is a good place to start.
Pre-rendering Data
Pre-rendering data or baking the question and answer into the data structure is what makes NoSQL fast. But what does it mean to pre-render the data? Pre-rendering data is applying opinionated transformations before the data is persisted. Contrast this with persisting the data in a generic form and then applying an opinionated transformation when the data is accessed.
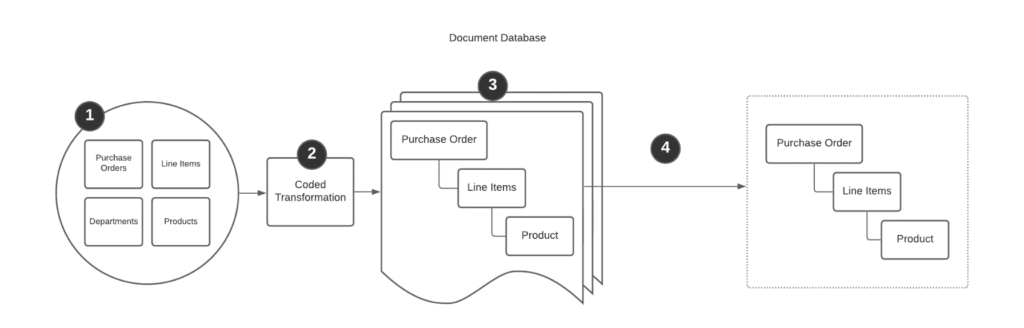
The image above shows the process of “pre-rendering” data into a NoSQL Document database. (1) The data in its “natural” form is (2) transformed into an opinionated form that matches the application’s questions. (3) The data is persisted, and when (4) accessed, no transformation is required because the data has been pre-rendered for our specific purpose. The answer to the question, “What products, line items, and metadata exist for purchase order X?” has been built into the data structure. This document can’t answer the question, “What products are in the shoe department?” For that, we need a different document.
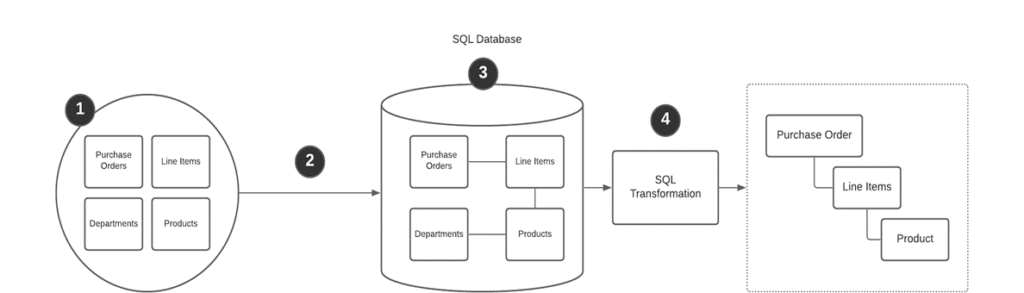
Contrast that with the image above of a SQL database with limited pre-rendering. (1) The data in its “natural” form (2) undergoes little to no transformation before it is (3) persisted into the database in a generic form. (4) When the data is accessed, it is transformed to match the structure required for the application. This real-time transformation is more expensive, but it is more flexible as the generic data can be transformed to answer various questions. This data structure can answer both, “What products, line items, and metadata exist for purchase order X?” and “What products are in the shoe department?” but not with the same speed and scale as a document database.

This is powerful knowledge because we can dramatically alter our application’s performance by changing where the data is transformed. There are many consequences and cascading effects when we do this, so this change should not be performed casually. A common side effect is denormalization, data duplication, and eventual consistency, requiring complex access patterns or synchronization logic.
And Then There Were Graphs
So far, we’ve discussed two database technologies at the extremes of the flexibility and performance spectrum, relational SQL databases and NoSQL Document databases. Graph databases are a relatively new offering in the NoSQL space. Some have suggested they are the ultimate database and can be used to solve any problem. This simply isn’t true. Like other NoSQL databases, graph databases are special-purpose tools that trade flexibility for performance. There are several different flavors of a graph database, but the most popular, and the one we’ll discuss here, is the Labeled Vertex Graph. This is what most people are thinking of when they say graph database. On the surface, a graph database might appear to be a relational document database. Combining the best of relational SQL with NoSQL documents. However, graph databases are not a superset of these technologies. Instead, they sit in between them on the spectrum of flexibility and performance. Like other NoSQL databases, a graph database’s unique value comes from “baking-in” certain optimizations and limiting the types of questions we can ask quickly.
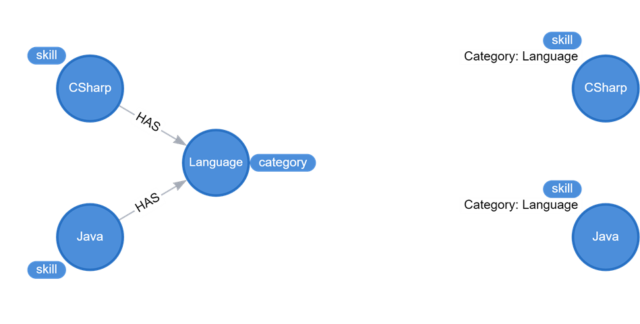
Consider the graph above. We have two different approaches to modeling the relationship between a skill and its category: edges on the left and vertex properties on the right. You might assume that the left graph is preferred because it models the relationships using an edge. But if you were to ask the question, “What skills exist in the language category?” querying the data on the left would be twice as expensive as querying the data on the right, assuming you’re running this query in an Azure Cosmos DB. Like other NoSQL databases, a graph database must bake-in the right query logic to perform quickly. And different vendors offer different optimizations. When modeling a graph database, it’s critically important to understand the questions asked of the data. We can then model it to answer those questions quickly by baking some of the query logic into the model’s structure.
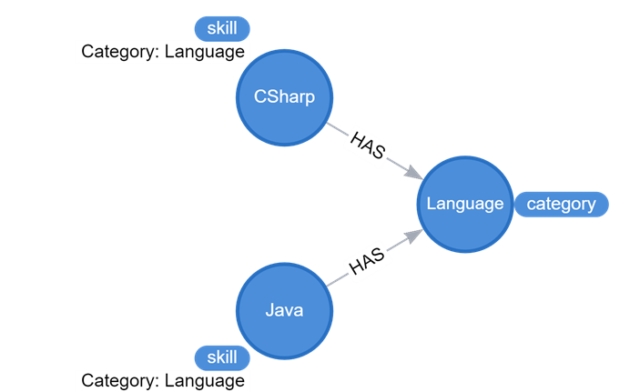
Graph databases have a rich query language and offer a lot of modeling flexibility. For example, by storing the category as an edge relationship and as a property on the vertex, we introduce additional query options, but we also introduce data duplication. Graphs are a great tool if you ask the right questions to the right model. If you’re wondering whether a graph is the right tool for your use case, here’s a simple question to help guide you: “Are the relationships more important than the data?” If they are, that’s a good indicator that a graph may be the right tool.
Summary
There is a large variety of databases in the NoSQL space. And different vendors have optimized their databases, baking in unique performance characteristics. Think of a relational SQL database as a swiss army knife and NoSQL databases as special-purpose, high-performance tools that must be used skillfully. Each database can perform well or poorly based on the structure of the data and the questions’ nature. Higher performance typically requires an understanding of the questions in advance. It bakes-in or pre-renders the answers into specialized data structures that more closely match the question’s structure; this provides better performance at the cost of flexibility. There’s no silver bullet. Matching a database to a domain problem requires a thoughtful evaluation of the questions you’ll be asking.
Our Approach
The Perficient custom development group specializes in the development of custom solutions. So “file > new project” is commonplace. Many of our clients are breaking new ground and creating unique products. This often means that we, and they, are learning about their product domain as we go. We delay decisions about persistence technologies for as long as possible, often building out portions of the application before committing to an approach. Once we better understand the needs and performance characteristics, we can select the right technology for the job. A relational SQL database is a common launching point because it provides more flexibility and can be modeled well without knowing all of the questions we’ll ask upfront. As features that require optimization are identified, we investigate NoSQL solutions that meet those specific needs. Many modern cloud solutions rely on various persistence technologies; SQL is still an excellent tool, and NoSQL provides great new options for managing data on a global scale.
We are technologists with a deep love for connecting people with software solutions that enrich their lives. Don’t hesitate to contact us to share your vision and discuss how we can help you deliver it.
Additional Resources
Here are some additional resources to help in your exploration of NoSQL.
SQL vs. NoSQL Explained – YouTube
A Skeptics Guide to Graph Databases – David Bechberger – YouTube