
One of the many benefits of using Red Hat OpenShift to manage your container workloads is the flexibility it provides to distribute and/or isolate workloads. There are many scenarios around this, but one that I like to regularly use when deploying a cluster is creating dedicated infrastructure nodes, and then moving the router function onto those nodes. I believe this helps simplify troubleshooting and provides more consistent network performance. In this post, I’ll describe the process for designating these nodes and moving the router workload onto them.
In this scenario, I’ve deployed my cluster in AWS with nine nodes: three master nodes and six worker nodes. Here’s what I see when I run “oc get nodes”. (PLEASE NOTE: Node names are made up for this post.)

I’m going to designate three of the worker nodes as “infra” nodes by editing their label. There are a couple of ways to do this, and it can be done from both the command line (CLI) and the web console. For simplicity, I’ll just show the CLI and pick the first three worker nodes on the list. I’ll edit the first worker node by typing:
![]()
I’ll look for the line that says:
![]()
And I’ll change it to be:

![]()
I’ll do this same thing for the next two worker nodes on my list. When I finish this, the results of the “oc get nodes” command will be:
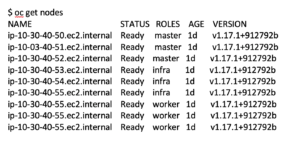
Now that I’ve labeled some nodes as infra nodes, I need to move my router pod workloads onto them. In OpenShift 4x, the router ingress function is managed by an operator, so I’ll need to make our changes to the operator. For this, I’m going to need to use the CLI and run this edit command:
![]()
If you look at the spec section of this yaml file, you should see:
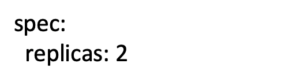
I’m going to change this to make the router pods run on the infra nodes and I’m also going to increase my replicas to three so that it should run on each infra node. When I’m done, the spec section will look like this:

After making this change, you should see the router pods redeploy and be running on the infra nodes. You can validate this by using “oc describe node” or by looking in the web console at the pods running in the “openshift-ingress” namespace.
One other important note: If you’re using an external load balancer in your environment, you’ll need to make sure that the wildcard domain for your OpenShift cluster has your infra nodes in its pool.
This is just a simple example of how you can easily use labels to place your OpenShift workloads where you want for the best performance and value.
For more information, visit our Red Hat partner page to learn more about our containers expertise with Red Hat platforms and tools. You can also connect with one of our Red Hat experts to learn how you can leverage these tools in your development efforts.