
The TechSEO Boost conference is one of the tightest technical conferences in the SEO industry, and consistently introduces new ideas and new approaches to our diverse field. There’s a ton of content packed into two days of learning; this will be an attempt to summarize some of the greatest moments ordered into a numbered list for readability and clickbait value. Since it’s about 10 hours of content, I’m going to break the main points down into a more easily digestible numbered list.
Full discloser: I watched the livestream, so any content that was off livestream I won’t be able to report on. Plus Eric Enge, our General Manager, presented our study – How Organic Search CTR is Impacted by Google’s Search Features, as we were one of the finalist for the research competition, where we were awarded 3rd place.
This article is also kind of a monster; you can ctrl+f and search “takeaway” to just get the general gist of each of the talks.
Breaking Down NLP for SEO: Paul Shapiro, Catalyst
Paul Shapiro broke down the basics of Natural Language Processing. This included in depth information on what libraries to use (heavily focused on Python), what text preprocessing is (cleaning up the data for use) and how the processing/ML actually works. It was an introductory course for NLP, using Python libraries.
A lot of the early work you do with NLP is turning an input of unstructured data into structured data which is more understandable by machines. Shapiro took attendees through how to break down jokes using NLP, focusing on normalization and the cleaning of data before getting into the generation. He showed how to vectorize the words to make them machine readable. There are three main types of vectorization: Count, n-Gram, and TF-IDF. Count Vectorizer looks at how many times a term or n-gram appears in one part of the corpus, and represents as a positive integer; TF-IDF creates a score of how many times a term appears in one part of the corpus, and how many times it appears in the corpus as a whole.
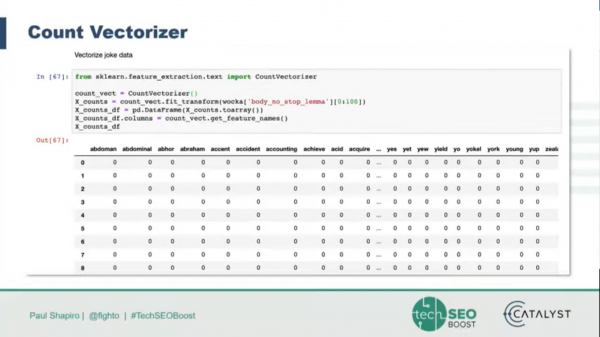
Learn more:
https://nltk.org
https://spacy.io
https://github.com/niderhoff/nlp-datasets
https://github.com/pshapiro
Main takeaway: The uses for NLP are limitless. Be sure to clean your data, figure out the right methods to use, and experiment to get great results.

Apps Script for SEO: David Sottimano, Keyphraseology
David Sottimano did a deep dive on how to use JavaScript and Google Apps Script and Google Sheets to get awesome SEO results. Sottimano showed how to replace clumsy nested functions with more streamlined JavaScript custom function. He also showed how to create legible, clear, functional, evergreen scripts to make SEO analysis far easier. Sottimano shared his code, and several places to learn more. Sottimano also argued for the size of Sheets, as Google Sheets will be able to connect to BigQuery to work with billions of rows in sheets.

Learn more links:
https://www.slideshare.net/dsottimano/techseo-boost-apps-script-for-seos
https://bigml.com/
https://pulse.appsscript.info
Main takeaway: You can extend Google Sheets with JavaScript code to get great SEO results and reports. Google Sheets’ traditional weaknesses against Excel (size and querying ability) can be solved by using scripts and eventually BigQuery.
When You need Custom SEO Tools | Nick Vining, Catalyst; Claudia Higgins, Argos; Derek Perkins, Nozzle; Jordan Silton, Apartments.com; JR Oakes, Locomotive
This was an awesome panel, especially since I’m part of Perficient Digital’s internal tools team—custom SEO tooling is a subject near and dear to my heart. They discussed how to stitch together data from already existing tools to do heavy lifting and data collection and focus on adding value and reducing your own hours. They also discussed how to communicate with executives and marketing teams, and how to show your credibility with executives.
They also discussed how to share advances in technical SEO and advanced tooling. Automate 20% of the work—don’t try and automate all the way to the end. Trust your experts to take it the rest of the way. Take the repetitive workload from SEOs and add value that way. Add value and productivity. If there’s something you feel like you need to build, wait; come up with ideas on how to approach the problem.
Main takeaway: Tools are great, but you should always remember to look at the page and use basic SEO skills. Share your discoveries in using Python on Github. Ask yourself several times if you need a tool for a task, if there’s a tool you can already use, and what the best way to implement that tool might be.

Keynote: Bias in Search and Recommender Systems | Ricardo Baeza-Yates, NTENT
Ricardo Baeza-Yates talked about information retrieval and query analytics. He talked about the history of relational databases, from 1970 onwards, and information retrieval.
Baeza-Yates talked about bias; statistical, cultural, and cognitive. He noted that Machine Learning systems tend to reinforce their own biases; it takes a lot of time and research to try and de-bias the input, the algo, and the output. Systems don’t need to be perfect, they just need to be better than we are—but the only way to get to that point is through a lot of work. Bias is almost always baked into data.
Takeaways: Don’t fail at the end, fail on the way. Be aware of bias in your systems, and try and understand it, balance for it, and remove it as much as you can. Be aware of things like different metrics competing against each other.

And then there was a reception, where I assume that attendees talked about Python/JavaScript/schema while shaking hors d’oeuvres.
Googlebot & JavaScript: A Closer Look at the WRS | Martin Splitt, Google
Day 2 began with Martin Splitt giving a deep dive into the Web Rendering Service for Googlebot. He began by explaining rendering, and what parsing into the DOM tree actually looks like. This includes the process of layouting—laying out where things go on the page, and how Google slowly builds up the page. The Google indexing system is, fundamentally, a bunch of different micro-services that chat to each other.
The Google Indexing Pipeline includes the elimination of duplicates, crawling, parsing links, parsing robots, the Web Rendering Service, and parsing the content. Google rejects service workers and permission prompts and doesn’t paint the pixels. Their rendering time is down to mere seconds in most cases.

Some other interesting things we pulled out are that Google doesn’t paint the page, and that cookies are overwritten using a fake cookie (since some sites use cookies to function,) but they aren’t persisted.
Main takeaways: Google fakes cookies, and doesn’t paint the page, just looks at how the code fits together. The “rendering” is more like sending information about what the page looks like than actually painting the page.

More info: http://www.evolvingseo.com/2019/12/09/112-martin-splitt-interview/
What I Learned Building a Toy Example to Crawl & Render like Google | JR Oakes, Locomotive
JR Oakes’ talk complimented Splitt’s. He spoke about what it was like to build his own toy internet and web crawler/renderer. He provided an overview of the crawling landscape, key crawler components, how he built a toy internet, and how he built a crawler/renderer.

This talk was fascinating. We have our own proprietary crawler, so comparing our process with Oakes’ was really interesting. Some key learnings I found interesting were: min hashes are an effective way of deduping content, that really, everything should be cached to reduce latency, and that URL normalization is handled at the parser for this model. Oakes built a toy internet out of three simple sites, making a faux PBN to get different topics and info from each site. He learned that applying PageRank to similar document clusters is an effective way of picking the right one, and BERT models need most of the content.
Main takeaways: Crawlers have a ton of components to be robust, efficient, and scalable. (A lot of this talk wasn’t soundbite-able.) Building one yourself can teach you a lot about how Google sees the web.
More info:
https://web.stanford.edu/class/cs276/handouts/lecture18-crawling-6-per-page.pdf
https://github.com/jroakes/tech-seo-crawler
Faceted Nav: (Almost) Everyone Is Doing it Wrong | Frank Vitovitch, Botify

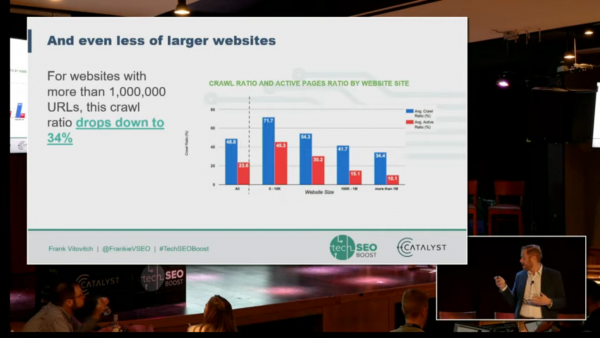
Frank Vitovitch from Botify talked faceted navigation problems; why faceted navigation causes problems, facet handling methods and pitfalls, and solutions. Culling URLs can improve traffic; removing faceted URLs can improve other pages without necessarily killing long tail queries.
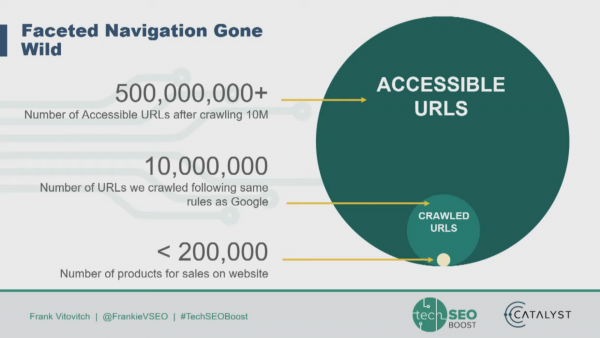
There is no perfect solution for faceted navigation, and most out of the box platforms aren’t SEO friendly when it comes to faceted navigation. You should look at what pages are being visited by users and which are only being visited by Googlebot. He also discussed how to cut URLs down and clean up a site structure.

Main takeaways: Faceted navigation is an art, which is ever evolving; ensure the pages you have that are indexable are worth indexing, using analytics and data, and then have a plan to deal with the rest.
Generating Qualitative Content with GPT-2 in All Languages | Vincent Terrasi, OnCrawl
This talk by Vincent Terrasi was really cool; he discussed content generation using GPT-2. GPT-2 is a language model from OpenAI, which is supposed to be able to generate coherent text one word at a time. With use cases like image captioning, visual Q&A, abstractive summarization, and full article generation, generating text and content is super useful for automating important text tasks at scale. Machine learning means this kind of content generation will be more readable and useful for users.

Terrasi explained how BERT and attention models work; that they identify important patterns. He then showed how he set up, trained, and fine-tuned a model for generating text.
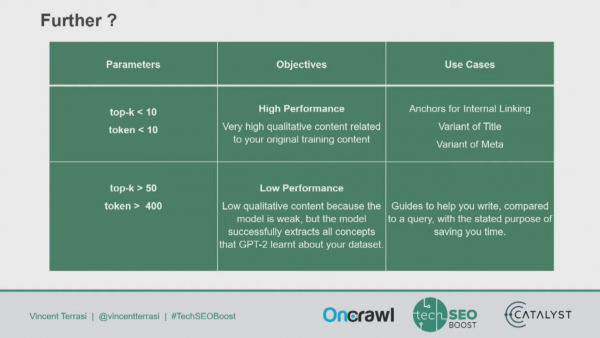
Main takeaways: 2019 is a great year to be using machine learning to understand and generate text, and machine learning has a ton of language implications and use cases.
The Ultimate Guide to Pagination for SEO | Tobias Schwarz, Audisto
Good pagination is a compromise between structure, usability, and design; so began Tobias Schwarz’ talk on the Ultimate Guide to Pagination. He discussed why pagination gets used, and pagination implementation problems.

He went through several different ways to implement pagination, and the distribution of PageRank and CheiRank across pages using these different methods.
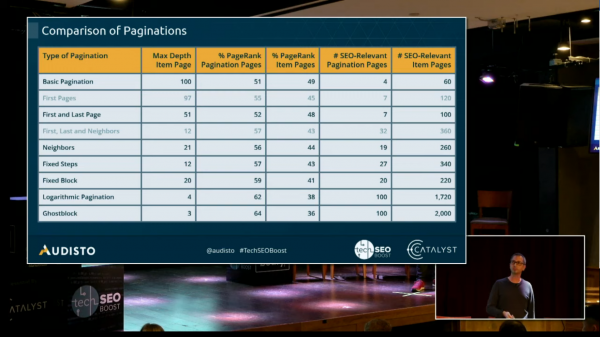
Schwarz broke down methods by site type. For ecommerce sites, use subcategories for category trees, to redistribute PageRank, and push users further into the sales funnel. For forums, ensure that threads link to the first page (which defines the topic), the last page (recent discussion) and links to pagination pages with Good, Relevant answers. For news sites, use stable pagination for Chronological Content—turn the pagination around, have the first page be marked with the highest number, and oldest items on “page 1”—this keeps news item pagination more stable, since the pages don’t have to change when new articles become available.
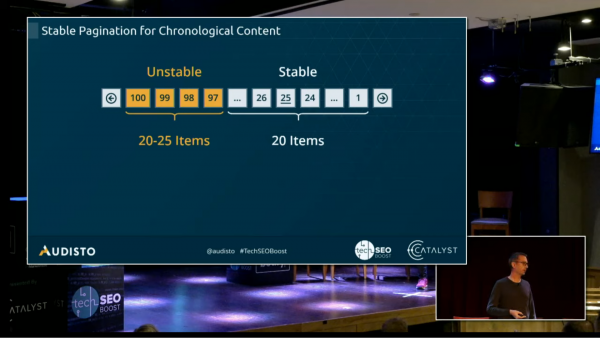
Main takeaways: Consider how pagination affects PageRank, and how your users and content will change how the pages link to each other. Don’t necessarily settle for traditional pagination—think about what will be best for users and crawlers.
The User is The Query: The Rise of Predictive Proactive Search | Dawn Anderson, Bertey
Dawn Anderson talked about proactive search and how search is becoming more personalized/how user search patterns are changing. She referred to Google Discover as a place where Google is looking heavily at personalization and user interest.

She notes that for “cold queries”, where the intent is unknown, Google needs to provide diverse results, to cover many kinds of intent. After the user starts working on query refinement they become “the human in the loop”– tt’s the user’s move next. Query intents can change based on time, location, events, etc. User needs are becoming queries, with collaboritive filtering giving users content similar to their interests.

Main takeaways: To understand queries, you need to understand users, affinitiy groups, audiences, tasks, micromoments and more; you should be user to improve and update evergreen content.

Research Competition
Mike King from iPullRank presented the Research Competition for TechSEO Boost.
Data on How Search Features Impact CTR | Eric Enge from Perficient Digital (Us!)
Eric presented some of our research on how the appearance of different search features can impact Click Through Rate on the SERPs. Here is the link to read the study.
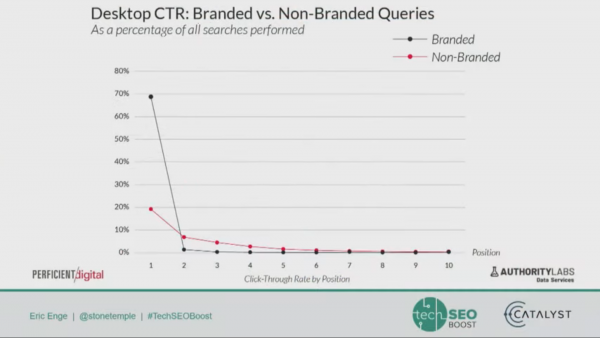
Main takeaways: Image Carousels increase Click Through Rate, depending on position; search features can really affect CTR.
Taking JavaScript SEO to the Next Level | Tomek Rudzki, Onely
Tomek Rudzki found that 80% of major ecommerce sites use JavaScript to generate crucial content, but that content doesn’t necessarily get crawled or indexed by Google.
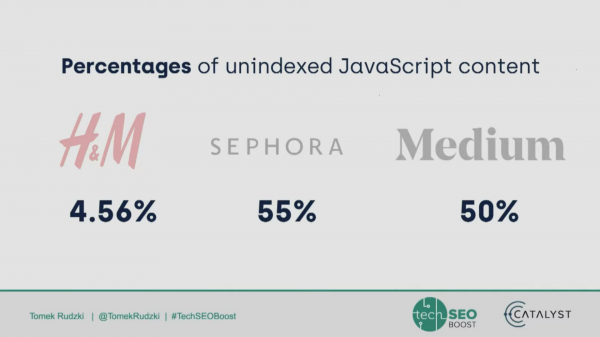
Main takeaways: JavaScript SEO is still important, even as Google gets better at crawling and indexing JS.
Generating Qualitative Content in All Languages | Vincent Terrasi, OnCrawl
Vincent Terrasi hoped to improve the quality of content created by humans using qualitative methods and machines. He went into this in more detail in his talk.
Main takeaways: Machine learning can help add value to human created content.
Ranking Factors Going Causal: Regressions, Machine Learning, and Neural Networks | Micah Fisher-Kirshner – Turn/River Capital
Micah Fisher-Kirshner spoke about ranking factors, ranking factor studies, and the problems with correlation studies. He pointed out that just showing a correlation and saying “Correlation doesn’t equal causation” isn’t enough; doing work like splitting the data and testing it again to see if the correlation holds is really important.
Fisher-Kirshner points out that data collection needs to be correct, consistent, with bad data removed, and collected over a long period of time. He points out to temper claims; check for outliers, self-selection bias, and other problems that can come up so you don’t come to a bad conclusion.


Main takeaways: We cannot analyze Google’s algorithm with simple correlations: calculate interactions, cross validate your data, and peer review your results. Take time and effort to get things right.
Advanced Analytics for SEO | Dan Shure, Evolving SEO; Aja Frost, HubSpot; Colleen Harris, CDK Global; Jim Gianoglio, Bounteous; Alexis Sanders, Merkle
This panel discussed advanced analytics; how to use analytics to inspire people to get things done and get SEO results. Aja Frost discussed using analytics to solve a content cannibalization problem. Colleen Harris similarly used analytics to organize users by intent, as well as using custom funnels and behavior flow to understand user patterns. Jim Gianoglio talked about how to measure AMP Pages, and user data being inflated in analytics by AMP, and suggested AMP-Linker as a solution. Alexis Sanders talked about dark traffic, and how to deal with that; she suggested going into the real-time report, and enter the sites different ways to see how it’s reported, as well as using Log Files (we’re big fans of Log File analysis here.)
Harris talked about mobile traffic and speed; she suggested using your customer’s actual data to understand site speed. Gianoglio brought up ITP.2; Safari is capping browser cookies to stay for 7 days. Frost suggested looking at as many data sources as possible, to see how trends work across data platforms.
Main takeaways: Don’t just talk about traffic: do you have engaged customers? How are you tracking them? How reliable is your data? How can you check the reliability of your data, and how can you make it more reliable?
Crawl Budget Conqueror – Taking Control of Your Crawl Budget | Jori Ford, G2
Jori Ford talked about crawl budget; asking how Google sees crawl budget, factors in managing it, quantifying it, and fine-tuning. Crawl Budget = Crawl Rate x Crawl Demand. Crawl rate is a variable thing, based on (server response time x time)/error rate. Crawl demand is popularity x freshness.

Ford ends up with an equation, that looks like this:
Crawl Budget = {Avg. ttfb x duration/ %server error} x {{CTR} x {Avg Time b/t Updates}}
The key factors for managing crawl budget include: Time to First Byte, Error Rate, Click Through Rate, and Freshness. Ford went through steps to quantify your crawl budget; Determine the number of pages you expect, use log files to figure out what pages are being crawled, check number of crawled pages and frequency of crawling, using Excel, SQL, and/or Log File Analyzer tools. Finally, segment data by type; page type, crawl allocation, active vs. inactive, and not crawled. To calculate crawl budget, you can use the equation (Average number of Crawled URLs x Frequency)/Time.
To conserve your crawl budget, prune non-money pages, de-index duplicated pages, remove pages that aren’t on your XML sitemap (if your sitemap is optimized), and remove error pages.

Main takeaways: Google has limited resources. You can help Google crawl the best parts of your site by optimizing for the things that determine crawl budget that you can control.
Technical Link Building | Gareth Simpson, Seeker Digital
Gareth Simpson covered link building with machine learning, and NLP productivity hacks. Good links are a major element in SEO. The link strategy he outlines includes analysis informing strategy, then creating content marketing campaigns for outreach, and quality assuring the site. Outreach includes contact research, negotiations, and prospecting. This goes to publishing and then monitoring; a pretty standard link building process.
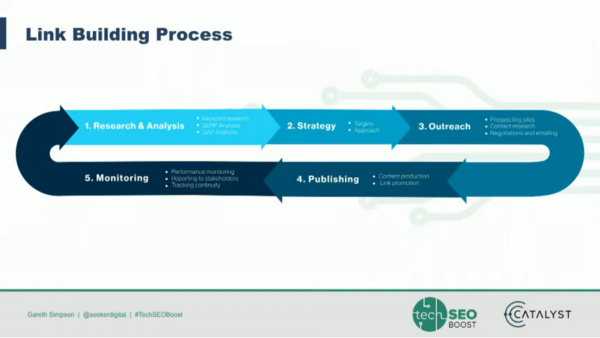
Link building is hard to scale, requires difficult project management, it’s pretty mundane work, and there’s a ton of data to process. Simpson found that 12.5% of staff time is lost in data collection—streamlining the data between all the different sources to understand good results. Their team uses Natural Language Processing to classify text, automating monotonous tasks.
Simpson suggests using IBM Watson and MonkeyLearn, as well as zapier. They prototype with high level APIs, and then use lower level APIs in production to lower cost. You can use automation to get contact information, building a list of contacts by category, email filtering, and generally cutting through the noise.


Main takeaways: Map out your link building process, interconnect platforms, and automate decisions with NLP.
Main Takeaways for TechSEO Boost
NLP:
Ensure that your data is clean, and structure your data well. Think about the kinds of algorithms that you’re going to use. Try using things like SpaCy, Pandas, TF-IDF. Especially think about your data; how machines can understand it, what kinds of biases might be in the data already, and what kinds of information you can get out of that data.
Automation:
You can use JavaScript and automation to expand the abilities of Google Sheets. You can use Machine Learning to supplement humans. Some technical knowledge can take away a ton of tasks that are dull or irritating, freeing up time for people to work on the elements that take more brain power/creativity/are less monotonous.
Tooling and automation are powerful, but you need to be sure to create them with your users in mind, and be prepared to prove their value. You can use automation to check and generate content, understand your data, build links, and tons more; just make sure that you have the right tools.
Sites:
Crawlers are a complicated thing: Google’s crawler has to manage a ton of moving parts to be able to accurately crawl and render pages. Crawlers in general have a difficult job of parsing the internet, and the job of SEOs is to ensure that we are feeding crawlers data in a machine-readable package. Often, machine readable sites are better for users too– faceted navigation can be made better for users and machines by thinking about the more important parts of a site.
Overall:
SEO is shifting; tools and tech know how aren’t just about giving people advice with regards to semantic HTML, but are about creating crawlers, using NLP and machine learning, toolifying, and experimenting, to create better sites for users and crawlers and less work for content creators, all the while keeping a close eye on the results.