
This blog post will provide an overview on the following topics:
- What is Amazon Redshift?
- Amazon Redshift Data warehouse
- Data Warehouse System Architecture
- Connecting SQL Client to Amazon Redshift Database
- Connecting to a DB Instance by Running Postgre SQL DB Engine
- Testing as a part of Amazon warehouse
- Amazon Redshift – a shift from conventional data warehousing?
What is Amazon Redshift?
Amazon Redshift is a completely managed, petabyte-scale data warehouse service in the cloud. You can start with just a couple hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers.
The first step to create a data warehouse is to launch a set of nodes, called an Amazon Redshift cluster. After you provision your cluster, you can upload your data set and then perform data analysis queries. Regardless of the size of the data set, Amazon Redshift offers fast query performance using the same SQL based tools and business intelligence applications that you use today.
Amazon Redshift Data Warehouse:
An Amazon Redshift data warehouse is an enterprise-class relational database query and management system.
Amazon supports client-based connections for various different applications like BI, Reporting data and other analytical tools.
Data Warehouse System Architecture:
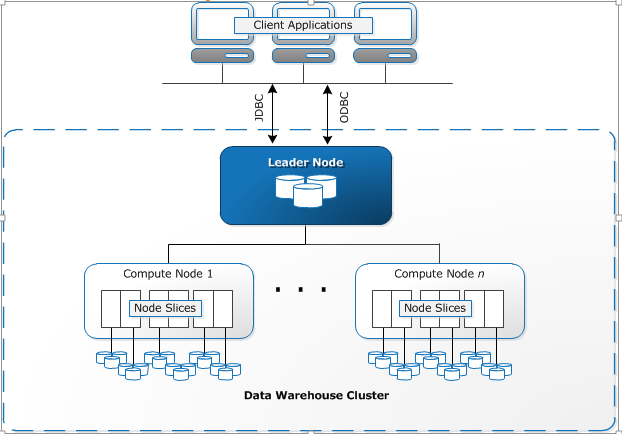
Connecting SQL Client to Amazon Redshift Database
Amazon Redshift integrates with various data loading and ETL (extract, transform, and load) tools and business intelligence (BI) reporting, data mining, and analytics tools. Amazon Redshift is based on industry-standard PostgreSQL, so most existing SQL client applications will work with only minimal changes.
Amazon Redshift communicates with client applications by using industry-standard SQL JDBC and ODBC drivers.
Amazon Redshift creates one database when you provision a cluster. This is the database you use to load data and run queries on your data. You can create additional databases as needed by running a SQL command
A cluster contains one or more databases. User data is stored on the compute nodes. Your SQL client communicates with the leader node, which in turn coordinates query execution with the compute nodes.
Amazon Redshift is a relational database management system (RDBMS), so it is compatible with other RDBMS applications. Although it provides the same functionality as a typical RDBMS, including online transaction processing (OLTP) functions such as inserting and deleting data, Amazon Redshift is optimized for high-performance analysis and reporting of very large datasets. Amazon Redshift is based on PostgreSQL 8.0.2.
The data available in the various distributed databases which are stored on clusters can be tested using any SQL client tool.
The connection between the Amazon Redshift cluster and the desired SQL client tool (PostgreSQL) has to be established for querying or accessing any table.
The JDBC URL of the cluster needs has to be identified. This can be identified by following the below steps:
- Login into the AWS Management Console and open the Amazon Redshift console
- At top right, select the region in which you created your cluster.
- In the left navigation pane, click Clusters, and then click your cluster.
- On the Configuration tab, under Cluster Database Properties, copy the JDBC URL of the cluster.

Format of the JDBC URL:
jdbc:redshift://endpoint:port/database
| Poll Results for What industry are you in? | ||
|---|---|---|
| Start Time: April 3, 2018 12:13:22 PM MDT | ||
| Total Responses: 222 of 428 (52%) | ||
| Results Summary | ||
| Answer | Total Number | Total % |
| Automotive | 7 | 0.03 |
| Energy and Utilities | 14 | 0.06 |
| Financial Services and Insurance | 47 | 0.21 |
| Healthcare and Life Sciences | 60 | 0.27 |
| Manufacturing | 14 | 0.06 |
| Retail | 22 | 0.1 |
| Other | 58 | 0.26 |
Connecting to a DB Instance by Running Postgre SQL DB Engine:
Any SQL client can be used to connect to the DB instance once Amazon provisions the DB instance
You can use the AWS Management Console, the AWS CLI describe-db-instances command, or the Amazon RDS API DescribeDBInstances action to list the details of an Amazon RDS DB instance, including its endpoint. If an endpoint value is myinstance.123456789012.us-east-1.rds.amazonaws.com:5432, then you would specify the following values in a PostgreSQL connection string:
For host or host name, specify
myinstance.123456789012.us-east-1.rds.amazonaws.com
For port, specify
- 5432
Two common causes of connection failures to a new DB instance are:
- The DB instance was created using a security group that does not authorize connections from the device or Amazon EC2 instance where the PostgreSQL application or utility is running. If the DB instance was created in a VPC, it must have a VPC security group that authorizes the connections. If the DB instance was created outside of a VPC, it must have a DB security group that authorizes the connections.
- The DB instance was created using the default port of 5432, and your company has firewall rules blocking connections to that port from devices in your company network. To fix this failure, modify the instance to use a different port.
If you have difficulty connecting to the DB instance, the problem is most often with the access rules you set up in the security group you assigned to the DB instance.
Testing as a part of AWS:
Once the DB connection is up and SQL client is connected to the DB instance, all ETL/SQL validations can be done using AWS.
- Metadata validations –
There are various system tables associated with AWS to validate the Metadata of tables. Below are the system tables
- PG_DEFAULT_ACL – Stores information about default access privileges.
- PG_EXTERNAL_SCHEMA – Stores information about external schemas.
- PG_LIBRARY – Stores information about user-defined libraries.
- PG_STATISTIC_INDICATOR – Stores information about the number of rows inserted or deleted since the last ANALYZE. The PG_STATISTIC_INDICATOR table is updated frequently following DML operations, so statistics are approximate.
- PG_TABLE_DEF – Stores information about table columns. You can use SVV_TABLE_INFO to view more comprehensive information about a table, including data distribution skew, key distribution skew, table size, and statistics.
- Table definition and structure is the more frequently used Metadata check for an ETL tester
Table Columns listed for PG_TABLE_DEF:
What industry are you in?
| Answer | Total Number | Total % |
|---|---|---|
| Automotive | 7 | 0.03 |
| Energy and Utilities | 14 | 0.06 |
| Financial Services and Insurance | 47 | 0.21 |
| Healthcare and Life Sciences | 60 | 0.27 |
| Manufacturing | 14 | 0.06 |
| Retail | 22 | 0.1 |
| Other | 58 | 0.26 |
| Total Responses: 222 of 428 (52%) |
SVV_TABLE_INFO:
Shows summary information for tables in the database. The view filters system tables and shows only user-defined tables. You can use the SVV_TABLE_INFO view to diagnose and address table design issues that can influence query performance, including issues with compression encoding, distribution keys, sort style, data distribution skew, table size, and statistics.
Table Columns – SVV_TABLE_INFO
[table “11” not found /]- Null check validations –
Syntax: expression is [NOT] NULL
IS NULL
Is true when the expression’s value is null and false when it has a value.
IS NOT NULL
Is false when the expression’s value is null and true when it has a value.
- Duplicate check validations
- Data transformation logic validations – Follows same logic as any other ETL Mapping logic
- Data Integrity validations – Data validations to validate accuracy of data
- Data Completeness validations – Count/Aggregate function checks to validate completeness of data loaded
- Initial/History load validations – One time data load to validate the history load
- Incremental validations – Incremental loads to validate data being loaded either on daily/weekly/monthly basis
All these validations form a standard part of ETL Data warehouse testing. All these validations & checks can be performed as a part of ETL testing
Data Loading:
- Using a COPY Command to Load Data
- Updating Tables with DML Commands
- Updating and Inserting New Data
- Performing a Deep Copy
- Analyzing Tables
- Vacuuming Tables
- Managing Concurrent Write Operations
A COPY command is the most efficient way to load a table. You can also add data to your tables using INSERT commands, though it is much less efficient than using COPY. The COPY command is able to read from multiple data files or multiple data streams simultaneously. Amazon Redshift allocates the workload to the cluster nodes and performs the load operations in parallel, including sorting the rows and distributing data across node slices.
Amazon Redshift – A Shift from Conventional Data Warehousing?
Whenever a new technology needs to be implemented, technology & Infrastructure aside, costs have to be taken into account.Amazon claims the cost of Redshift is under $1000 US per Terabyte, per year. So many organizations could quite easily keep their core data warehouse in the cloud. Of course at $1000/TB/year that means you’ll be paying at least $1 million/year for a Petabyte data warehouse. But if you are working at Petabyte scale and when you factor in the hardware, storage, personnel/management, power and other costs of running such a large warehouse on premise it isn’t really as expensive as it seems.
The advent of Amazon Redshift doesn’t necessarily mean that the use of conventional Data Warehouses is bound to reduce, but it offers organisations who have been trying to run their Data Warehouses on conventional models and have experienced performance issues, a choice to experiment with – A new alternative!