
Recently we published data that suggests that Google does NOT use Chrome data to discover new URLs for crawling. That surprised a lot of people because most assume that Google uses every possible source to find new content. Today, I’m publishing the results of a study that takes this process one step further.
In this test, we looked to see if Google is using Google Analytics to discover new URLs for crawling.
Brief Methodology Note
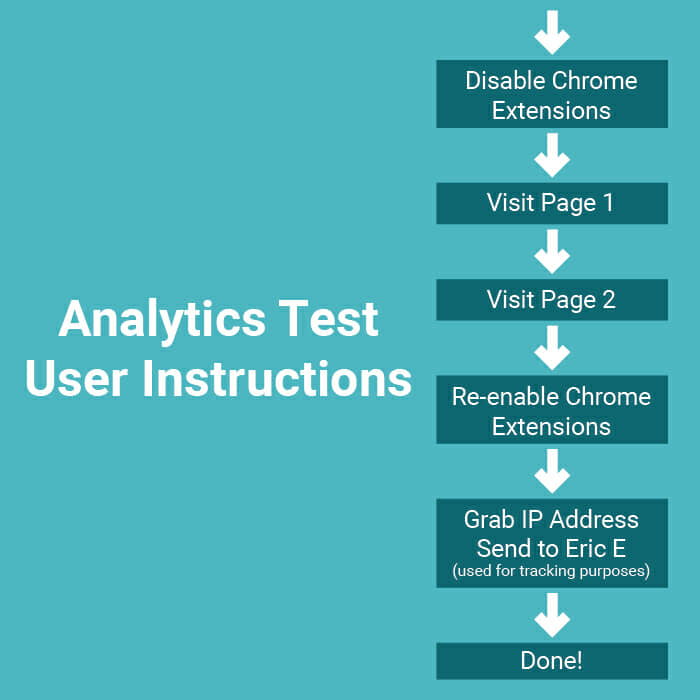
In short, we uploaded four pages containing Google Analytics code on two sites that Google didn’t know about, and then had a bunch of people visit some of those pages from a Chrome browser. We limited access to Chrome so we could provide the test team with simple instructions on how to disable all their add-on extensions, since these might complicate the test.
Since there was Google Analytics (GA) code on the pages, loading them should execute that code, and this should let Google know about the existence of the pages. Therefore if Google is using GA to discover new content, they might decide to crawl the new pages. Once the visits were complete to the test pages, we sat back and waited to see if Googlebot came to visit them. Skip to the next section unless you want to see the process in more detail, as is defined next. Here are the gory details:
- Created eight brand-new articles as webpages. We used four of these as test pages, and four of them as control pages.
- Uploaded two test pages and two control pages to “Site 1” and two test pages and two control pages to “Site 2” by direct FTP to the site’s web server.
- Waited a week to make sure nothing went wrong, causing Googlebot to visit. We checked the site log files for each to make sure that no Googlebot visits occurred.
- Enlisted 36 people to participate in the test.
- Split them into two groups, which I’ll call “Group 1” and “Group 2.”
- Had the participants follow this process:
- Open Chrome
- Go into settings and disable all their extensions
- If they were in Group 1, have them paste the URL of the first test page on Site 1 in their browser and then visit it
- If they were in Group 1, have them Paste the URL of the first test page on Site 2 in their browser and then visit it
- If they were in Group 2, have them paste the URL of the second test page on Site 1 in their browser and then visit it
- If they were in Group 2, have them paste the URL of the second test page on Site 2 in their browser and then visit it
- Reenable their extensions after completing the steps above
- Send their IP address to me to allow me to check that no errors occurred for each user
- Checked the log files every single day until a full week after the last user completed their steps. Took note of whether anyone (or any bot) visited either the test pages or the control pages.

The reason for the control pages existing was simply to make sure we did not have some error in the upload process. If we had seen the test pages get crawled and indexed by Google, we would then check the control pages to see if they were also crawled and indexed. If they were also crawled, that would indicate an upload process error. No views of either control page ever occurred, either by humans or bots, so this confirmed that our upload process worked.
So what happened with the test pages?
The Results
The results are pretty simple: Googlebot never visited any of the test pages.
[Tweet “Carefully controlled study found no evidence Google uses Google Analytics for URL discovery”]
Summary
Bear in mind that this test was specific to testing if Google used Google Analytics (GA) to discover new URLs. This does not mean that they don’t use GA data for other purposes. But, considering the results of our Chrome test, and the earlier test we ran regarding Smartphone clipboards, Google does not appear to be as hungry to discover new content as most people assume. My belief is that Google is not that interested in discovering content that is not benefitting from other ranking signals, such as links.
Thanks to the IMEC Labs group for their assistance on this test, and to the IMEC board of Rand Fishkin, Mark Traphagen, Annie Cushing, and Dan Petrovic for their guidance. Please follow all of them and me, Eric Enge for more info on IMEC tests in the future!
Useful Information all the time 🙂
Nice Experiment, Got some amazing information here.
Good information to know. I think this comment by you hits the nail on the head.
“My belief is that Google is not that interested in discovering content that is not benefitting from other ranking signals, such as links.”
Why would they bother with content that the world doesn’t seem to be interested in at the moment. It would just be a waste of resource and anyway they really only need enough content to fill 6-7 links on the front page of any search. All the rest of the content is surplus to requirements.
Great post, thanks for share it.
wow!
I have no idea before how much google system is complicated!
thanks
This helped me a lot.
Thanks for the great information. I have read three articles on this blog about google indexing strategies. Learned the most out of it.