
As you know, for test case design we have methods such as Decision Table, Equivalence Partitioning, Boundary Value Analysis and Pairwise Testing etc. But ETL testing is a little different. It mostly refers to huge volumes of data and it will apply different tools and usually against one database. To design an ETL test case, you should know what ETL is and understand the data transformation requirement.
ETL is short for Extract, Transform and Load. The objective of ETL testing is to assure that the data that has been loaded from a source to a destination after business transformation is accurate. It also involves the verification of data at various middle stages that are being used between source and destination.
When you start an ETL test case creation, there are some important documents that should be on hand, such as a data model, ETL mappings, ETL jobs guide, database schema of source and target, and an ETL architecture document. To understand how many layers, the data dictionary will be somewhat helpful. Usually, you will need to perform the following pre-steps prior to your ETL test cases creation:
- Analyze the requirement, understanding the data model.
- List out the source and target, analysis the data workflow.
- Deeply go through the ETL mapping to understand the ETL transformation rule.
After you have completed the above steps, you can start creating test cases. Below are some key check points of ETL testing per my experience:
- Static check for the source file to make sure the file format and layout are correct.
- Static check for the ETL mapping to make sure there is no type error, the table name, columns name, key definition and transformation rule are complete.
- Static check for the target table definition in database. Make sure the table name and column name are correct and keys are defined correctly.
- Run ETL jobs and make sure the logs are captured.
- Validate the data count between source and target.
- Validate that the value of each column is completely loaded based on the transform rule. (Using minus SQL here and make sure both source minus target and target minus source are return 0)
- Check the error when the bad data loaded, such as give 1111111 to the column which data type is date.
- Highlight the special transformation rule such as type2, type1 and reject rule etc.
- Check the other transformation rule such as dummy record rule.
My latest project has three layers: SIF layer which is for source file, AW (Atomic Warehouse) layer which is for cleaning source data and DW (Data Warehouse) layer which is the target data warehouse layer. To design the test cases, we split it into two ETL parts, SIF layer to AW layer and AW layer to DW layer, below are the sample steps to create test case from SIF layer to AW layer:

Step 1: Analysis the requirement and data model of AW layer table.
We pick up the patient anchor table here, from the data model we know, it’s an anchor table and all the columns are required columns, the PK is patient sk and it will be generated by the system for each new patient bk. For the source part of patient anchor table is under SIF schema and it STG.PATIENT_MASTER based on the requirement.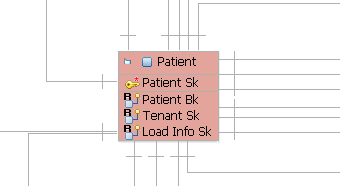
Step 2: List out the source and destination.
For patient anchor, the source is SIF schema and its STG.PATIENT_MASTER. Target is AW. PTNT.
Step 3: Go through the ETL mapping for patient anchor table and start creating test cases based on the above test point and transformation rules mentioned in ETL mapping.
Below is the mapping for patient anchor table,

Step 4: Based on the rules mentioned in mapping, listed all test points for patient anchor table as below:
| 1 | SIF source file validation. | File format should be .csv. |
| 1.Field name should be as same as the v9.1 logical model. 2. Fields should be get from the combined master, array or relationship entities. 3.SIF should be created in IDA. | ||
| 2 | Validate the AWM FastTrack Mapping for the entity. | Field name for Source stage should be as same as SIF. |
| Field name for Atomic table should be as same as the v9.1 logical model. | ||
| The data transform rule should be added for each column. | ||
| 3 | Validate the field definition for Atomic table. | Field name should be as same as the v9.1 model. |
| 4 | Validate the job status run successfully with no error or warning in log and status is finished. | Job run successfully with no error in log and status is finished. |
| 5 | Validate the Source stage to Atomic job status when there is no source data in source table. | Job run successfully and no new record loaded to atomic table. |
| 6 | Validate the field value for Atomic table. | The value of field should be as same as the value in the relevant field of source stage table or mapped based on the logic rule. |
| 7 | Validate the record count after job run successfully. | 1. The record count should be correct based on the data loading rule if there is no record load to reject table. 2. The record count in source stage table should be sum the record count in atomic table and record count in reject table base on the data loading rule if there are records loaded to reject table. |
| 8 | Load same source data from source table twice. | Job run successfully and no new record loaded to atomic table in second time run. |
| 9 | Run Source stage to Atomic job when there are duplicate records in source table. | Job run successfully and only one record loaded to atomic table, duplicates should be skipped. |
| 10 | Maxlength check for each string columns of Atomic table. | 1.The maxlength of the column should be <= the length defined in table field. 2. When maxlength of prepared is > the length defined, there is a warning in the job logs. |
| 11 | Unique check for Atomic table. | No duplicate records in Atomic table. |
| 12 | Validate the value for the fields of Atomic table when have space in the begin or end of the string value (Like ” ABC” or “ABC “). | The space should be trimmed. |
| 13 | Validate the value for the fields of Atomic table when have space in the middle of the string value (Like “A BC”). | The space should not be trimmed. |
| 14 | Validate all the SK should not equal to empty/null/0. | No SK columns in atomic table have value like empty/null/0. |
| 15 | Validate the load_info_sk with the negative batch id will be updated by the latest load_info_sk that positive batch id for current loading when the same BK loaded to anchor table. | The load info sk getting updated with the current batch’s load info sk. |