As a part of Perficient big data practice, I have been working on identifying some open source data stores and search frameworks that enable the user to quickly query what he needs, and to process massive events/message stream, in addition to several frameworks such as Spark, ELK, Hadoop, HBase, Cassandra, I get to know about an open-source data store called druid. This tool was employed by some companies to do real-time streaming analytics to take advantage of its performance.
What is the specific feature of druid? Looking into its official site at http://druid.io/druid.html. Druid is focused on events data analysis and OLAP query, and it also has the ability to process & analyze real-time data. The key functionalities include OLAP (roll-up, drill-down, aggregation, slice, dice etc) operation, real-time data ingestion, multi-tenancy enablement, cost effective and scalability. Comparing to other clustered data store like Redshift, Cassandra, MongoDB, most of these features are similar.
But I am more interested in its combination of both type of analytics – huge history plus real-time events analytics, though Druid was originally designed to solve problems around ingesting and exploring large quantities of transactional events (log data).
The orange part depicts Druid nodes that are actually independently functioning and a minimal interaction between each node. It consists of real-time nodes, historical nodes, broker nodes and coordinator nodes. The streaming data will primarily be stored in the real-time nodes while batch data (it could be loaded via some tool like ETL, Sqoop) into real-time notes, Real-time nodes maintain an in-memory index buffer for all events. These indexes are incrementally populated as events are ingested.

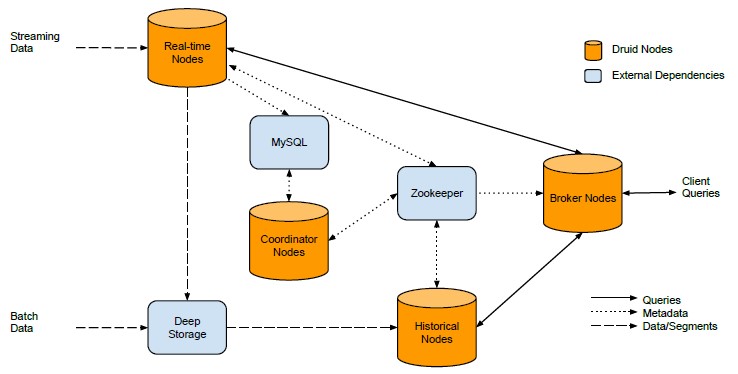
Now someone may ask – what will happen if the machine was rebooted or the JVM was restarted? Will all staged index be lost? In fact, Druid will persist its index to the disk in the periodical manner or when it reaches the max number in JVM heap. Meanwhile, the nodes will convert consumer data into a column-oriented data format. You may know column-oriented format are introduced into many No-SQL products, one major reason is that in a multiple-nodes cluster, column-based data storage is easier to be collected and aggregated across many nodes.
In contrary to real-time nodes, historical nodes are usually set up to process immutable (will not be changed for a long time) data sets. In the real word, this type of data is more than real-time ones. Because of its immutable trait, the historical nodes seldom do the incremental load, instead, it will often do drop or the reload. The broker and coordinator nodes are not primary worker nodes but it will support and manage those worker nodes.
If you read more on its site, you can know druid major ideas come from Google’s BigQuery/Dremel, Google’s PowerDrill, and some search infrastructure. In terms of the production deployment, this open source was deployed in some companies such as Metamarkets, Netflix, Yahoo!. You might be interested in installing and exercise more core features if you hear about its scalability like the following.
- 3+ trillion events/month
- 3M+ events/sec through Druid’s real-time ingestion
- 100+ PB of raw data
- 50+ trillion events
As the last but not least note, the druid source code is at https://github.com/druid-io/druid