
90% of Fortune 500 companies use Salesforce as their Customer Relations Management tool. I have ingested data from Salesforce into almost every database using almost every ETL tool. Every integration tool out there has a Salesforce connector; Salesforce even owns Mulesoft. The integration always worked, but it was rarely smooth. Its just something that you accepted. I knew Databricks is working on a couple of different mechanisms for integrating with Salesforce, but I hadn’t had a reason to do a deep dive. Until yesterday.
Fly Your Own Kite
We like to evaluate preview technologies in-house before any client implementations whenever possible. As a Databricks Champion, I’m encouraged by Databricks to try products before they are released to the public and give feedback. We had an internal use case come up where we wanted to be able to communicate our internal pursuit data out to our partners. Naturally, every partner wanted this data to be provide to them a little differently, so there was a lot of manual effort to massage our internal SFDC data and publish it to each client. Its a very typical use case where automation could speed the process, free up resources for more valuable tasks, improve accuracy, etc. We spoke to our Databricks solution architects and they told us there there was a solution in preview and they gave us access. Eighteen minutes later and we realized we had a new strategic approach to getting value from the lakehouse.
Under the Hood
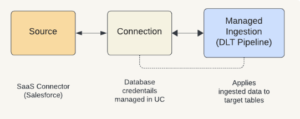
There are a number of solutions for ingesting data into Databricks; this new mechanism is called LakeFlow. LakeFlow Connect uses pre-built connectors for ingesting enterprise SaaS systems, like Salesforce or Workday, into a Delta Live Table. using a Connection. Connections represent a remote data system using system specific options that manage location and authentication details and are one of the many new features of Unity Catalog. These foreign connections also enable Federated Queries, which will will discuss later. Delta Live Tables (DLT) is a declarative ETL framework for streaming and batch that automatically manages task orchestration, cluster management, monitoring, data quality and error handling. Unity Catalog handles lineage, governance and security. DLT handles change data capture, monitoring, and management. All of this is powered by a serverless compute architecture, abstracting away the configuration and deployment of infrastructure. So what does this mean?
Let’s address the most obvious objection: this solution requires data to be moved. There are interesting options with Databricks and Snowflake for Salesforce Data Cloud for federation and zero-copy integration respectively. But the Sales Cloud is still by far the market leader, so I’m primarily concerned with the Salesforce CRM product. There are naturally concerns around cost with duplicating data, but the goal would be to have enhanced, rather than merely duplicated, data. And, of course, value is a better metric than cost. Our internal use case can show cost savings and intangible benefits like partner relationships that far outstrip storage costs. Realistically, I actually see us replacing existing, more costly, ingestion processes across our customer base.
A Better Mousetrap
A more accurate comparison would be LakeFlow versus tools like FiveTran. DLT is a native feature of Databricks designed specifically for declarative data transformation and data pipeline creation. DLT supports both batch and streaming data, allows for incremental data processing and handles schema evolution, data quality checks, and automated recovery from errors. Both DLT and Connections are fully integrated with Unity Catalog enabling fine-grained access controls, data lineage, and audit logs to enforce security policies consistently across the data lakehouse environment. The DLT framework will automatically manage orchestration, monitoring and data quality while the serverless architecture manages clusters in a performant and cost-effective manner. This tightly coupled integration with the Databricks ecosystem, particularly Unity Catalog, makes LakeFlow difficult to beat for this category.
Other Options
Databricks Lakehouse Federation allows you to query, without moving, external data sources from within Databricks. There is a strong case to be made for using Federation for ad-hoc querying. In this particular use case, we need to apply some pretty complex transformations on our pipelines in order to conform our Salesforce data to our different partners on a fixed schedule. This made LakeFlow a better choice than Federation despite the need to duplicate data for this use case. There is no reason why Federation and LakeFlow can’t both be used in the same enterprise to query data from your Databricks lakehouse. I would actually recommend you use both. And I would also recommend looking into a third option.
Databricks is not a data platform; is a data and intelligence platform. This is where Bring Your Own Model (BYOM) comes into the picture. Salesforce takes a zero-copy approach to provide external machine learning platforms like Databricks direct access to Salesforce data. You can build, train, and deploy custom machine learning models with Databricks and data in Salesforce. After registering a model in Databricks, define your prediction criteria and connect the model with Data Cloud. Again, this is another complementary mechanism for combining Salesforce data with Databricks insights.
Conclusion
It’s hard to overstate the business value Salesforce data would bring to your enterprise data lake. You have several complementary options. Use LakeFlow Connect to bring your Sales Cloud data into your lakehouse to be stored, transformed, analyzed and shared. Use Federation to query data in Data Cloud directly from Databricks. And take advantage of Databricks’ powerful machine learning capabilities against your Data Cloud using the BYOM approach.
Contact us and let’s work together on your data and AI journey!