
In the context of Apache Spark, RDD, DataFrame, and Dataset are different abstractions for working with structured and semi-structured data. Here’s a brief definition of each:
RDD (Resilient Distributed Dataset):
- RDD is the basic abstraction in Spark.
- It represents an immutable, distributed collection of objects that can be processed in parallel across a cluster.
- RDDs can contain any type of Python, Java, or Scala objects.
- RDDs support transformations (e.g., map, filter) and actions (e.g., count, collect) to perform distributed computations.
DataFrame:
- DataFrame is a higher-level abstraction introduced in Spark that organizes data into named columns.
- It is conceptually similar to a table in a relational database or a data frame in R/Python’s pandas library.
- DataFrames can be created from various data sources like structured data files (e.g., CSV, JSON), Hive tables, or existing RDDs.
- They provide a more SQL-like, declarative way to manipulate data compared to RDDs.
- DataFrame operations are optimized using Spark’s Catalyst optimizer.
Dataset:
- Dataset is a new abstraction introduced in Spark that combines the features of RDDs and DataFrames.
- It provides the type-safety of RDDs (through Scala/Java) and the high-level API of DataFrames.
- Datasets are strongly typed, meaning the elements of a Dataset must be instances of a specific class.
- They provide better performance than RDDs due to their optimizations, especially when working with structured data.
- Datasets can be created from DataFrames or RDDs, and they support both functional programming and SQL-like queries.
Let’s compare RDDs, DataFrames, and Datasets in Apache Spark across various dimensions:

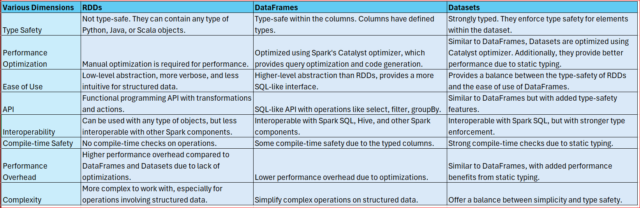
In summary, RDDs are the lowest-level abstraction offering flexibility but with less optimization and type safety. DataFrames provide a more SQL-like interface with optimizations, while Datasets offer the advantages of both RDDs and DataFrames with stronger type safety and performance benefits. The choice between them depends on the requirements of the application, balancing factors such as performance, ease of use, and type safety.
References:
To know more about RDD operations: Spark RDD Operations (perficient.com)