
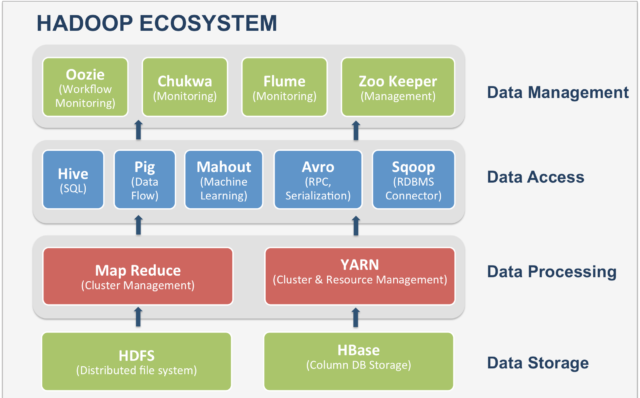
The Hadoop Ecosystem
Hadoop Ecosystem is a platform or a suite that provides various services to solve big data problems. It includes Apache projects and various commercial tools and solutions. 4 major elements of Hadoop are HDFS, MapReduce, YARN, and Hadoop Common. Hadoop is a framework that enables the processing of large data sets which reside in the form of clusters. Being a framework, Hadoop was made up of several modules that are supported by a large ecosystem of technologies.
Components that collectively form a Hadoop ecosystem:
- HDFS: Hadoop Distributed File System
- YARN: Yet Another Resource Negotiator
- MapReduce: Programming-based Data Processing
- Spark: In-Memory data processing
- PIG, HIVE: Query-based processing of data services
- HBase: NoSQL Database
- Mahout, Spark MLLib: Machine Learning algorithm libraries
- Zookeeper: Managing cluster
- Oozie: Job Scheduling
What is Hadoop?
Apache Hadoop is a framework that allows the distributed processing of large data sets across clusters of commodity computers using a simple programming model.
It is an Open-source Data Management with scale-out storage & distributed processing.
The Apache Hadoop project develops open-source software for reliable, scalable, distributed computing.
HDFS: Hadoop Distributed File System
- HDFS is a distributed, scalable, and portable filesystem written in Java for the Hadoop framework.
- HDFS creates multiple replicas of data blocks and distributes them on compute nodes throughout a cluster to enable reliable, extremely rapid computations.
- HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware.
- HDFS provides high throughput access to application data and is suitable for applications that have large data sets
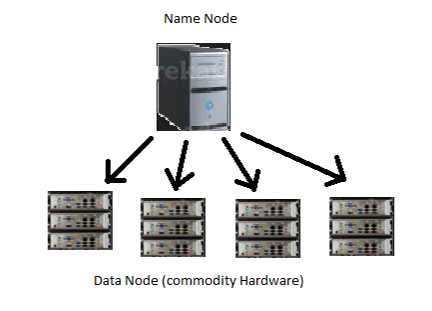
- HDFS consists of two core components :
- Name Node
- Data Node
Name Node:
- Name Node, a master server, manages the file system namespace and regulates access to files by clients.
- Maintains and manages the blocks which are present on the data node.
- Name Node is the prime node that contains metadata
- Meta-data in Memory
– The entire metadata is in the main memory - Types of Metadata
– List of files
– List of Blocks for each file
– List of Data Nodes for each block
– File attributes, example: creation time, replication - A Transaction Log
– Records file creations, and file deletions. Etc.
Data Node:
- Data Nodes, one per node in the cluster, manage storage attached to the nodes that they run on.
- data nodes that store the actual data. These data nodes are commodity hardware in the distributed environment.
- A Block Server
- Stores data in the local file system
- Stores meta-data of a block
- Serves data and meta-data to Clients
- Block Report
- Periodically sends a report of all existing blocks to the Name Node
- Facilitates Pipelining of Data
- Forwards data to other specified Data Nodes
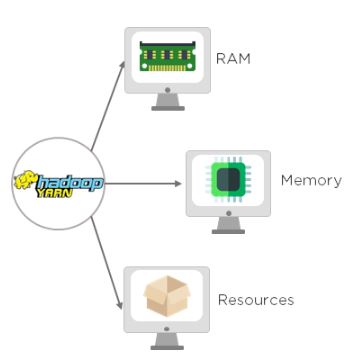
YARN: Yet Another Resource Negotiator
- Apache YARN is Hadoop’s cluster resource management system.
- YARN was introduced in Hadoop 2.0 for improving the MapReduce utilization.
- It handles the cluster of nodes and acts as Hadoop’s resource management unit. YARN allocates RAM, memory, and other resources to different applications.
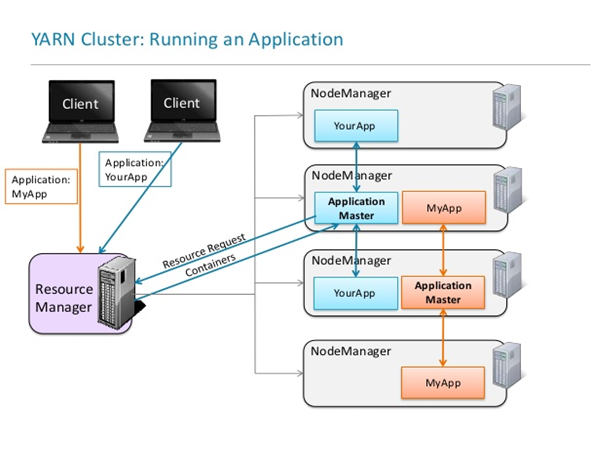
YARN has two components :
Resource Manager
- Global resource scheduler
- Runs on the master node
- Manages other Nodes
- Tracks heartbeats from Node Manager
- Manages Containers
- Handles AM requests for resources
- De-allocates containers when they expire, or the application completes
- Manages Application Master
- Creates a container from AM and tracks heartbeats
- Manages Security
Node Manager
- Runs on slave node
- Communicates with RM
- Registers and provides info on Node resources
- Sends heartbeats and container status
- Manages processes and container status
- Launches AM on request from RM
- Launches application process on request from AM
- Monitors resource usage by containers.
- Provides logging services to applications
- Aggregates logs for an application and saves them to HDFS
MapReduce: Programming-based Data Processing
- HDFS handles the Distributed File system layer
- MapReduce is a programming model for data processing.
- MapReduce
– Framework for parallel computing
– Programmers get simple API

– Don’t have to worry about handling
- parallelization
- data distribution
- load balancing
- fault tolerance
- Allows one to process huge amounts of data (terabytes and petabytes) on thousands of processors
Map Reduce Concepts (Hadoop-1.0)
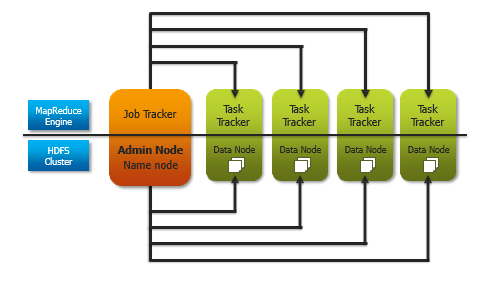
Job Tracker
The Job Tracker is responsible for accepting jobs from clients, dividing those jobs into tasks, and assigning those tasks to be executed by worker nodes.
Task Tracker
Task-Tracker is a process that manages the execution of the tasks currently assigned to that node. Each Task Tracker has a fixed number of slots for executing tasks (two maps and two reduces by default).
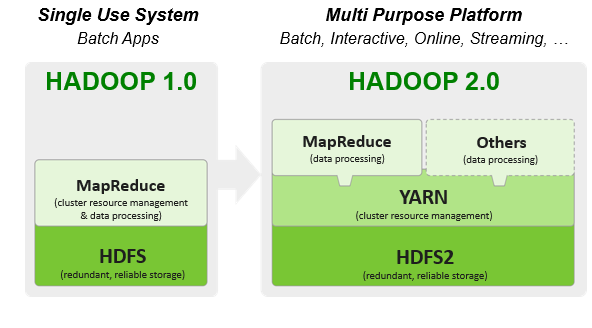
Hadoop 2.0 Cluster Components
-
- Split up the two major functions of Job Tracker
- Cluster resource management
- Application lifecycle management
- Resource Manager
- Global resource scheduler
- Hierarchical queues
- Node Manager
- Per-machine agent
- Manages the life cycle of the container
- Container resource monitoring
- Application Master
- Per-application
- Manages application scheduling and task execution
- g. MapReduce Application Master
- Split up the two major functions of Job Tracker
Hadoop as a Next-Gen Platform
Spark: In-Memory data processing
- Spark is an open-source distributed processing system.
- It is a cluster computing platform designed to be fast.
- In memory computation (RAM) that increases the processing speed of an application.
Combines different processing types like
- Batch processing
- Streaming Data
- Machine learning
- Structure Data
- Graph X Data
Batch Processing
It is the processing of big data at rest. You can filter, aggregate, and prepare very large datasets using long-running jobs in parallel.
It is the processing of data in a particular frequency of time.
Streaming data
Streaming or real-time, data is data in motion. Real-time data can be processed to provide useful information. using application data was generated immediately by streaming data.
Machine learning
Spark’s library for machine learning is called MLlib (Machine Learning library). It’s heavily based on learn’ s ideas on pipelines. In this library to create an ML model the basics concepts are:
Data Frame: This ML API uses Data Frame from Spark SQL as an ML dataset, which can hold a variety of data types.
Structured data
It is something that has a schema that has a known set of fields. When the schema and the data have no separation, then the data is said to be semi-structured.
RDD is an immutable data structure that distributes the data in partitions across the nodes in the cluster.

PIG, HIVE: Query-based processing of data services
PIG
To performed a lot of data administration operation, Pig Hadoop was developed by Yahoo which is Query based language works on a pig Latin language used with hadoop.
- It is a platform for structuring the data flow, and processing and analyzing huge data sets.
- Pig does the work of executing commands and in the background, all the activities of MapReduce are taken care of. After the processing, PIG stores the result in HDFS.
- Pig Latin language is specially designed for this framework which runs on Pig Runtime. Just the way Java runs on the JVM.
Features of PIG
- Provides support for data types – long, float, char array, schemas, and functions
- Is extensible and supports User Defined Functions
- Provides common operations like JOIN, GROUP, FILTER, SORT
HIVE
Relational databases that use SQL as the query language implemented by most of data Most data warehouse application. Hive is a data warehousing package built on top of Hadoop that lowers the barrier to moving these applications to Hadoop.
- Structured and Semi-Structured data Processing by using Hive.
- Series of automatically generated Map Reduce jobs is internal execution of Hive query.
- Structure data used for data analysis.
HBase: NoSQL Database
- Apache HBase is an open-source, distributed, versioned, fault-tolerant, scalable, column-oriented store modeled after Google’s Bigtable, with random real-time read/write access to data.
- It’s a NoSQL database that runs on top of Hadoop as a distributed and scalable big data store.
- It combines the scalability of Hadoop by running on the Hadoop Distributed File System (HDFS), with real-time data access as a key/value store and deep analytic capabilities of Map Reduce.
Mahout, Spark MLLib: Machine Learning algorithm libraries
- Mahout provides an environment for creating machine learning applications that are scalable.
- Mahout allows Machine Learnability to a system or application.
- MLlib, Spark’s open-source distributed machine learning library.
- MLlib provides efficient functionality for a wide range of learning settings and includes several underlying statistical, optimization, and linear algebra primitives.
- It allows invoking algorithms as per our need with the help of its own libraries.
Zookeeper: Managing cluster
- Apache Zookeeper is the coordinator of any Hadoop job which includes a combination of various services in a Hadoop Ecosystem.
- Apache Zookeeper coordinates with various services in a distributed environment.
- It is an open-source, distributed, and centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services across the cluster.
- Zookeeper, There was a huge issue of management of coordination and synchronization among the resources or the components of the Hadoop Ecosystem.
Oozie: Job Scheduling
- Apache Oozie is a clock and alarm service inside Hadoop Ecosystem.
- Oozie simply performs the task scheduler, it combines multiple jobs sequentially into one logical unit of work.
- Oozie is a workflow scheduler system that allows users to link jobs written on various platforms like MapReduce, Hive, Pig, etc. schedule a job in advance and create a pipeline of individual jobs was executed sequentially or in parallel to achieve a bigger task using Oozie.
There are two kinds of Oozie jobs:
Oozie Workflow
Oozie workflow is a sequential set of actions to be executed.
Oozie Coordinator
These are the Oozie jobs that are triggered by time and data availability
Very informative Ankita…keep it up !
Very informative Ankita…..Keep it up !