
Apache Spark:
Apache Spark is a general-purpose distributed processing engine for analytics over large data sets – typically terabytes or petabytes of data. Apache Spark can be used for processing data in batches, real-time streams, machine learning and ad-hoc query.
Processing tasks are distributed over a cluster of nodes and data is cached in-memory to reduce the computation time.
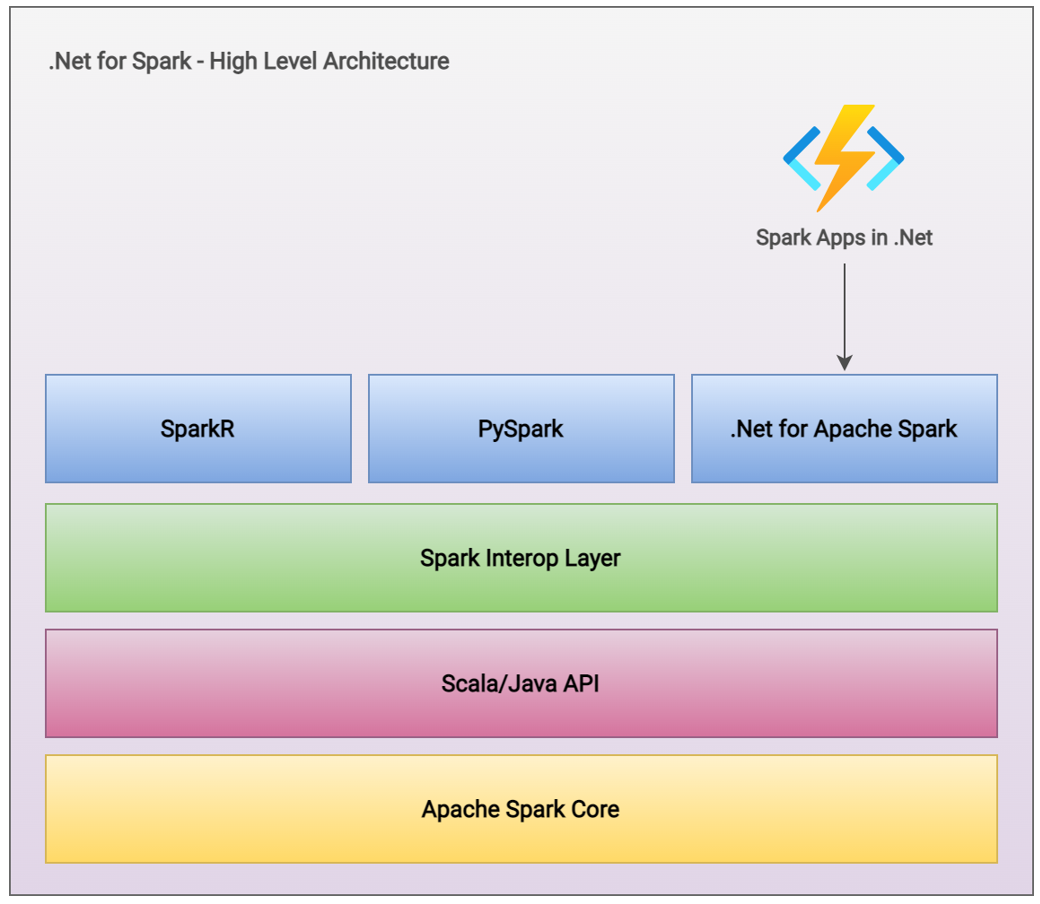
.Net for Apache Spark:
With .Net for Apache Spark, the free, open-source and cross platform .Net support for the popular open-source big data analytics framework, we can add the capabilities of Apache Spark to big data applications using languages that we already know. .Net for Apache Spark empowers developers with .Net experience, can contribute & benefit out of big data analytics. .Net for Apache Spark provides high performance APIs for using Spark from C# and F#. With C# and F#, we can access:
- Dataframe and SparkSQL for working with structured data
- Spark Structured Streaming for working with streaming content
- Spark SQL for writing queries with familiar SQL syntax
- Machine Learning integration for faster training and prediction
.Net for Apache Spark runs on Windows, Linux and macOS using .Net Core, which is already a cross-platform framework. We can deploy our applications to all major cloud providers including Azure HDInsights, Amazon EMR Spark, Azure Databricks and Databricks on AWS. For the convenience of our discussion, we shall discuss our samples in C# language for the benefit of major audiences.
Setting up the development environment as per the instructions given in below link,
Get started with .NET for Apache Spark | Microsoft Docs
Once Spark, .Net for Apache Spark are successfully installed in Windows OS, execute below command to ensure spark is running successfully,
Command prompt (administrator)> spark-shell
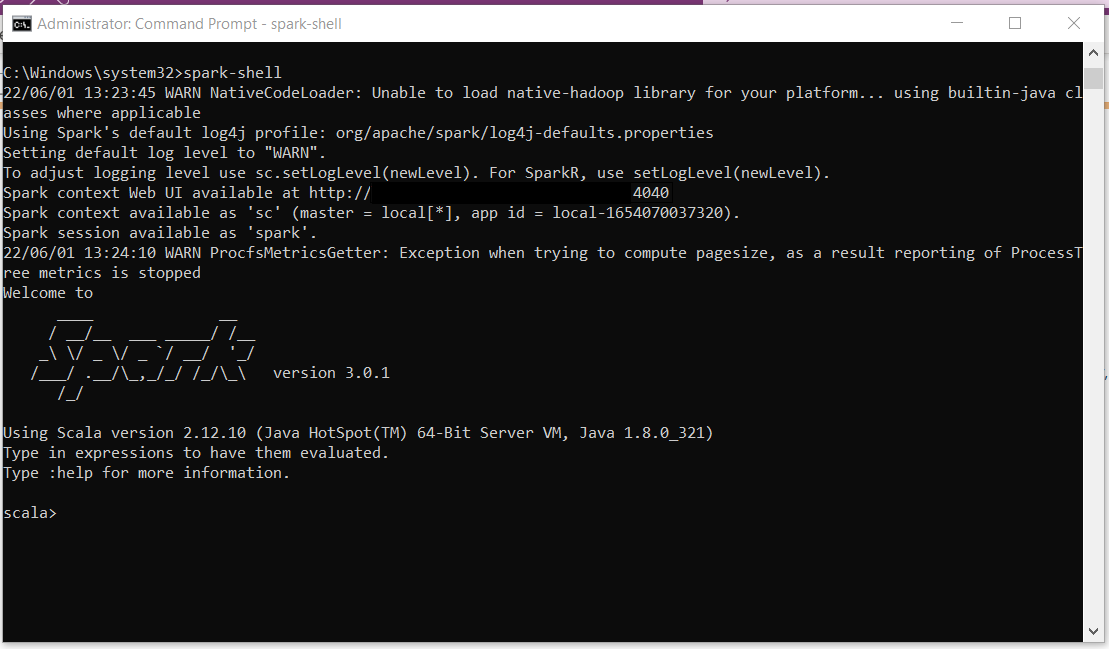
An active spark session will be initiated successfully and ready to use as above.

Create a console application targeting .Net Core 3.1 framework.
Add “Microsoft.Spark” Nuget package to the project
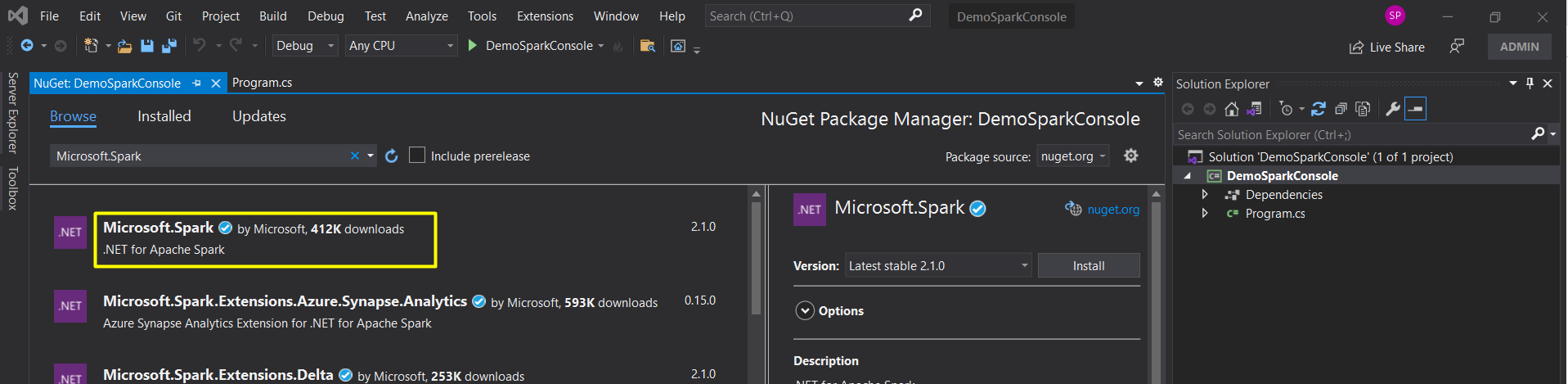
Once the package is added, the jar libraries are listed as below in Visual Studio project.
In Program.cs class file, write the below code and save,
using System;
using Microsoft.Spark.Sql;
using static Microsoft.Spark.Sql.Functions;
namespace DemoSparkConsole
{
class Program
{
static void Main(string[] args)
{
SparkSession spark = SparkSession.Builder().AppName("package_tracker").GetOrCreate();
string fileName = args[0];
// Load CSV data
spark.Read().Option("header", "true").Csv(fileName).CreateOrReplaceTempView("Packages");
DataFrame sqlDf = spark.Sql("SELECT PackageId, SenderName, OriginCity, DestinationCity, Status, DeliveryDate FROM Packages");
sqlDf.Show();
spark.Stop(); // Stop spark session
}
}
}
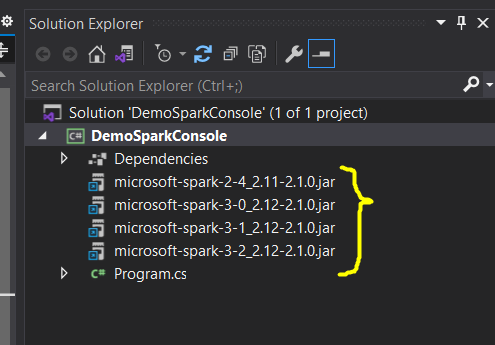
Build the project and navigate to Debug path. Locate the project DLL file and microsoft-spark-3-1_2.12-2.1.0.jar that will be responsible for running spark program,
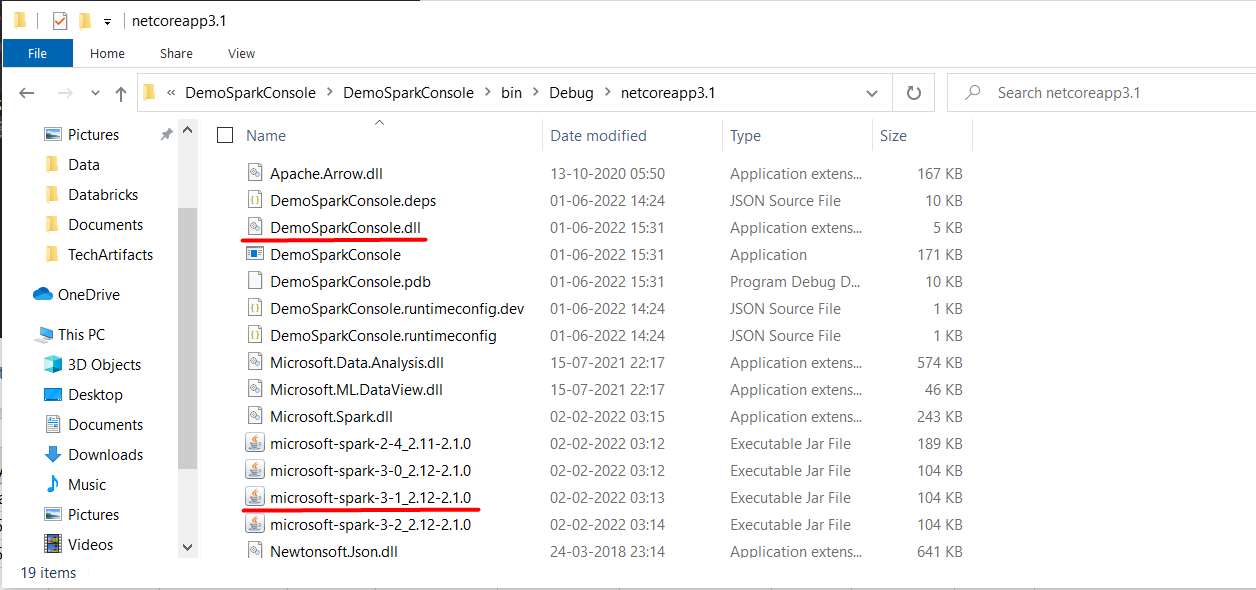
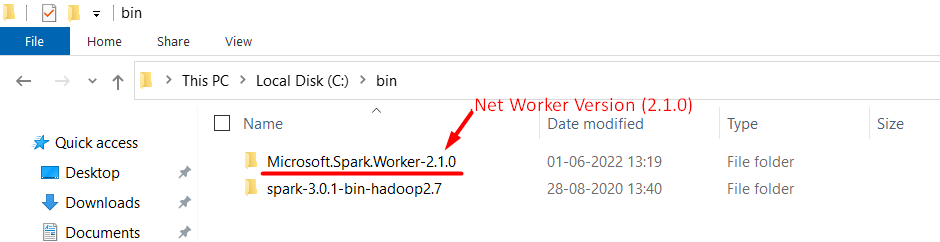
Make sure that microsoft-spark DLL version matches with the version of Microsoft Spark Worker extracted in local directory as below,
Spark command to submit the job:
Syntax:
spark-submit --class org.apache.spark.deploy.dotnet.DotnetRunner --master local microsoft-spark-3-0_2.12-<Version_of_.Net_Worker>.jar dotnet <ApplicationName>.dll <input_file_name>
Navigate to console app output build folder path in Powershell (Admin mode) and execute below command:
spark-submit --class org.apache.spark.deploy.dotnet.DotnetRunner --master local microsoft-spark-3-0_2.12-2.1.0.jar dotnet DemoSparkConsole.dll packages.csv
Input file to read: packages.csv
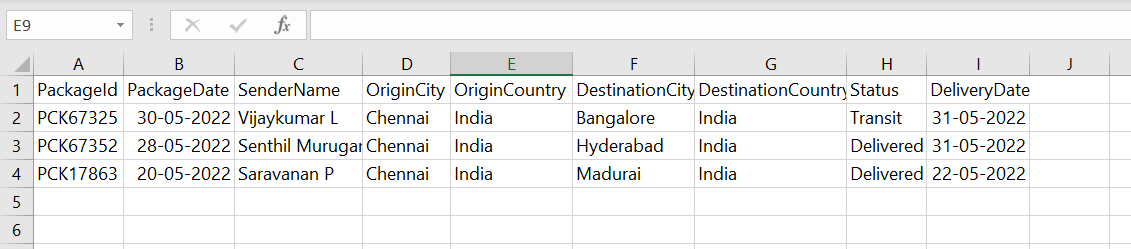
Output Dataframe:
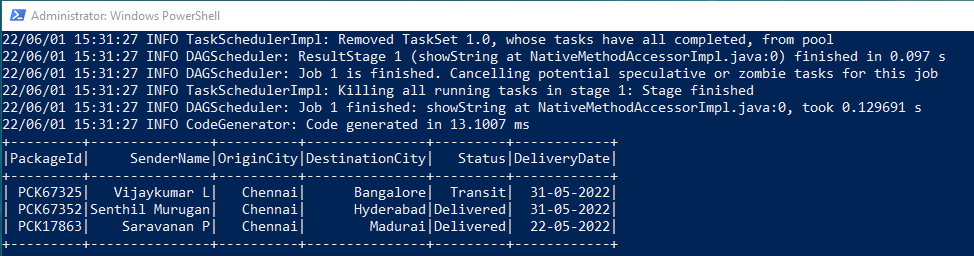
Very much helpful and understandable