Microsoft announced Project Cortex at Microsoft Ignite in Orlando earlier this month. While there were literally hundreds of announcements, the biggest announcement was Project Cortex.
What is it?
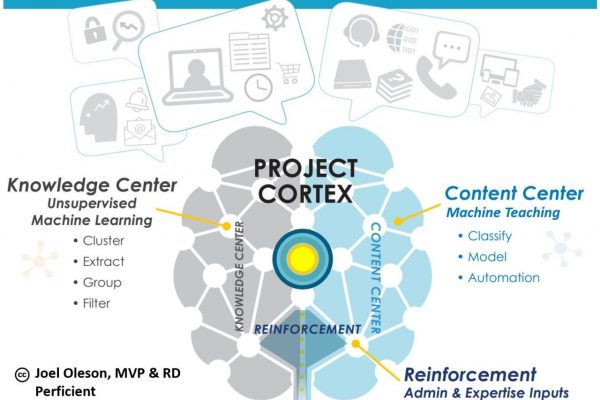
Project Cortex will create and update new topic pages and knowledge centers that are meant to act like wikis. Topic cards will be available to users in Outlook, Teams and Office. Cortex builds on top of Microsoft Cognitive services for image and text recognition, forms processing and machine teaching with LUIS, language understanding.
At the heart of Project Cortex is a much improved and largely AI driven managed metadata service which enables tagging and more across much of Microsoft 365. Cortex will leverage the Microsoft Search service in connecting to third-party repositories through connectors which already are available for Windows File Share, ServiceNow, SQL Database, Intranet Websites, MediaWiki, Azure Data Lake Gen2, Salesforce and is extensible.
Those paying attention to Microsoft technologies about 15 years ago may remember a pilot of a tool called Knowledge Network. This tool would analyze your email for keywords and people with a plan to help you organize your content around a network. It was clever. It gave you insights about who you were working with and could make recommendations. Ultimately the project was abandoned, likely due to process intense desktop app with an already process heavy outlook app. While it was improving search and retrieval in Outlook and may have provided insights, Microsoft no longer supported the app in favor of other backend improvements and effort. They pursued enterprise metadata stores which had promise, but many would say have yet to deliver on the promise of rich enterprise metadata taxonomies for a dozen reasons. For the last dozen years, the pressure has been on building content types, and asking users to populate metadata columns, keywords, and tags. This has largely gone unused in most organizations.

The main difference between managed metadata and this new knowledge network provided by Project Cortex is the promise of a AI driven backed by crowd sourced folksonomy, largely driven not by a small group of people, but through the content creators. Artificial Intelligence does the heavy lifting and is then validated by those creating the content or tasked to manage the approvals. This UI and experience hasn’t been shared yet beyond demos and in the expo hall at Microsoft Ignite. Currently, it is only available to those in the very limited private preview. The program is expanding with more coming in 2020.
The promise now is the ability to have a large corpus of knowledge that is captured and built upon in a true enterprise wiki. Not much unlike Wikipedia, but largely driven based on the content created by the organization and categorized, extracted, cataloged and automatically connected to the enterprise corpus through highlighted topics. Imagine all of the automatic and intelligence that is driven not by the arduous effort of end users through manual keywords, columns, and metadata tagging, but through automatic extraction, machine teaching, machine learning, and the best of Microsoft Research built on the back of Office 365 which is populated not just by SharePoint alone but Outlook, Teams, Planner, Stream, Project, Tasks and so on.
It doesn’t end there. The promise is just as your data in external SaaS storage such as Box and Dropbox can also be cataloged, extracted, enriched and linked by this same enterprise wiki of topic cards retrieved by enterprise search, and exposed in the documents themselves, in interactions in Word, Excel, Outlook, SharePoint, Teams and so on.
Why should you care?
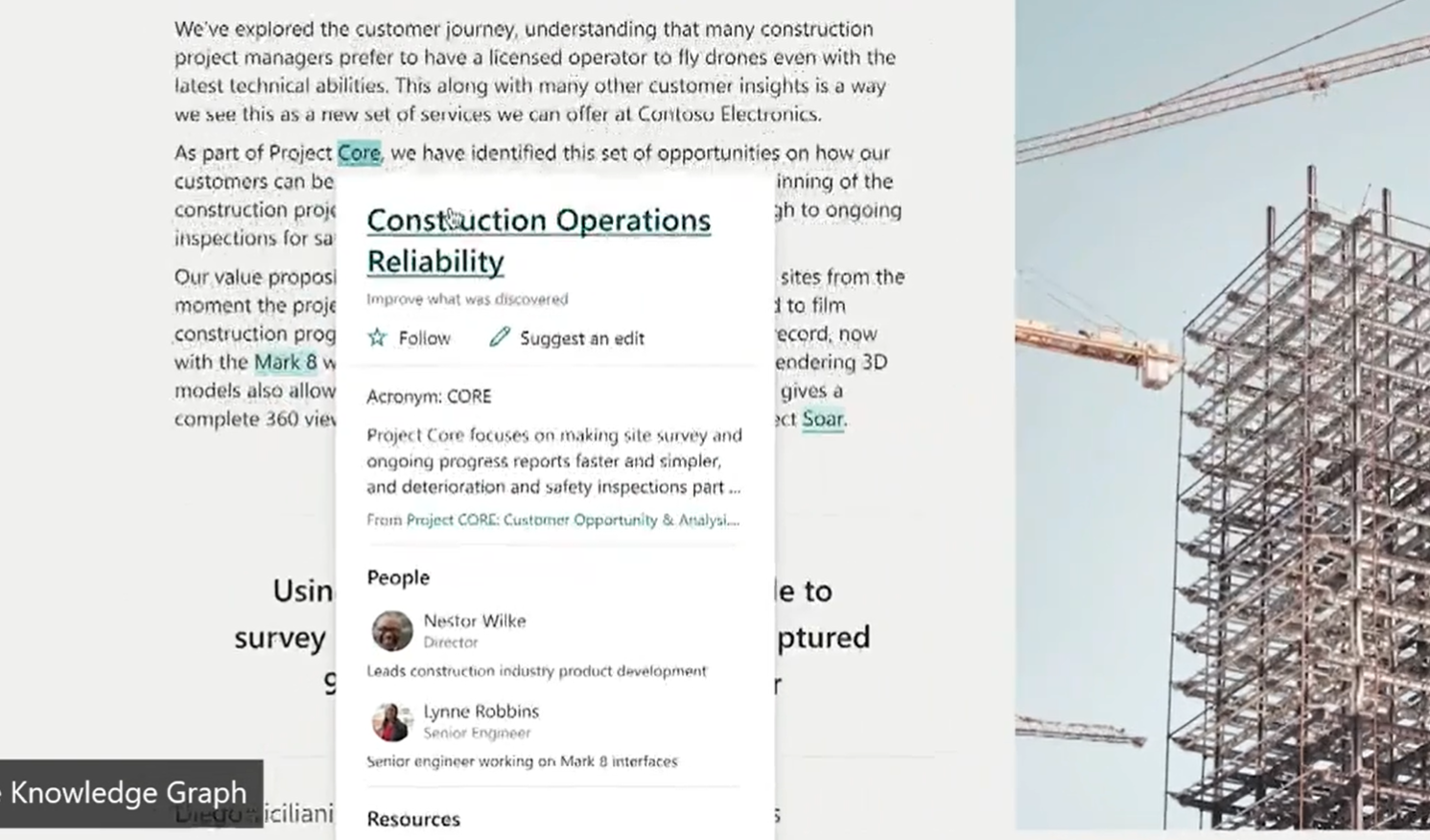
Imagine you’re scanning your invoices and storing them in SharePoint. Prior to Project Cortex, this largely would have provided you with some PDFs stored in a SharePoint library. Thanks to the efforts of the cloud, you would already have a much better experience than in the past due to indexing of the PDFs even if they’re only images, but also extraction of keywords. Project Cortex with machine teaching could extract customer names, addresses, invoice numbers, amounts, validation of the scans and this content not only would populate in relevant columns, but also know what a customer is, and highlight in the document where when you click on it could take you to an information card which then when clicked take you to a rich page with relationships spidering out to show locations, offices, people, industries, topics and so on based on both validated and extracted relationships in the data. The possibilities are exciting as today you often don’t know what you have. You definitely don’t know what questions to ask of your data. Imagine and AI that wants to make sense of both your structured and unstructured data to build relationships around it. There is industry knowledge and taxonomies that could have vastly important impact on this.
Why do these knowledge networks, taxonomies, and structured managed metadata and tagging projects fail?
Time, effort, consensus, enterprise skills, budgets, staying power and abilities to sustain such a vast project…Dozens of reasons that come down to the need for someone that has the backing and skillset to sustain such a vastly important and critical project. It also relies on the individuals to fill in the metadata and even if you had already paid hundreds of thousands of dollars today to use cloud extraction programs your ability to do it cross platform would be limited.
Why is Project Cortex different?
Project Cortex has such an incredible handle on the key elements to not only automate, but to support it long term as users see the immense value immediately. The difference is in the power of the cloud, power of artificial intelligence and the fact that Microsoft 365 is so well connected now than ever before. This can be successful and it will change the way we look at our content. You’re not just uploading a document that sits in a library. Your adding to an enterprise corpus. Remember that insightful quote from the CIO of HP? “Imagine if HP only knew what HP knows it could be twice as successful.” I truly see Project Cortex in that light. Microsoft with cloud and AI improvements delivered in Project Cortex hopes to deliver on the promise of helping unlock organizational knowledge in just that way. What could John Hopkins know if it knew what it knows? What would that do for medicine? What could Kroger do with access to it’s knowledge?
On the surface this means quicker ramp up for employees who don’t know the projects, products, customers and services. It also allows long time employees to more easily provide knowledge, insights, and incrementally help connect things by validating what the AI is seeing as relationships in the data, content, and business data. Unlocking the enterprise knowledge to a level of helping and providing insights at a level of expansiveness never thought possible. This is big. Yes, it changes everything.
If you’re looking to get started looking at something like this, reach out to me. I’d love to help you get connected with Microsoft there are a few charter organizations that can support customers and we are the one. Let’s talk. I’m excited to get started, and I want to work with you.