
Bigdata is generally a lot of data produced very quickly in many different forms. Data might include customer transactional histories, production databases, web traffic logs, online videos, social media interactions, and so forth. The challenge for Data Management can be coined by three V’s” – “volume, velocity and variety.
Big Data is special because it represents significant information that opens new doors to enrich business processes. How can all this data possibly be combed through to spot trends, suggest the direction of consumer tastes, or what climate changes are occurring? That’s where the interpretive process comes in.
We would need new technologies and skills to analyze the flow of data and draw conclusions. Apache Hadoop is one such framework, which will allow for the distributed processing of huge sets of data across various clusters of computers using simple programming models.
MapReduce coordinates the processing of data in different segments of a cluster, then breaks down the results into more manageable chunks which can be processed to form BI Reports.
How Does MapReduce Work?
The MapReduce algorithm can be segregated into two tasks: Map and Reduce. The Map task takes a set of data and converts it into another processed set of data, where individual elements are broken down into key-value pairs(tuples).
The Reduce task receives the input from the Map task’s output and combines those data (tuples or key-value pairs) into a set of smaller tuples. The reduce task is always performed after the map job.
How Do You Code a Map Reduce Program?
To start coding MapReduce, we should have a problem statement such as the one stated below:
Let’s consider we have a very busy website and need to pull down the site for an hour to apply some patches and perform maintenance of the backend servers. This means that the website will be completely unavailable for an hour. To perform this activity, the primary goal will be for the shutdown outage to affect the least number of users.
So here, we need to identify at what hour of the day the web traffic is least for the website so that the maintenance activity can be scheduled for that time.
Let’s assume that there is an Apache web server log for each day which records the activities happening on the website, but those are huge files at up to 5 GB each.
Sample Log File:
| LOG LEVEL | LOG MESSAGE | LOGGED TIME | |
| INFO | STARTED TEST SUITE: FIP TESTSUITE – Q ENV | 2017_09_12_082415 | |
| INFO | STARTED TEST CASE: SEND | 2017_09_12_082415 | |
| INFO | STARTED TEST STEP: TC1_SENDER_REGULARNAMES | 2017_09_12_082415 | |
| PASS | THE PROPERTIES TEST STEP PASSED | 2017_09_12_082415 | |
| INFO | STARTED TEST STEP: TC1_CREATETIMESTAMP – F1 | 2017_09_12_082415 | |
| PASS | THE GROOVY TEST STEP PASSED | 2017_09_12_082415 | |
| INFO | STARTED TEST STEP: TC1_CREATERANDOMAMT – F1 | 2017_09_12_082415 | |
| PASS | THE GROOVY TEST STEP PASSED | 2017_09_12_082415 | |
| INFO | STARTED TEST STEP: TC1_FEELOOKUP – F1 | 2017_09_12_082415 | |
| PASS | SOAP RESPONSE | 2017_09_12_082417 | |
| PASS | SCHEMA COMPLIANCE | 2017_09_12_082417 | |
| PASS | NOT SOAP FAULT | 2017_09_12_082417 | |
| PASS | VALID HTTP STATUS CODES | 2017_09_12_082417 | |

We are interested only in the date field i.e. [2017_09_12_082417]
Solution: We need to consume one month of log files and run the MapReduce code which calculates the total number of hits for each hour of the day. The perfect hour for the downtime is when there is the least amount of traffic.
A MapReduce program usually consists of the following 3 parts:
- Mapper
- Reducer
- Driver
The code is basically divided into two phases: one is Map and the second is Reduce. Both phases have an input and output as the key-value pairs. The programmer has the liberty to choose the data model for the input and output for both Map and Reduce. Depending upon the business problem, the appropriate data model can be used.
What Does Mapper Do?
- The Map function will read input files as a key/value pair and processes each pair. It will then generate zero or more output key/value pairs.
- The Map class extends the Mapper class, which is a subclass of org.apache.hadoop.mapreduce.java.lang.Object : org.apache.hadoop.mapreduce.Mapper
- The input and output types of the map can be different from each other.
- The Map function is also a good place to filter any unwanted fields/ data from the input file.
Mapper Code:
import java.io.IOException;
import java.text.ParseException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class LogMapper extends
Mapper<LongWritable, Text, IntWritable, IntWritable> {
private static Logger logger = LoggerFactory.getLogger(LogMapper.class);
private IntWritable hour = new IntWritable();
private final static IntWritable one = new IntWritable(1);
private static Pattern logPattern = Pattern.compile(“([^ ]*) ([^ ]*) ([^ ]*) \\[([^]]*)\\]”
+ ” \”([^\”]*)\””
+ ” ([^ ]*) ([^ ]*).*”);
public void map(LongWritable key, Text value, Context context)
throws InterruptedException, IOException {
logger.info(“Mapper started”);
String line = ((Text) value).toString();
Matcher matcher = logPattern.matcher(line);
if (matcher.matches()) {
String timestamp = matcher.group(4);
try {
hour.set(ParseLog.getHour(timestamp));
} catch (ParseException e) {
logger.warn(“Exception”, e);
}
context.write(hour, one);
}
logger.info (“Mapper Completed”);
}
}
The Mapper class has four parameters which specify the input key, input value, output key, and output values of the Map function.The Mapper code written above is for processing a single record. We will not write logic in MapReduce to deal with the entire data set. The framework will be responsible for converting the code to process the entire data set by converting it into the desired key value pair.
| Mapper<LongWritable, Text, IntWritable, IntWritable> | ||
| Mapper<Input key, Input value, Output key, and Output values> | ||
| Mapper<Offset of the input file, Single Line of the file, Hour of the day, Integer One> | ||
Hadoop provides a set of basic types which are optimized for network serialization and can be found in the org.apache.hadoop.io package.
In the above program, LongWritable is used, which corresponds to a Java Long, Text (like Java String), and IntWritable (like Java Integer). Mapper will be writing its output using an instance of the Context class which will be used to communicate in Hadoop.
What Does Reducer Do?
- The Reducer code reads the outputs generated by the different mappers as pairs and emits key value pairs.
- The Reducer will reduce a set of transitional values that share a key to a smaller set of values.
- lang.Object : org.apache.hadoop.mapreduce.Reducer
- Reducer has 3 primary phases: shuffle, sort and reduce.
- Every reduce function processes the intermediate values for a specific key generated by the map
There exists a one-one mapping between keys and reducers. - Multiple reducers can run in parallel because they are independent from one another. The number of reducers for a specific job will be decided by the programmer. By default, the number of reducers will be 1.
- The output of the reduce task is typically written to the FileSystem via
collect(WritableComparable, Writable)
Reducer Code:
import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.mapreduce.Reducer;import org.slf4j.Logger;import org.slf4j.LoggerFactory;public class LogReducer extendsReducer<IntWritable, IntWritable, IntWritable, IntWritable> {private static Logger logger = LoggerFactory.getLogger(LogReducer.class);public void reduce(IntWritable key, Iterable<IntWritable>; values,Context context) throws IOException, InterruptedException {logger.info(“Reducer started”);int sum = 0;for (IntWritable value : values) {sum = sum + value.get();}context.write(key, new IntWritable(sum));logger.info(“Reducer completed”);}} |
There are four parameters in Reducers which are used to specify the input and output, that define the types of the input and output key/value pairs. The output of the map task will be input to the reduce task generally. The first two parameters are the input key value pair from the Map task. In our example IntWritable, IntWritable
| Reducer<IntWritable, IntWritable, IntWritable, IntWritable> | |
| Reducer<Input key, Input value, Output key, and Output values> | |
| Reducer<Hour of the day, List of counts, Hour, Total Count for the Hour>; |
What Does Driver Do?
The driver class is the one which is responsible for executing the MapReduce framework. The job object will allow you to configure the Mapper, Reducer, InputFormat, OutputFormat etc.
Driver Code:
import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.slf4j.Logger;import org.slf4j.LoggerFactory;public class LogDriver {private static Logger logger = LoggerFactory.getLogger(LogDriver.class);public static void main(String[] args) throws Exception {logger.info(“Code started”);Job job = new Job();job.setJarByClass(LogDriver.class);job.setJobName(“Log Analyzer”);job.setMapperClass(LogMapper.class);job.setReducerClass(LogReducer.class);job.setOutputKeyClass(IntWritable.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));job.waitForCompletion(true);logger.info (“Code ended”);}} |
On executing the above code through Hadoop framework, the below output would be generated.
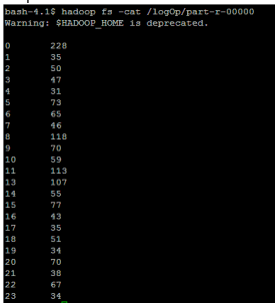
Here, with the generated analytics, we can determine the maintenance time which would impact the least number of users.