
CAPTCHA is an acronym for “Completely Automated Public Turing test to tell Computers and Humans Apart”. It is a test used to determine whether the user is human or not. A typical captcha consists of a distorted test, which a computer program cannot interpret but a human being can still read.
We need to bypass it when we plan to test authentication APIs. We will use Python and the Requests library for this blog.
The first step is to install the Python and Requests library. For Python, a version above 3.0 is recommended. For the Requests library, using the “pip install requests” command is a quick and easy way to install Requests in Windows. Then we can verify this software is installed successfully. No error message is the pop up for the ” import requests” command.
We will be using Zhihu.com as an example of how to bypass the captcha image and finish the authentication.
Capture the Requests of Zhihu Login
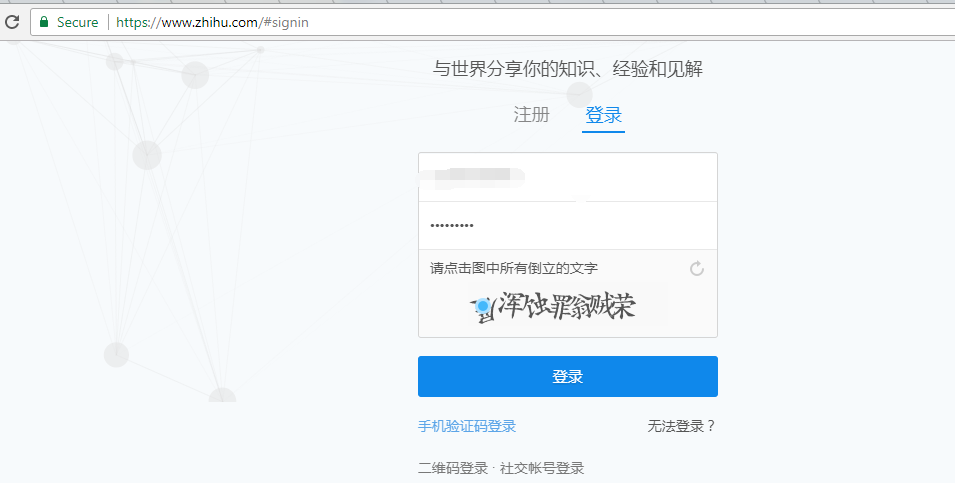
First I need to determine which parameters are needed to prepare to login Zhihu. I tried to log into the Zhihu site manually with a phone number to capture the authentication request. It needs a user to input a phone number and password and click on the inverted Chinese characters.
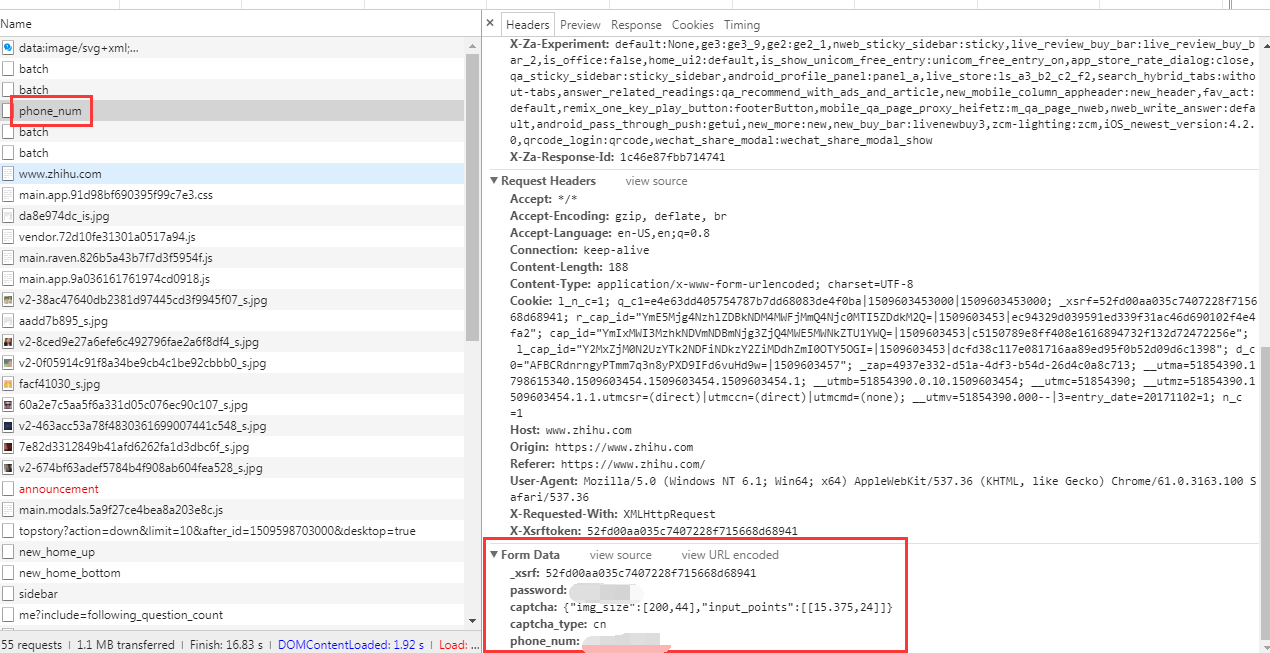
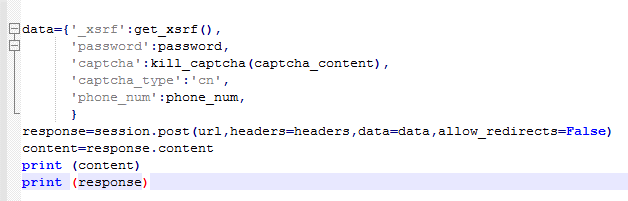
When I logged in successfully, I found a POST request called “phone_num”. What I want to do is make this request using a Python script. So I need to prepare the parameters in the Form Data:
“password” and “phone_num” are my input in login page.
“captcha_type” is invariable “cn”.
“_xsrf” and “captcha” is the variables.
“captcha” is the parameter about captcha image which we need to bypass.

Get Value of “_xsrf”
After research, I discovered that the value of “_xsrf” is hidden in the HTML code of the login page and changes every time. We can get it using a regular expression “name=”_xsrf” value=”(.*?)””.

Bypass the parameter of “captcha”
The value of “captcha” is related to the user clicking the inverted Chinese characters in the captcha image. The captcha image is changed every time. Let me analyze the value of “captcha”: {“img_size”:[200,44],”input_points”:[[40.375,23],[115.375,24]]}
I tried several times and found “img_size”:[200,44]” is fixed and it is the size of captcha image. And the value of “input_points” is referencing the locations of the inverted Chinese characters.
After searching, I found the solution: there are always 7 Chinese characters in the captcha image and the location of every Chinese character is almost fixed.
a. List all the locations of the 7 Chinese characters
![]()
b. Find the URL of the captcha image

c. Download the captcha image and let the user input the index of the inverted characters
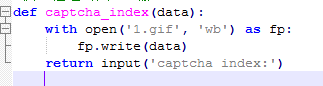
d. Get the value of the captcha

Make a request
At last, make a login request in Python.
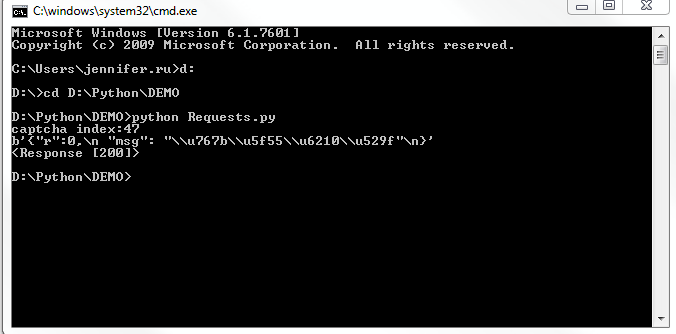
When I run the script, it returns 200 successfully.
Conclusion
This is the simple and comment way to bypass the captcha image for the sites to pass the clicking locations and most of clicking locations are fixed. However, we still need to read the captcha image manually. Maybe we can research more about solving the captcha image by program.