
What is Hive?
You may have heard about Data Warehousing products such as Oracle, Teradata Netezza which have been used in different industries for decades. Recently, Hive emerged as a new generation of the open-source data warehouse product which features clustered nodes in the big data domain. It facilitates reading, writing, and managing super large datasets residing in distributed storage using SQL. As the official site indicates, Hive is built on multiple distributed nodes of Hadoop and supports the standard SQL language to interact with data.
It has the following features (from https://cwiki.apache.org/confluence/display/Hive/Home):
- Tools to enable easy access to data via SQL, thus enabling data warehousing tasks such as extract/transform/load (ETL), reporting, and data analysis.
- A mechanism to impose structure on a variety of data formats
- Access to files stored either directly in Apache HDFS or in other data storage systems such as Apache HBase
- Query execution via Apache Tez, Apache Spark, or MapReduce
- Procedural language with HPL-SQL
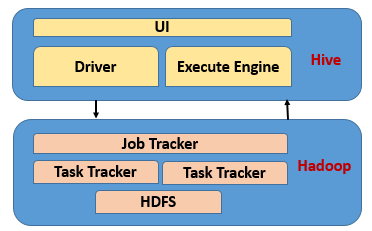
The diagram below illustrates how Hive receives and executes SQL command through UI.
What is HiveQL?

In short, HiveQL is a SQL-like manual language that can be run on the Hive platform to provide data summarization, query, and analysis by integrating with Hadoop. When the user is going to do the query against the Hive data warehouse, he or she can use the SQL close language. Hive provides the function to execute standard SQL and include many of the features in later versions for analytics. Occassionaly, however, the HiveQL syntax is a little bit different from the common SQL language that used in the traditional DBMS.
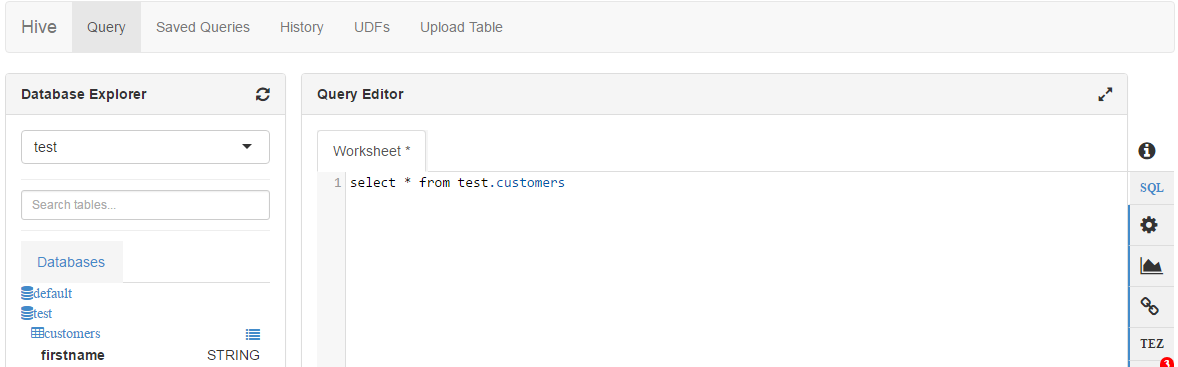
You don’t have to remember all of the complex syntax and data types. Instead, you can just refer to the wiki page when you are working on the query language. This page shows the Beeline command, data types, data definitional language, and data manipulation language. The quick way to query data is to develop and execute the SQL script in the Hive viewer.
Query Hive Data via Java Code
In addition to diagrams above, there are other ways to query or manipulate (insert, update, delete) data in the Hive table, such as WebHCat and HiveServer2. Even just for HiveServer2, several connection options are available: Beeline command, JDBC, Python client, and Ruby client. HiveServer 2 is based on Thrift service.
In the following example we will write the Java code in the Maven project to query data from Hive server.
1.Add the entries in your pom file

2.Write the code and run it in your IDE

Hi Kent, Hope you are doing well. I already have the working code to fetch data from hive using JDBC connectivity. The issue is I am getting slow response using JDBC connectivity. Now I am trying WebHcatalog for fetching the data from hive. Can you please provide the example code for WebHcatalog also. Thanks in advance.