Another interesting feature of SPSS Modeler is its built-in ability to sample data. It is pretty typical to have (in one or more files) hundreds of thousands of records to process, and using complete sets of data during testing can take a huge amount of your time and is inefficient in terms of computer processing time and memory.
TM1
From a TM1 perspective, think of sampling as “the selection of a subset of records from within a statistical population (a file)”. Keep in mind that the objective isn’t simply to reduce the size of the file but more to create a smaller version of the file that still is representative of the characteristics of the whole population (the whole file).
Sampling Methods
SPSS MODELER offers two sampling options:
Simple:
- Just select the first n records in the file
- Select every nth record (where n is to be specified)
- Select a random sample of size r %
Complex:
- This option enables finer control of the sample, including clustered, stratified, and weighted samples, etc.
Sampling in TM1
For the TM1 developer, nothing exists “out of the box” to create samples of data and you are (as usual) left to your (only) option of “building it yourself” using TurboIntegrator (TI) scripts- perhaps using functions such as “ItemSkip” and “Rand”. (Of course, to be fair, sampling is not something that TM1 is “built for”).
The Sample Node
Of course, SPSS Modeler features the sample node (found in the Record ops palette) which offers various methods to sample records without any programming or scripting.
The procedure to sample records is:
- Place a Sample node in your stream and
- Edit the Sample node to set the options for sampling!
Sample node and the Settings Tab
![]()

The Future of Big Data
With some guidance, you can craft a data platform that is right for your organization’s needs and gets the most return from your data capital.
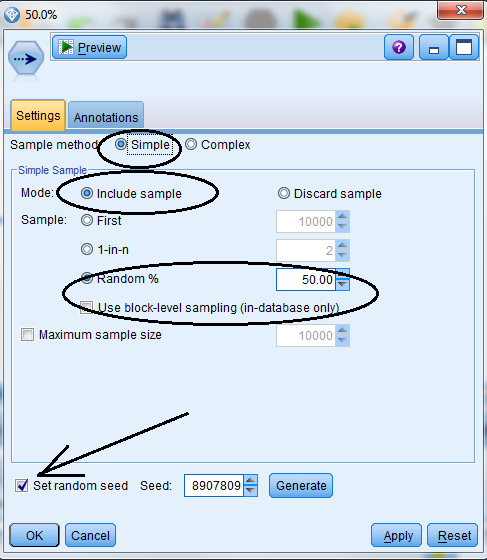
Using the Settings tab in the Sample node, you can easily set the options for your data sampling:
- Select Sampling method (Simple or Complex).
- The Mode allows you to either select records (include sample) or eliminate records (discard sample). If you select “Include sample” then you can also set the maximum size of the sample.
- The Sample option offers three possible methods of doing simple sampling: when a Random % sampling is requested, you can specify a random seed value so that the sample can be replicated in the future. (If no random seed is specified, then each time the Sample node is run with the Random % selected, a different random sample will be drawn, making it impossible to replicate earlier analyses).
The Generate button, when clicked, will generate a new random seed value.
Conclusion
Cognos TM1 is a tool that encourages rapid prototyping. Dimensions and Cubes can be snapped together and presented to subject matter experts for review. It is highly recommended that realistic data samples be loaded into prototyped models for best results. Using “made up” data or entire sets of actual data can be ineffectual. A realistic sampling set of data – based on actual data files – would increase the probability that “what you show” is a realistic representation of “what you will ultimately deliver”.
Clearly, SPSS Modeler handles sampling very well.