Google Artificial Intelligence in Search
As you will see in the transcript below, this discussion focused on the use of artificial intelligence algorithms in search. Peter outlines for us the approach used by Google on a number of interesting search problems, and how they view search problems in general. This is fascinating reading for those of you who want to get a deeper understanding of how search is evolving and the technological approaches that are driving it. The types of things that are detailed in this interview include:
- The basic approach used to build Google Translate
- The process Google uses to test and implement algorithm updates
- How voice-driven search works
- The methodology being used for image recognition
- How Google views speed in search
- How Google views the goals of search overall
Some of the particularly interesting tidbits include:
- Teaching automated translation systems vocabulary and grammar rules is not a viable approach. There are too many exceptions, and language changes and evolved rapidly. Google Translate uses a data-driven approach of finding millions of real-world translations on the web and learning from them.
- Chrome will auto translate foreign language websites for you on the fly (if you want it to).
- Google tests tens of thousands of algorithm changes per year, and make one to two actual changes every day
- Those tests are layered, starting with a panel of users comparing current and proposed results, perhaps a spin through the usability lab at Google, and finally with a live test with a small subset of actual Google users.
- Google Voice Search relies on 230 billion real-world search queries to learn all the different ways that people articulate given words. So people no longer need to train their speech recognition for their own voice, as Google has enough real-world examples to make that step unnecessary.
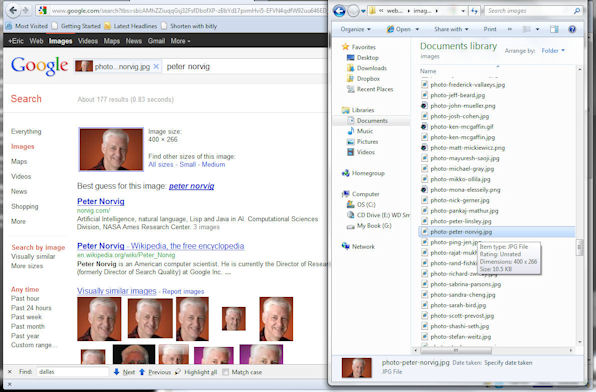
- Google Image search allows you to drag and drop images onto the search box, and it will try to figure out what it is for you. I show a screenshot of an example of this for you below. I LOVE that feature!
- Google is obsessed with speed. As Peter says “you want the answer before you’re done thinking of the question”. Expressed from a productivity perspective, if you don’t have the answer that soon your flow of thought will be interrupted.
Interview Transcript
Eric Enge: Can you outline at a layman’s level the basic approach that was used to allow Google engineers a translation system that handles 58 languages?
Peter Norvig: Sure — Google Translate uses a data-driven, machine learning approach to do automatic translation between languages. We learn from human examples of translation.
 |
To explain what I mean by “data-driven,” first I should explain how older machine translation systems worked. Programmers of those systems tried to teach the system vocabulary and grammar rules, like “This is a noun, this is a verb, and here’s how they fit together or conjugate in these two languages.”
Language is so fluid that programmers can’t keep up with the millions of words in all these languages and the billions or trillions of possible combinations, and how they change over time.
But it turns out that approach didn’t really work well. There were two problems:
- First, the formalisms for writing rules were absolute: this sentence is grammatical, and this other sentence is ungrammatical. But language has shades of gray, not just absolutes.
- Second, it is true that languages have rules, but it turned out that the rules don’t cover enough — language is more complicated and full of exceptions than people assumed, and is changing all the time. New words like “LOL” or “pwn” or “iPad” appear. Old words combine in unique ways — you can’t know what a “debt ceiling” is just by knowing what “debt” and “ceiling” are.
Even core grammatical rules are uncertain — is “they” okay to use as a gender-neutral pronoun? What is the grammatical structure of “the harder they come, the harder they fall,” and what else can you say with that structure? Language is so fluid that programmers can’t keep up with the millions of words in all these languages and the billions or trillions of possible combinations, and how they change over time. And there are too many languages to keep rewriting the rules for how each language translates into each of the other languages.
So the new approach is a data-driven approach. Recognizing that we’ll need lots of examples of how to handle exceptions, we make the leap of saying: what if we could learn everything — the exceptions and the rules — from examples? We program our computers to look on the web for millions of examples of real-world translations, and crunch all that data to find patterns for which phrases translate into which other phrases.
We use machine learning to look for recurring patterns — “this phrase in French always seems to translate into this phrase in English, but only when it’s near this word.” It’s analogous to the way you can look over a Chinese menu with English translations — if you see the same character keeps recurring for chicken dishes, you can guess pretty confidently that that character translates to “chicken.”
The basic idea is simple, but the details are complicated. We do some deep work on statistics and machine learning algorithms to be able to make the best use of our examples, and we were able to turn this technology into a world-leading consumer product. Google Research is a great place to come work if you want to tackle these kinds of problems in artificial intelligence.
If you visit a website in Thai or French or Urdu, Chrome will detect it and ask if you want to translate it into your native language.
We’re really pushing to have Translate available as a layer across lots of other products. You can always just go to translate.google.com, but it’s also built into our browser, Chrome. If you visit a website in Thai or French or Urdu, Chrome will detect it and ask if you want to translate it into your native language. It’ll automatically translate the whole page, and keep translating as you click on links. So you’re basically browsing the web in this other language. It’s very Star Trek.
There’s also a cool mobile app you should try — Google Translate for mobile is on Android and iPhone, and it does speech-to-text so you can speak and get translations.
 |

Eric Enge: How does Google manage the process of testing and qualifying algorithm updates?
Peter Norvig: Here’s how it works. Our engineers come up with some insight or technique and implement a change to the search ranking algorithm. They hope this will improve search results, but at this point, it’s just a hypothesis. So how do we know if it’s a good change? First, we have a panel of real users spread around the world try out the change, comparing it side by side against our unchanged algorithm. This is a blind test — they don’t know which is which. They rate the results, and from that, we get a rough sense of whether the change is better than the original. If it isn’t, we go back to the drawing board.
But if it looks good, we might next take it into our usability lab — a physical room where we can invite people in to try it out in person and give us more detailed feedback. Or we might run it live for a small percentage of actual Google users, and see whether the change is improving things for them. If all those experiments have positive results, we eventually roll out the change for everyone.
We test tens of thousands of hypotheses each year, and make maybe one or two actual changes to the search algorithm per day. That’s a lot of ideas and a lot of changes. It means the Google you’re using this year is improved quite a bit from the Google of last year, and the Google you’re using now is radically different from anything you used ten years ago.
If you define A.I. as providing a course of action in the face of uncertainty and ambiguity, based on learning from examples, that’s what our search algorithm is all about.
I’d say the resulting technology — Google Search as a whole — is a form of A.I. If you define A.I. as providing a course of action in the face of uncertainty and ambiguity, based on learning from examples, that’s what our search algorithm is all about.
The search engine has to understand what’s out on the web in text and other forms like images, books, videos, and rapidly changing content like news, and how it all fits together. Then it has to try to infer what the user is looking for, sometimes from no more than a keystroke or two. And then it has to weigh hundreds of factors against each other — hundreds of signals, like the links between content, the correlations among phrases, the location of the search, and so on — and provide the user information that’s relevant to their query, with some degree of confidence for each piece. And finally, it has to present that information in a coherent, useful way. And it has to be done potentially for each keystroke, since Google results update instantly now.
Every time people ask a question, you need this machine to automatically and instantly provide an answer that helps them out. It’s a deep A.I. problem, and I think we’re doing a good job at it today, but we’ve got lots of room to grow too. Search is far from solved, and we have plenty of room for experts in A.I., statistics, and other fields to jump on board and help us develop the next Google, and the Google after that.
Eric Enge: Voice driven search seems like a very interesting problem to me. Even if you are dealing with only one language you have a vast array of dialects, accents, pronunciations, and ways of phrasing things.
This used to be addressed by having the user “train the system” to their manner of speaking. Are we are the point where we are past that now? What are the basic methods (in layman’s terms) being used to make this possible? Will this expand to automatically transcribing videos?
Peter Norvig: Speech recognition is actually quite analogous to machine translation. In translation we learn from past examples of (English, Foreign) pairs how to translate a new sentence we haven’t seen before; in speech, we learn from past examples of (Soundwave, Text) pairs how to find the text in a new soundwave.
So instead of relying on one person talking for a long time to train the system, we rely on lots of people saying lots of things to train the system. So in effect, our users are training the system en masse.
Like you say, in old systems, you’d have to sit there and train the thing for an hour before it would recognize your words. We wanted to build something anyone could pick up and just immediately start talking to and have it understand them right away. So instead of relying on one person talking for a long time to train the system, we rely on lots of people saying lots of things to train the system. So in effect, our users are training the system en masse.
 |
I can explain a little more how it actually works. There are three parts to our speech model. First, there’s the acoustic model, which maps out all the possible ways soundwaves can form phonemes, like “ah” or “mm” or “buh.” It’s tricky because acoustics vary a lot by what kind of mic you’re using, what background noise there is, how you’re holding the device, the gender, and age of the speaker, and even what sounds come before or after the one you’re making. And like you say, there are lots of versions because accents and dialects vary so much. But with enough examples of speech, we can model what are the most likely ways of forming phonemes.
Then phonemes come together in our lexical model, which is basically a dictionary of how all the words in a language are pronounced. That also takes care of a lot of differences in accents — the model knows that there are multiple ways to pronounce things, and knows which are more or less likely. “Feb-yoo-ary” and “Feb-roo-ary” will both give you “February,” because the model sees both spoken a lot.
Finally, the words are strung together into a language model, which tells you which words are most likely to come after another word. There might be a soundwave that sounds like either “city” or “silly”, but if it follows the words “New York…” then the language model would tell us that “city” is more likely. We have a lot of text to train the system on — for Voice Search, where you speak your search to Google, we train this model on around 230 billion words from real-world search queries.
It’s all anonymized, of course — we don’t keep any training examples that could be tied to an individual speaker; it is all combined into our big model. We do give you the choice to opt-in to have us learn from your own voice over time. You can turn this on, and the model will start to learn how your voice varies from our baseline model — say, if you have a strong accent or a really deep voice. The model works well even without having to train it yourself, but you have the option to make it even better.
You can try this out on an Android phone or on the Google Search app on iPhone or Blackberry. On Android you can search, of course, but you can also compose emails by voice, or for that matter speak into any app where you’d use the keyboard — we added it into the Android keyboard so you can speak pretty much anywhere you might type. It’s also on Google on the desktop if you use Chrome.
Eric Enge: How about the problem of image recognition? For example, can we train a computer to recognize an image of the Taj Majal?
Peter Norvig: Yes. We do this on mobile phones and now on desktop Google Search too. You can actually use it to see where old vacation photos were taken — ones you scanned from back before digital cameras geo-tagged photos. If you took a photo of some cool-looking bridge you don’t recognize, and you can drag and drop the image onto the Google Search box, and there’s a pretty good chance it’ll recognize the bridge, tell you what it is, and give you all kinds of relevant information on it.
 |
As with speech and translation, image recognition is data-driven and relies on machine learning algorithms across lots of examples. Luckily for us, the web has lots and lots of images of things, and most of them have captions that identify them. The more popular, the more images, so the better a chance we have at our algorithms being able to recognize it.
Here’s how image recognition works in a nutshell. It starts with identifying points of interest in an image — the points, lines, and patterns that provide sharp contrasts or really stick out from a bland, featureless background. It’s similar in some ways to how the human eye picks out edges and points by keying off the places where there’s sharp contrast.
Then it looks at how these points are related to each other — the geometry of the whole set of points. You could picture it as looking like a constellation of stars, even though really it’s a more sophisticated mathematical model of these points of interest and how they relate.
Now it compares that model to all the other models in a huge database. Those other models come from images it has already analyzed from around the web. It looks for a matching model, but it doesn’t have to be a perfect match. In fact, it’s important that it be a bit flexible, so it doesn’t matter if it’s turned around, or shrunken, or twisted a bit. The Taj Mahal still has the basic geometry of the Taj Mahal even if you photograph it from a little bit of a different angle or photograph it lower in the frame. When Google recognizes that it matches that model best, it guesses it’s probably the Taj Mahal.
There’s something profound here about asking a “question” that’s actually just an image. We’ve moved beyond every query being a string of text. Now you can just present Google an image and expect relevant information.
There’s something profound here about asking a “question” that’s actually just an image. We’ve moved beyond every query being a string of text. Now you can just present Google an image and expect relevant information. So it puts even more burden on the search engine to know what that’s supposed to mean. What’s the best answer to a question when the question is an image? We present some information we think is relevant today, but what exactly the interaction should be here is still ripe for research.
Eric Enge: For some of these tasks we currently must rely on batch processing instead of real-time processing (e.g. the way that the Panda algorithm currently operates). How long before the processing power increases to the point where the Panda algorithm can be done in real time?
Peter Norvig: I wouldn’t separate out that one update from the rest of the Search algorithm that way; it was really just one improvement among many that we’ve made in the past year or so. But the question is certainly relevant to our Search algorithm overall.
Broadly speaking, you can think of the growth of the web and the growth of the computing power needed to instantly index it as a kind of arms race.
Broadly speaking, you can think of the growth of the web and the growth of the computing power needed to instantly index it as a kind of arms race. The web keeps growing. There’s a misperception that the web has become established or matured, but in fact, the growth curve is a nice smooth exponential that hasn’t shown signs of slowing down yet. We’re still in the middle of the information explosion.
So we keep up with it a few ways. It helps that processors and disks keep getting cheaper. Even new categories of technology, like solid-state disks, have helped. We’re also getting smarter about delineating which content needs to be updated instantly, and which can be updated more slowly — again, we learn how to do this from examples. A lot of the smarts you see in Google Instant, and the predictive input suggestions that keeps guessing what word you might type next, are about anticipating what information is most likely to be needed, and queuing that up so it’s ready to go.
 |
We’re really obsessed with speed at Google. Speed is a crucial feature of any information-intensive product. You never want your tools to slow you down or interrupt your flow of thought. There’s a cool feature we launched a little while ago called Instant Pages which takes Google Instant a step further: instead of just predicting what words you might type, and pre-loading the search results, if Google is really confident that the first result is the right one, it’ll start loading it in the background. So often by the time you click that result, it’s already loaded up — so the website appears to load instantly. It’s like a magic trick when it works well.
Eric Enge: Can you expound a little bit on the types of problems that AI can work on solving in the area of search over the next 5 years?
So you want the answer almost before you’re done thinking of the question. We think we can offer that now most of the time.
Peter Norvig: We’ll work more on speed. It used to be that a few seconds was really fast to learn what the height of the Eiffel Tower was — that’s a heck of a lot faster than a trip to the library to look it up in a reference book in the back shelves. But now even a few seconds feels slow, because again, it interrupts your flow of thought. So you want the answer almost before you’re done thinking of the question. We think we can offer that now most of the time.
But eventually, this will stop being such a back-and-forth question-and-answer routine, and start just being a steady flow of relevant information. It should be right there when you need it, presented so it’s useful without being overwhelming. It’s going to take a lot of engineering and a really fine artistic touch to make that work the way we envision it.
And of course this gets to a deeper A.I. problem: not just understanding information and queries, but really understanding what the user needs and will find useful at a given moment, and serving it up in a way that’s perfectly digestible. It’s not just about human-computer interaction or information retrieval. It’s about how people learn and attain knowledge. We’re trying to move beyond just presenting information, and really focus on increasing people’s knowledge of the world. So Google needs to be “smart” in the sense of really understanding the user’s needs in order to help them build up their knowledge of the world.
Eric Enge: Thanks Peter!
About Peter
 Peter Norvig is a Fellow of the American Association for Artificial Intelligence and the Association for Computing Machinery. At Google Inc he was Director of Search Quality, responsible for the core web search algorithms from 2002-2005, and has been Director of Research from 2005 on.
Peter Norvig is a Fellow of the American Association for Artificial Intelligence and the Association for Computing Machinery. At Google Inc he was Director of Search Quality, responsible for the core web search algorithms from 2002-2005, and has been Director of Research from 2005 on.
Previously he was the head of the Computational Sciences Division at NASA Ames Research Center, making him NASA’s senior computer scientist. He received the NASA Exceptional Achievement Award in 2001. He has served as an assistant professor at the University of Southern California and a research faculty member at the University of California at Berkeley Computer Science Department, from which he received a Ph.D. in 1986 and the distinguished alumni award in 2006. He has over fifty publications in Computer Science, concentrating on Artificial Intelligence, Natural Language Processing and Software Engineering, including the books Artificial Intelligence: A Modern Approach (the leading textbook in the field), Paradigms of AI Programming: Case Studies in Common Lisp, Verbmobil: A Translation System for Face-to-Face Dialog, and Intelligent Help Systems for UNIX. He is also the author of the Gettysburg Powerpoint Presentation and the world’s longest palindromic sentence.
Other Recent Interviews
Google’s Mayuresh Saoji, October 10, 2011
Google’s Frederick Vallaeys, September 29, 2011
Bing’s Ping Jen, September 28, 2011
Bing’s Duane Forrester, September 6, 2011
Danny Sullivan, August 8, 2011
Bruce Clay, August 1, 2011
Google’s Tiffany Oberoi, July 27, 2011
Vanessa Fox, July 12, 2011
Jim Sterne, July 5, 2011
Stephan Spencer, June 20, 2011
SEOmoz’ Rand Fishkin, May 23, 2011
Bing’s Stefan Weitz, May 16, 2011
Bing’s Mikko Ollila, June 27, 2010
Yahoo’s Shashi Seth, June 20, 2010
Google’s Carter Maslan, May 6, 2010
Google’s Frederick Vallaeys, April 27, 2010
Matt Cutts, March 14, 2010