
The evolution of AI is advancing at a rapid pace, progressing from Generative AI to AI agents, and from AI agents to Agentic AI.Many companies are developing their own AI tools, training The LLM specifically to enhance images, audio, video, and text communications with a human-like touch. However, the data used in these tools is often not protected, as it is directly incorporated into training the Large Language Models (LLMs).
Have you ever wondered how organizations can leverage LLMs while still keeping their data private? The key approach to achieve this enhancement is Retrieval-Augmented Generation (RAG).
Retrieval-Augmented Generation (RAG) is a framework where relevant information is retrieved from external sources (like private documents or live databases) and provided to the LLM as immediate context. While the LLM is not aware of the entire external dataset, it uses its reasoning capabilities to synthesize the specific retrieved snippets into a coherent, human-like response tailored to the user’s prompt.
How does RAG works?
Retrieval phase from document:
1.External Documents
We manage extensive repositories comprising thousands of external PDF source documents to provide a deep knowledge base for our models.
- The Chunking Process
To handle large-scale text, we break documents into smaller “chunks.” This is essential because Large Language Models (LLMs) have a finite context window and can only process a limited amount of text at one time.
Example: If a document contains 100 lines and each chunk has a capacity of 10 lines, the document is divided into 10 distinct chunks.
- Chunk Overlap
To maintain continuity and preserve context between adjacent segments, we include overlapping lines in consecutive chunks. This ensures that no critical information is lost at the “seams” of a split.
Example: With a 1-line overlap, Chunk 1 covers lines 1–10, Chunk 2 covers lines 10–19, and Chunk 3 covers lines 19–28.
- Embedding Process
Once chunked, the text is converted into Embeddings. During this process, each chunk is transformed into a Vector—a list of numerical values that represent the semantic meaning of the text.
- Example Vector: [0.12, -0.05, …, 0.78]
- Indexing & Storage
The generated vectors are stored in specialized vector databases such as FAISS, Pinecone, or Chroma.
- Mapping: Each vector is stored alongside its corresponding text chunk.
- Efficiency: This mapping ensures high-speed retrieval, allowing the system to find the most relevant text based on vector similarity during a search operation.
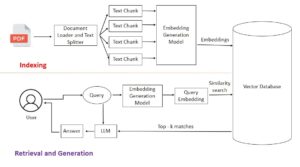
The Augmentation Phase: Turning Data into Answers

Once your documents are indexed, the system follows a specific workflow to generate accurate, context-aware responses.
- User Query & Embedding
The process begins when a user submits a prompt or question. This natural language input is immediately converted into a numerical vector using the same embedding model used during the indexing phase.
- Vector Database Retrieval
The system performs a similarity search within the vector database (e.g., Pinecone or FAISS). It identifies and retrieves the top-ranked text chunks that are most mathematically relevant to the user’s specific question.
- Prompt Augmentation
The retrieved “context” chunks are then combined with the user’s original question. This step is known as Augmentation. By adding this external data, we provide the LLM with the specific facts it needs to answer accurately without “hallucinating.”
- Final Prompt Construction
The system constructs a final, comprehensive prompt to be sent to the LLM.
The Formula: > Final Prompt = [User Question] + [Retrieved Contextual Data]
Generation phase:
This is the final stage of the RAG (Retrieval-Augmented Generation) workflow.
Augmented prompt is fed into the LLM,LLM synthesizes the retrieved context to craft a precise, natural-sounding response. Thus transforming thousands of pages of raw data into a single, highly relevant and accurate answer.
Application of RAG Industries
- Healthcare & Life Sciences
- Finance & Banking
- Customer Support & eCommerce
- Manufacturing & Engineering
Conclusion:
Retrieval-Augmented Generation (RAG) merges robust retrieval mechanisms with generative AI. This architecture provides a scalable, up-to-date framework for high-stakes applications like enterprise knowledge assistants and intelligent chatbots. By evolving standard RAG into Agentic RAG, we empower AI agents to move beyond passive retrieval, allowing them to reason, iterate, and orchestrate complex workflows. Together, these technologies form a definitive foundation for building precise, enterprise-ready AI systems.