
In this post, I would like to walk you through the approach by which we can provide the column mappings as a dynamic content in copy data activities in Azure Data Factory using a table placed in a database.
Why there is a need to provide the column mappings as a dynamic content?
We can use the ‘Import Schemas’ option under Mapping to fetch the source and target columns and map them manually, which is useful while using the copy data activity for a single table. However, when we use the copy activity under a for each loop, the table and its respective mappings will be changed for every run in the ForEach loop where it is required to provide the column mappings as a dynamic content based on the respective table of the ForEach run.
There are two approaches for providing the column mappings in the copy data activity.
1.Explicit Manual Mapping: It requires manual setup of mappings for each column inside the copy data activity, which is a time-consuming approach.
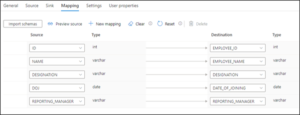
2.Default Mapping: By leaving the mapping properties blank, the Copy Data activity will take the source columns and map them to columns in the target table in a case-sensitive manner. This option allows reusable copy data activities on the condition that the source and target are also set up dynamically.
Mapping Configuration Table:
To provide the column mappings as a dynamic content in the copy data activity, we need to create a configuration table to hold the predefined column mappings which can be fetched at the runtime based on the required table by converting in an acceptable format. Below is the table creation query used to create the Mapping Table:
CREATE TABLE MAPPINGTABLE ( M_ID INT IDENTITY (1,1) NOT NULL, SCHEMA_NAME VARCHAR(MAX), TABLE_NAME VARCHAR(MAX), SOURCE_COLUMN VARCHAR(MAX), TARGET_COLUMN VARCHAR(MAX), PRIMARY KEY (M_ID)) );
Below is the query used to insert the data in the Mapping Table:
INSERT INTO MAPPINGTABLE
(SCHEMA_NAME, TABLE_NAME, SOURCE_COLUMN, TARGET_COLUMN)
VALUES
('DBO','EMPLOYEE', '[EMPLOYEE_ID, EMPLOYEE_NAME, DESIGNATION, DATE_OF_JOINING, REPORTING_MANAGER]', '[EMPLOYEE_ID, EMPLOYEE_NAME, DESIGNATION, DATE_OF_JOINING, REPORTING_MANAGER]');

The table should look like below:
Select * from MAPPINGTABLE;

Once the table is created with all the required values, we need a stored procedure that will convert the data from mapping table into an acceptable JSON format for the dynamic content.
Below is the stored procedure used to convert the data into an acceptable JSON format:
CREATE PROCEDURE [dbo].[sp_getColumnMapping]
@schema_name VARCHAR(100),
@table_name VARCHAR(100)
AS
BEGIN
DECLARE @json_construct varchar(MAX) = '{"type": "TabularTranslator", "mappings": {X}}';
DECLARE @json VARCHAR(MAX);
SET @json = (Select srccol.value as 'source.name', trgcol.value as 'target.name' from dbo.MappingTable c cross apply STRING_SPLIT(replace(replace(source_column,'[',''),']',''),',') as srccol cross apply STRING_SPLIT(replace(replace(Target_Column,'[',''),']',''),',') as trgcol WHERE [schema_name] = @schema_name AND [table_name] = @table_name AND srccol.value=trgcol.value FOR JSON PATH);
SELECT REPLACE(@json_construct,'{X}', @json) AS json_output;
END
GO
If we execute the above Stored Procedure with the provided schema name and table name it will return the below JSON output:
{
"type": "TabularTranslator",
"mappings": [
{
"source": {
"name": "EMPLOYEE_ID"
},
"target": {
"name": "EMPLOYEE_ID"
}
},
{
"source": {
"name": "EMPLOYEE_NAME"
},
"target": {
"name": "EMPLOYEE_NAME"
}
},
{
"source": {
"name": "DESIGNATION"
},
"target": {
"name": "DESIGNATION"
}
},
{
"source": {
"name": "DATE_OF_JOINING"
},
"target": {
"name": "DATE_OF_JOINING"
}
},
{
"source": {
"name": "REPORTING_MANAGER"
},
"target": {
"name": "REPORTING_MANAGER"
}
}
]
}
Data Factory Lookup & Mapping Setup:
From the Lookup’s settings, select the Stored Procedure option and provided the name of the SP we have created in the previous step. Import the parameters and provide the appropriate values.
Note: While using this Lookup inside a ForEach loop, you are supposed to provide the parameter values a dynamic content (Like @item().SchemaName or @item().TableName)
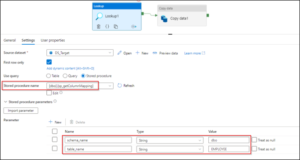
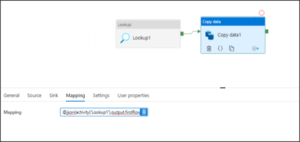
Now, we need to pass the output of this Lookup to the copy data activity as a dynamic content under Mappings.
Note: There are two parameters created inside a stored procedure namely schema_name and table_name.
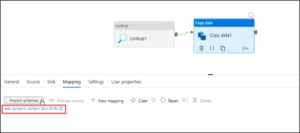
Now, go to Copy Data activity and select Mapping tab, Add dynamic content to the mapping properties. The syntax should look like below:
@json(activity('Lookup_name').output.firstRow.column_name)

Nicely put, Kudos Shubham!!
very informative.. thanks for sharing Shubham
Hi,
When i try to do dynamic mapping of JSON schema getting the error “Required property ‘source’ is missing in payload”. Could you please help me on how we can fix this issue.
Thanks in Advance
Hello Venkattaramanan V,
I faced this error: “Required property ‘sink’ is missing in payload”. The way I solved it was to double-check that my stored procedure was using the proper names:
I used to have: srccol.value as ‘source.name’, trgcol.value as ‘target.name’… , and I changed it to: srccol.value as ‘source.name’, trgcol.value as ‘sink.name’…. and it’s working now.
Hello Venkattaramanan V,
Thanks for this nicely written article.
If anyone of you trying this out face an issue like: type conversion.
For example:
The given value of type Byte[] from the data source cannot be converted to type nvarchar of the specified target.
To resolve this, modify the stored procedure to allow type conversion like this:
DECLARE @json_construct varchar(MAX) = ‘{“type”: “TabularTranslator”, “mappings”: {X}, “typeConversion”: true, “typeConversionSettings”: {“allowDataTruncation”: true, “treatBooleanAsNumber”: false}}’;
Thanks,
Derik Roby
Hello Venkattaramanan V,
i have a question regarding your stored procedure. If i have my source and target columns the same, then i get an json output, but if i have my source names diffrent (e.g. technical names from the source system) and want them to have diffrent names, i can’t get the mapping to work. It returns NULL as the json_output.
Example by using your example:
VALUES
(‘dbo’,’EMPLOYEE’, ‘[EMPLOYEE_ID, EMPLOYEE_NAME, DESIGNATION, DATE_OF_JOINING, REPORTING_MANAGER]’, ‘[em_id, em_name, desig, date_joining, manager]’)
This will return me NULL
Any idea how i can get your procedure to work like this? EMPLOYEE_ID –> em_id, EMPLOYEE_NAME –> em_name etc.
Thanks,
Ray
According to me, You can set the target name at field level in your Entity class. for that you can use Hibernate Column property.
Ex.
@Column(name=”EMPLOYEE_ID”)
private Integer em_id;
I hope this can solve your problem.
Thank you, Bhushan
Hello Venkattaramanan V,
Thanks for this article. In our ADF pipeline we are also using additional columns. When I add those additional columns in the mappingtable, i get the following error: ‘The column ‘columnname’ is not found in source side. How can I ensure that these columns are also loaded?
Thanks in advance.
Is already resolved:
‘Thanks for this article. In our ADF pipeline we are also using additional columns. When I add those additional columns in the mappingtable, i get the following error: ‘The column ‘columnname’ is not found in source side. How can I ensure that these columns are also loaded?’
Having the same issue that DJ referenced in regards to the additional columns.