
General Introduction
- Splunk Connect for Kafka is a sink connector that allows a Splunk software administrator to subscribe to a Kafka topic and stream the data to the Splunk HTTP Event Collector. After the Splunk platform indexes the events, you can then directly analyze the data or use it as a contextual data feed to correlate with other Kafka-related data in the Splunk platform.
- There are primarily two methods for getting metrics into Splunk when using agents such etcd and collectd. Either using a Direct TCP/UDP input or via the HEC. Using Http Event Collector(HEC) is considered a best practice due to the resiliency and scalability of the HEC endpoint, and the ability to horizontally scale the collection tier easily.
Universal Splunk Forwarders
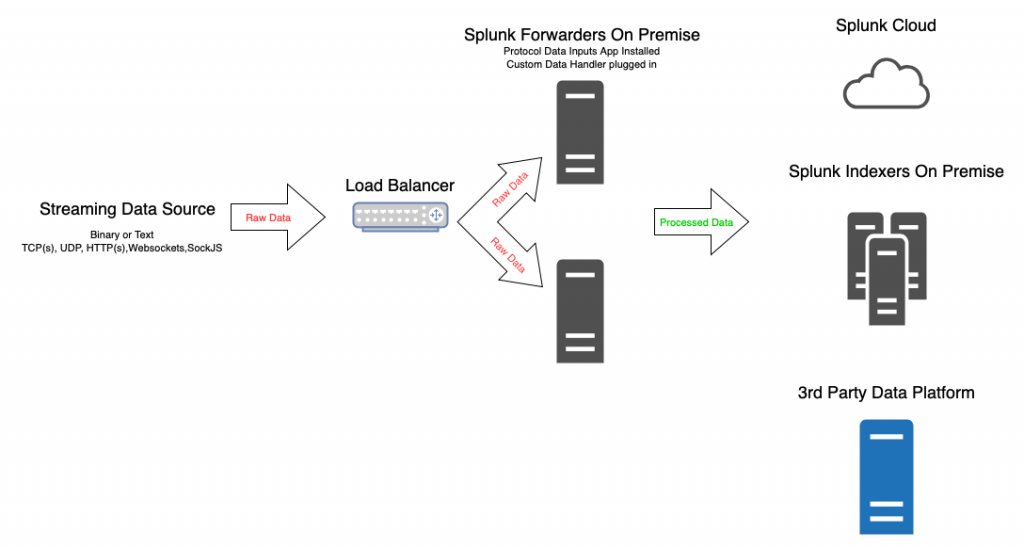
Splunk Use-Case Modelling
Splunk Connect For Kafka
Splunk Connect for Kafka introduces a scalable approach to tap into the growing volume of data flowing into Kafka. With the largest Kafka clusters processing over one trillion messages per day and Splunk deployments reaching petabytes ingested per day, this scalability is critical.
Overall, the connector provides:
- High scalability, allowing linear scaling, limited only by the hardware supplied to the Kafka Connect environment
- High reliability by ensuring at-least-once delivery of data to Splunk
- Ease of data onboarding and simple configuration with Kafka Connect framework and Splunk’s HTTP Event Collector
Procedural Flow
Step 1: Start Zookeeper Server
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don’t already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node ZooKeeper instance.
> bin/zookeeper-server-start.sh config/zookeeper.properties
[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
...
Step 2: Start Kafka Cluster
After starting the Zookeeper server, Kafka Clusters and brokers can able to run properly without any interuptions
> bin/kafka-server-start.sh config/server.properties
[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
...
Step 3: Create a topic

Let’s create a topic named “test” with a single partition and only one replica:
> bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
We can now see that topic if we run the list topic command:
> bin/kafka-topics.sh --list --bootstrap-server localhost:9092
test
Alternatively, instead of manually creating topics you can also configure your brokers to auto-create topics when a non-existent topic is published.
How it Works
As a sink connector, Splunk Connect for Kafka takes advantage of the Kafka Connect framework to horizontally scale workers to push data from Kafka topics to Splunk Enterprise or Splunk Cloud. Once the plugin is installed and configured on a Kafka Connect cluster, new tasks will run to consume records from the selected Kafka topics and send them to your Splunk indexers through HTTP Event Collector, either directly or through a load balancer.
Key configurations include:
- Load Balancing by specifying list of indexers, or using a load balancer
- Indexer Acknowledgements for guaranteed at-least-once delivery (if using a load balancer, sticky sessions must be enabled)
- Index Routing using connector configuration by specifying 1-to-1 mapping of topics to indexes, or using props.conf on indexers for record level routing
- Metrics using collectd, raw mode, and collectd_http pre-trained sourcetype
Where can I get it?
- The latest release is available on Splunkbase
- The Kafka Connect project is also open sourced and available on GitHub
Deployment Considerations
- Clone the repo from https://github.com/splunk/kafka-connect-splunk
- Verify that Java8 JRE or JDK is installed.
- Run
mvn package. This will build the jar in the /target directory. The name will besplunk-kafka-connect-[VERSION].jar.
First, we need to get our hands on the packaged JAR file (see above) and install it across all Kafka Connect cluster nodes that will be running the Splunk connector. Kafka Connect has two modes of operation—Standalone mode and Distributed mode. To start Kafka Connect we run the following command from the $KAFKA_CONNECT_HOME directory, accompanied with the worker properties file connect-distributed.properties. Ensure that your Kafka cluster and zookeeper are running.
Establish Connection
Run .$KAFKA_HOME/bin/connect-distributed.sh $KAFKA_HOME/config/connect-distributed.properties to start Kafka Connect.
Kafka ships with a few default properties files, however the Splunk Connector requires the below worker properties to function correctly. connect-distributed.properties can be modified or a new properties file can be created.
Note the two options that need some extra configuration:
- bootstrap.servers – This is a comma-separated list of where your Kafka brokers are located.
- plugin.path – To make the JAR visible to Kafka Connect, we need to ensure that when Kafka Connect is started that the plugin path variable is folder path location of where your connector was installed to in the earlier section.
Configuration Properties
#These settings may already be configured if you have deployed a connector in your Kafka Connect Environment bootstrap.servers=<BOOTSTRAP_SERVERS> plugin.path=<PLUGIN_PATH> #Required key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=org.apache.kafka.connect.storage.StringConverter key.converter.schemas.enable=false value.converter.schemas.enable=false internal.key.converter=org.apache.kafka.connect.json.JsonConverter internal.value.converter=org.apache.kafka.connect.json.JsonConverter internal.key.converter.schemas.enable=false internal.value.converter.schemas.enable=false offset.flush.interval.ms=10000 #Recommended group.id=kafka-connect-splunk-hec-sink
Run the following command to create connector tasks. Adjust topics to configure the Kafka topic to be ingested, splunk.indexes to set the destination Splunk indexes, splunk.hec.token to set your Http Event Collector (HEC) token and splunk.hec.uri to the URI for your destination Splunk HEC endpoint.
Splunk Indexing using HEC Endpoint
curl <hostname>:8083/connectors -X POST -H "Content-Type: application/json" -d'{
"name": "kafka-connect-splunk",
"config": {
"connector.class": "com.splunk.kafka.connect.SplunkSinkConnector",
“tasks.max": "1",
"topics": "topic_name",
"splunk.hec.uri":"https://localhost:8088",
"splunk.hec.token": "1B901D2B-576D-40CD-AF1E-98141B499534",
"splunk.hec.ack.enabled : "true",
"splunk.hec.raw" : "false",
"splunk.hec.ssl.validate.certs": "false",
"splunk.hec.track.data" : "true"
}
}' | jq
Now is a good time to check that the Splunk Connect for Kafka has been installed correctly and is ready to be deployed. Verify that data is flowing into your Splunk platform instance by searching using the index specified in the configuration. Use the following commands to check status, and manage connectors and tasks:
Useful Commands
# List active connectors
curl http://localhost:8083/connectors
# Get kafka-connect-splunk connector status
curl http://localhost:8083/connectors/kafka-connect-splunk/status | jq
# Get kafka-connect-splunk connector config info
curl http://localhost:8083/connectors/kafka-connect-splunk/config
# Delete kafka-connect-splunk connector
curl http://localhost:8083/connectors/kafka-connect-splunk -X DELETE
# Get kafka-connect-splunk connector task info
curl http://localhost:8083/connectors/kafka-connect-splunk/tasks
Lokesh, I have a cluster of 5 worker nodes. Should i start the connector(establish the connection) on all worker nodes? or just establishing the connection from one worker node will automatically balance the load from all the brokers.
In my “$KAFKA_HOME/config/connect-distributed.properties” I have listed all the worker nodes in the configs
Looking forward to getting more updates and we play a small role in upskilling people providing the latest tech courses. Join us to upgrade on BIG DATA SPLUNK ONLINE TRAINING
Great read! Thank you for such useful insights. Visit here for advanced technical courses on BIG DATA SPLUNK ONLINE TRAINING