I’ve seen and written a lot of background jobs in my career and in my experience, they are most common culprits to hard-to-diagnose issues in website operations.
Which of course makes sense, background jobs aren’t visible to website maintainers or users so how do you know something is wrong until a job fails or makes catastrophic changes?
This is why, with background jobs, it’s even more important than your standard component code to ensure the job executes successfully. The three aspects to a perfect background job are that the job is configurable, executable and monitorable.
Configurable
Providing a method to configure the job is critical to avoid having to introduce unnecessary production changes. There are many different ways to provide configurations to a background job and depending on your needs some will be more appropriate than others. Some of the more common options include content configurations, cloud service configurations and OSGi configurations.
Content Configurations
Content configurations are most appropriate for jobs for which the configuration could change frequently and may be changed by power users as well as administrators. The disadvantage to content configurations is that you need to write the component code to edit these configurations and additional code to read them. Content configuration can include both configurations within a page or other piece of content as well as configuration at the site or sub-site level using Apache Sling Content Aware (/conf) Configurations. Additionally, having a content configuration increases the risk of a miss-configuration causing job failure or unexpected results. Making it easy to configure, can make it easy to screw up.
Cloud Service Configurations
Cloud Service configurations are especially appropriate for jobs that match the cloud service paradigm, being a connection to an external service which is configured at a site or site section level. There still is some work in creating an editor for the configuration, but there are good patterns to follow and using the Cloud Service configuration framework you have an easy way to apply the configurations to different sites.
OSGi Configurations
The
OSGi framework provides a system level mechanism of configurations.
These configurations should not be used if you want to have different
configurations for different sites, but can be very useful for providing
global settings. Since OSGi configurations are built into the
framework, setting and retrieving properties is almost effortless as the
OSGi framework provides a method for getting the properties in a
service and a console for setting the configurations.
Lets
just say that you were writing a job to retrieve a JSON file from a URL
and performed some operations with the results. This would probably
make sense to configure with OSGi as it’s not configured for multiple
sites or configured by power users. In this configuration we’ll provide
configurations the scheduler interval for the job to run and URL to
retrieve the JSON file:
@Component(service = { Runnable.class}, property = {
"scheduler.expression=0 * * * * ?" }, immediate=true)
@Designate(ocd = Config.class)
public class BackgroundJobImpl implements Runnable {
private static final Logger log = LoggerFactory.getLogger(BackgroundJobImpl.class);
private String feedUrl;
@ObjectClassDefinition(name = "Background Job Configuration")
public @interface Config {
String feedUrl();
}
@Activate
public void activate(Config config) {
log.info("activate");
this.feedUrl = config.feedUrl();
}
[...]
}

This configuration creates an entry in the OSGi Configuration Console like this:
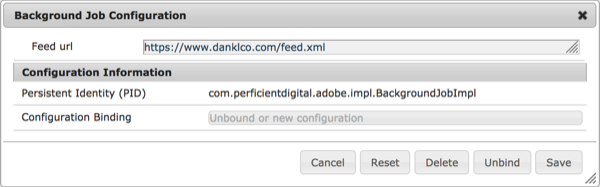
Often it makes sense to combine multiple options. OSGi configuration can be used store their credentials and URL information for a service, while Cloud Service configurations provide the particular configuration settings and apply the configuration to a site.
Executable
You’re
creating a background job so why does it need to be executable? The
answer is simple, what if it doesn’t run as you expect? Having a
background job that you can’t execute directly means that if you need to
run an import manually or correct some problem and re-execute or try to
diagnose what went wrong, you have to set the job up to execute again
which could mean modifying a cron expression or sending a OSGi Event or who knows what else. Being able to execute the job directly makes whoever maintains the jobs life easier.
If
you have content configurations or Cloud Service configurations for
your job, this could mean creating a simple Servlet or you can provide a
JMX MBean which will expose your job through the JMX console. From there, you can execute the methods in your MBean and see the results.
To
support execution, let’s add a MBean which allows administrators to
execute the job directly as well as seeing the last status of the job:
/**
* MBean interface for the Background Job
*/
@ProviderType
@Description("MBean for managing the Background Job")
public interface BackgroundJobMBean {
/**
* Synchronously executes the job, returns if the job executes
* successfully and throws an exception if the job fails to execute
*/
@Description("Run the background job")
public void runJob() throws Exception;
/**
* Gets the last status of the job as a string
*/
public String getLastStatus();
}
@Component(service = { DynamicMBean.class, Runnable.class }, property = {
"scheduler.expression=0 * * * * ?", "jmx.objectname=com.perficientdigital.adobe:type=BackgroundJob" }, immediate=true)
@Designate(ocd = Config.class)
public class BackgroundJobImpl extends AnnotatedStandardMBean implements BackgroundJobMBean, Runnable {
private Entry last = null;
private static final Logger log = LoggerFactory.getLogger(BackgroundJobImpl.class);
public BackgroundJobImpl() throws NotCompliantMBeanException {
super(BackgroundJobMBean.class);
}
protected BackgroundJobImpl(Class mbeanInterface) throws NotCompliantMBeanException {
super(mbeanInterface);
}
private String feedUrl;
@ObjectClassDefinition(name = "Background Job Configuration")
public @interface Config {
String feedUrl();
}
@Activate
public void activate(Config config) {
log.info("activate");
this.feedUrl = config.feedUrl();
}
@Override
public String getLastStatus() {
return last.toString();
}
@Override
public void run() {
[...]
}
@Override
public void runJob() throws Exception {
run();
}
}
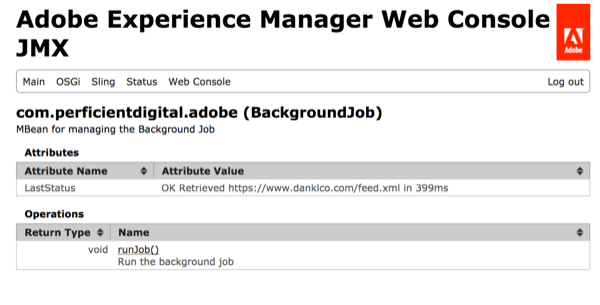
Once your MBean is installed, it will appear in the JMX Console as such:
Monitorable
Logs are one valuable way to understand what is happening in a background job, however it is difficult to determine state with just logs and providing proactive monitoring requires log monitoring and alerts. Sling Health Checks provide an easy way to monitor a job remotely by executing a service which returns the status of a job or a collection of jobs.
Depending on what type of job you have, how you determine the status maybe different. If you are writing a batch job, your status will be determined based on things like items updated, items removed, any errors, etc. For event-based jobs the status could be based on an aggregation of the most recent executions.
In most AEM installations you will have to configure Sling Health Checks to use the module. Simply provide an OSGi Configuration named org.apache.sling.hc.core.impl.servlet.HealthCheckExecutorServlet.config as part of your project as shown below:
disabled=B"false" servletPath="/system/health"
This will allow you to access sling health checks under the URL: http://localhost:4502/system/health.
By default, Sling Health Checks returns a HTML representation of the
status of all the checks, but you can filter by tags and return the
results in a JSON or text format.
Once
you’ve enabled Sling Health Checks in your AEM instance, you can add a
check for your job. To complete our ideal background, we’ll add a Sling
Health Check to monitor the job and the report the status based on the
last 10 executions:
@Component(service = { DynamicMBean.class, Runnable.class, HealthCheck.class }, property = {
"scheduler.expression=0 * * * * ?", "jmx.objectname=com.perficientdigital.adobe:type=BackgroundJob",
HealthCheck.NAME + "=BackgroundJob", HealthCheck.TAGS + "=myproject", HealthCheck.TAGS + "=author",
HealthCheck.MBEAN_NAME + "=BackgroundJobHC" }, immediate=true)
@Designate(ocd = Config.class)
public class BackgroundJobImpl extends AnnotatedStandardMBean implements BackgroundJobMBean, Runnable, HealthCheck {
private LinkedBlockingQueue recentResults = new LinkedBlockingQueue(10);
private Entry last = null;
private static final Logger log = LoggerFactory.getLogger(BackgroundJobImpl.class);
public BackgroundJobImpl() throws NotCompliantMBeanException {
super(BackgroundJobMBean.class);
}
protected BackgroundJobImpl(Class mbeanInterface) throws NotCompliantMBeanException {
super(mbeanInterface);
}
private String feedUrl;
@ObjectClassDefinition(name = "Background Job Configuration")
public @interface Config {
String feedUrl();
}
@Activate
public void activate(Config config) {
log.info("activate");
this.feedUrl = config.feedUrl();
}
@Override
public void run() {
Entry entry = null;
long start = System.currentTimeMillis();
log.info("Downloading feed {}...", feedUrl);
try {
String content = new URL(feedUrl).getContent().toString();
log.info("Downloaded content {}", content);
entry = new Entry(Status.OK, "Retrieved " + feedUrl + " in " + (System.currentTimeMillis() - start) + "ms");
} catch (IOException e) {
log.warn("Exception retrieving feed {}", feedUrl, e);
entry = new Entry(Status.WARN, "Failed to retrieve " + feedUrl, e);
}
if (!recentResults.offer(entry)) {
recentResults.poll();
recentResults.offer(entry);
}
last = entry;
}
@Override
public String getLastStatus() {
return last.toString();
}
@Override
public Result execute() {
ResultLog resultLog = new ResultLog();
recentResults.forEach(e -> {
resultLog.add(e);
});
return new Result(resultLog);
}
@Override
public void runJob() throws Exception {
run();
}
}
When you open the Sling Health Checks console, you will see a Background Job entry in the Sling Health Checks list:

Hopefully, this article will help you create more reliable background jobs in AEM. If you have any questions about background jobs Sling Health Checks, job configurations or the JMX console please leave a comment below.