Imagine that you’ve invested your time and energy in creating awesome new online content, developing a new product, or writing a press release touting your latest achievement. You publish the pages on your website and keep your eyes on the incoming organic traffic for a few days – but it never arrives. You frantically search Google, but your pages cannot be found. Other pages are there, but not your new page. You get a sinking feeling in your stomach. Where did it go wrong? All of that effort, all that work, is now for naught, simply because Google hasn’t indexed your new page.
We’ve recently encountered a number of instances where client sites were either having a difficult time achieving 100% indexation of their pages or weren’t getting newly published pages indexed in a timely manner without manually submitting them for indexation. In each of these cases, there were a number of issues that likely contributed to the situation, meaning there is usually no single, direct cause for a new page not being indexed.
If you’re trying to understand what’s likely keeping your page out of Google’s index, you should begin by confirming that the page is not indexed. In some cases, a page just isn’t optimized properly for a particular term or is being crowded out of the first few search results pages by the competition. In order to confirm that a page is not in Google’s index, you should begin by running an info:{URL} search, where {URL} is the URL for your particular page. You may also run a site:{domain} {title} search, where {domain} is the root domain of your site, and {title} is the title tag on your URL. If neither of these searches returns the page in question, then it’s time to begin diagnosing the issue.
Indexation issues usually stem from three primary types of problems: discovery, crawlability, and quality.
- Discovery issues would involve search engines being unable to find the URLs, which means no crawling can take place. If the search engines cannot see the URL path, they cannot crawl it – period.
- Crawlability is what it sounds like – it focuses on whether or not search engines can actually crawl the URL in question. If they cannot crawl it, they cannot index it, and won’t rank the page.
- Quality is much more subjective. Essentially, search engines will crawl a page and decide that they do not wish to index content because it does not meet their quality guidelines. Of the three issues mentioned, quality is the most difficult to truly evaluate and quantify.
Each of these problems has its own set of causes, which means that working through the differential diagnosis for each situation may lead you down a number of paths. Based on our recent experiences, we’ve gathered some thoughts on where to start if indexation is an issue for your site.
Discovery:
- Confirm whether or not the URL is directly linked from somewhere in the site and if it can be accessed through normal means, like site-wide navigation or in-text links.
- If these links exist, this will confirm that the URL can be reached through a standard distributed crawl. The ability to naturally find a page is the fundamental aspect of discovery.
- Pay attention to the number of clicks it takes to reach the page in question.
- Clicks are akin to how deep the page is within a site. The deeper a page, the less likely it is to be crawled – unless it has a significant number of external links. Linking to this page from a page higher in the site may allow it to be discovered faster from the start. This is why many sites link to their most recent posts or newest products from the homepage. It gives spiders a quick and easy path from an authoritative page that is usually crawled frequently.
- If a particular page links to your URL in question, check the cache and cache date of that URL.
- To do this, use the info:{URL} search operator again and click on Google’s cache in the list under the page’s information. In the top ribbon bar, Google will indentify via timestamp when this version of the URL was cached.
- For example, if my new page, which we’ll call “/new-page/,” is not being indexed, but is linked to directly from “/old-page/,” then I would check the cache and cache date of “/old-page/.” Was “/old-page/” crawled and indexed before or after you added the link to “/new-page/”? If it hasn’t been crawled since you added the link, page depth and crawl frequency are likely your issue.
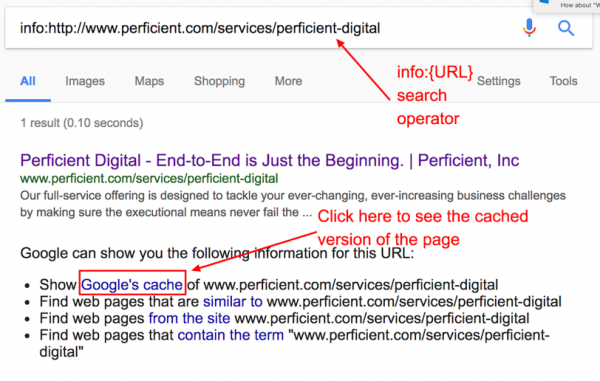
- To do this, use the info:{URL} search operator again and click on Google’s cache in the list under the page’s information. In the top ribbon bar, Google will indentify via timestamp when this version of the URL was cached.
- Confirm that the URL is present in your XML sitemap.
- Outside of a distributed crawl, having a URL listed within the sitemap is one of the most common methods of discovery. If your URL is listed in the sitemap, but cannot be reached through normal navigation behavior, then your URL will be seen as an orphan page. Orphan pages are problematic in that they can’t be reached by any method other than the sitemap or external link. As a result, the page will not receive any added value from internal PageRank, which will restrict the page’s organic search visibility.
- While you’re at it, take some time to make sure your sitemap is current. Many people assume that their sitemap is current because they have it set to update automatically. Unfortunately, these processes can sometimes fail, resulting in an out-of-date and inaccurate sitemap. Spend a few minutes searching for your recent URLs. If they’re present and if the “last modified” date is recent, then your sitemap is likely accurate.
- Outside of a distributed crawl, having a URL listed within the sitemap is one of the most common methods of discovery. If your URL is listed in the sitemap, but cannot be reached through normal navigation behavior, then your URL will be seen as an orphan page. Orphan pages are problematic in that they can’t be reached by any method other than the sitemap or external link. As a result, the page will not receive any added value from internal PageRank, which will restrict the page’s organic search visibility.
Solution:
The easiest solution for a discovery problem is to fetch the URL in Google Search Console and submit it for indexation. However, this is a short-term solution, as it will only correct the issue for this particular URL. Furthermore, you are limited to submitting 10 URLs each month for indexation, so if you find yourself doing this exercise regularly, you will run out of submissions rather quickly.
Crawlability:
- Confirm that the page is not blocked by any standard means.
- Meta Robots – The first place to check would be the meta robots tag in the page’s <head>. You can find this by quickly searching the page’s source code from any browser or in your site’s content management system. If the meta robots tag says “noindex” for one of its values, the page will not be indexed by the search engines.
- While this tag is supposed to be placed in a site’s <head>, we’ve seen instances where a rogue tag was copied into the <body> of a page. Even though it’s in the wrong spot, it will still block the page from indexation.
- Robots.txt – The same issue holds true for the robots.txt file, but to a lesser extent. While a robots.txt Disallow directive will prevent crawling and indexation in many cases, Google could still decide to index the page if it feels the page is particularly valuable. The easiest way to diagnose this problem is to use the Robots.txt checker in Google Search Console, which allows you to enter a URL and test it against your current robots.txt file. It will return a result stating whether or not Google is able to crawl the page.
- X-Robots – In rare instances, the x-robots tag, which is contained within the HTTP header, may include a “noindex” value. If this is the case, it would prevent the page from being indexed. To determine if this tag is present, use an HTTP header response checker. In our agency, we prefer httpstatus.io, Screaming Frog SEO Spider, or Greenlane’s Head Exam.
- Meta Robots – The first place to check would be the meta robots tag in the page’s <head>. You can find this by quickly searching the page’s source code from any browser or in your site’s content management system. If the meta robots tag says “noindex” for one of its values, the page will not be indexed by the search engines.
- Confirm that the URL in question does not canonicalize back to another URL.
- To check this, visit the page’s <head> tag or HTTP header and search for the canonical tag. It should completely match your page’s URL with no variations or changes. If the canonical URL is not the same and the canonical declaration is respected by search engines, then your desired URL will not be indexed.
- Fetch and render the URL in Google Search Console to make sure the content is available and is being rendered in a crawlable state.
- This tool will showcase an example of what Google’s spiders see when they crawl and attempt to index the page. If large portions of a page, specifically the page’s content, are missing from the render, then Google is having difficulties crawling and indexing the content appropriately. Similarly, you could check the cache of pages that use the same template to see if the same behavior is present.
- Use an HTTP header response checker to ensure that the URL does not pass through a redirect.
- Fetching the page in Google should also denote any redirects. If the page is being redirected, only the destination URL will be indexed. Additionally, if the page in question was previously the destination for a different redirect, but that redirect has been removed or made temporary, the new URL may be ignored in favor of the old URL.
- Check the security issues section in Google Search Console.
- If any issues have been flagged, you will receive a warning that identifies the type of issue as well some representative page examples. Any flagged issues need to be rectified immediately as it can cause rankings to drop for all pages, not just the ones with the issue.
- If security issues are present, Google will likely show an older version of a page, i.e. one that existed before the issue arose. This can, in some cases, be a completely different URL than the one that used to rank. The new page will not be indexed while it is suspected of being hacked, so get that problem fixed ASAP!
- If any issues have been flagged, you will receive a warning that identifies the type of issue as well some representative page examples. Any flagged issues need to be rectified immediately as it can cause rankings to drop for all pages, not just the ones with the issue.
Solution:

There’s no all-powerful silver bullet to correct the issues listed above, other than eliminating them one by one. No single action will resolve these issues, nor should one problem require the appropriate fix for one that is not occurring. Resolve the issue that presents itself and keep working your way through the potential issue list until you find the root cause.
Quality:
- If the page in question largely utilizes content that can be found elsewhere, either on your site or another, Google may choose to not index the page due to its substantial similarity to other pages.
- We most often see this with product description pages that either leverage the manufacturer’s product description or use the same product description across multiple variations of a product. If Google cannot discover something unique and valuable, it will likely consider the page to be low quality.
- If the page in question features little-to-no text, then it could be considered thin.
- Thin content is not solely determined by word count however. Instead, the page content should be considered in terms of value. If your page does not contain enough information to match the searcher’s intent, such as whether or not the page will answer the question or desire posed by the search query, the page would be considered thin for that particular query.
- It’s important to note that there are cases where a one-word answer will actually suffice, but they’re extremely rare. Place yourself in the shoes of the searcher and ask if the page you’re struggling with provides value in one form or another. Value can come in many forms, like images, videos, or text, so don’t focus on the words alone, but rather the entire presentation of information.
- Thin content is not solely determined by word count however. Instead, the page content should be considered in terms of value. If your page does not contain enough information to match the searcher’s intent, such as whether or not the page will answer the question or desire posed by the search query, the page would be considered thin for that particular query.
- If the page in question suffers from any errors, such as incorrect structured data markup or broken HTML, Google may choose not to index the page.
- Admittedly, this is extremely uncommon, and is added here only as a potential last ditch avenue of investigation.
Solution:
Diagnosing quality issues, in and of themselves, is often quite difficult. Understanding their relationship to indexation issues is even more so. These potential problems are listed here as a suggestion for further investigation. Every quality issue will need to be addressed on a case-by-case basis, but understand that quality issues rarely affect a single URL, which is why we encourage the additional steps below.
Conclusion:
If you do not discover issues through any of these investigation paths, the issue may simply be resource based. Google might not crawl deep enough, or regularly enough, to find and index this page or others on your site. We’ve found some recent success in creating HTML sitemaps containing URLs that are not indexed or crawled frequently, which are then linked to from the homepage. Be warned that this is almost always a last resort solution. Building these HTML sitemaps usually takes some manual work, and certainly requires manual labor to review and update regularly. If these HTML sitemaps aren’t updated regularly, you could start encountering a whole new series of issues.
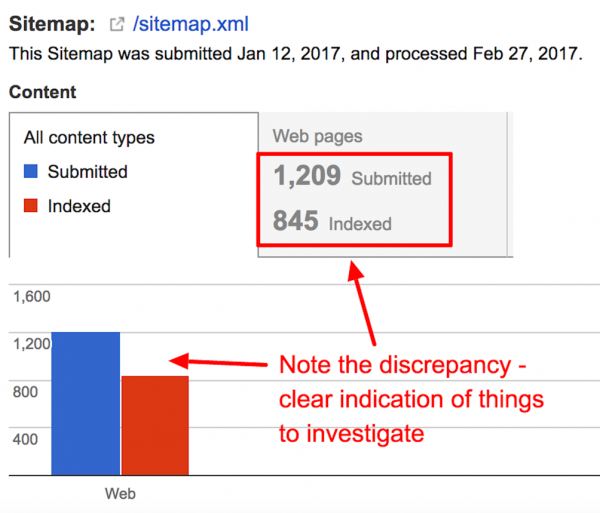
In most cases, an issue with a single URL is likely a symptom of a much more systemic problem. Understanding the indexation rate for your site as a whole, as well as particular sections, such as subfolders or page types, will help you gauge your site’s health more reliably over the long-term. Our advice here is threefold:
- Segment your sitemaps to spot problems sooner. Recently, one of our clients had issues with item detail pages not being indexed. We were able to isolate the problem to this particular set of pages because we had that type of page contained on sitemaps featuring similar pages. We were also able to spot it more quickly due to this segmentation
- A good rule of thumb is to break out your sitemap into smaller sitemaps by subfolder or page type, then list of all of the segmented sitemaps in a sitemap index file. Doing so will allow you to see the indexation of each individual segmented sitemap after they are processed.
- Google Search Console often suffers from data lag, so beginning the process as soon as possible will yield actionable data the earlier you start. Many sitemap changes take days, sometimes even weeks, to process. As a result, it could take some time for this data to start rolling in, if you only start when you suspect there is a problem. In this case, preparing for the issue before it occurs will significantly reduce the time you have to wait to accurately diagnose and treat the issue.
- Take all Google Search Console data with a grain of salt. On numerous occasions, we’ve noticed that the data is only somewhat accurate and should be used for trending purposes, rather than cold, hard facts. Google itself often ends up changing the reporting on data, or correcting an issue that changes the way that data is displayed. Google Search Console data is not the end-all-be-all for site metrics, but can be helpful in guiding you towards a diagnosis.
Like every problem in SEO, indexation issues can be solved with a sound approach, critical thinking and a little technical know-how. While we’ve provided a number of potential avenues for diagnosis and cure, there are still a number of other reasons why indexation issues could be occurring. Regardless, some curiosity and preparation will likely serve everyone well as we ready ourselves and our clients for Google’s upcoming mobile first index.
Author’s Note
I have the opportunity to see data for hundreds of sites each year due to our involvement in a number of migrations, as well as retainer work. During this time, I’ve noticed a slowdown in indexation across the board. It’s my own personal theory that Google is reallocating crawling and indexation resources to begin building the mobile-first index they’ve been touting for the past few months. Given many of the issues that are apparent within the desktop index, it would not surprise me that Google is taking an opportunity to somewhat start from scratch. If they wanted to do that, even partially, maintaining both indexes for even a short amount of time would be incredibly taxing.