
Overview:
A Data Factory or Synapse Workspace can have multiple pipelines. Pipelines are groups of activities that perform a specific task together. Data integration and ETL (Extract, Transform and Load) services in the cloud work together to orchestrate data movement and transform data with ease.
- There are workflows that can ingest data from disparate data sources (called pipelines) that you can create and schedule.
- A complex ETL process can be built visually with data flows or with compute services such as Azure Databricks or Azure SQL Database.
- The transformed data can also be published for consumption by business intelligence (BI) applications to data stores such as Azure SQL Data Warehouse.
- The goal of Azure Data Factory is to enable you to organize raw data into meaningful data stores and data lakes for better business decisions.
Code free ETL as service:-
Invest your time in building business logic and transforming data.
- ETL design without code
- Data from On Premise and other clouds is copied to Azure
- Transforming data at stages
Key Components:
Synapse Analytics workflow consists of the following components:-
- Pipelines
- Activities
- Datasets
- Linked services
- Data Flows
- Integration Runtimes
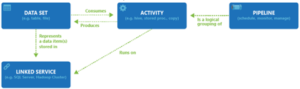
The components work together to create a platform for composing data-driven workflows that move and transform data.
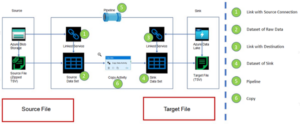
Linked services:
A linked service can be compared to a connection string, which defines the connection information needed for Data Factory to connect with resources from outside. Datasets represent the structure of data, while linked services define how they are connected to the data source.

Datasets:
A dataset is simply a reference to the inputs and outputs you want to use in your activities. The following are examples of source and destination datasets.
Activity:
In a pipeline, activities represent processing steps. Data can be copied from one data store to another using a copy activity, for example.
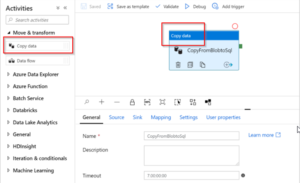
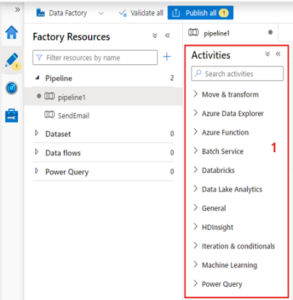
Different types of activities can be added e.g. Data flow, Lookup or stored procedure,Databricks.
Pipeline:-
It is possible for a data factory to have more than one pipeline. A pipeline are logical grouping of activities that performs a unit of work. An activity in a pipeline performs a task together.
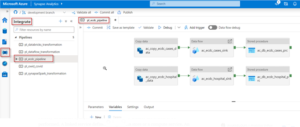
Triggers:
Pipeline execution begins when a trigger determines that it needs to be fired. Different types of events can be triggered by different types of triggers. Pipelines can be scheduled or run immediately when user click on the Add trigger option in the pipeline.
Integration Runtime:
Azure Data Factory and Azure Synapse pipelines use the Integration Runtime (IR) as their compute infrastructure. In an activity, the action to be performed is defined. Data stores and compute services are defined by a linked service. Integration runtimes serve as a bridge between activities and linked services. Referred by the linked service, it is the compute environment where the linked activity runs.
Happy reading & learning.
Useful
Very Informative!
great blog!! it was very enlightening.
Great work, Prathamesh!!
Nice and informative.. Prathamesh