
Apache spark supports many different data formats like Parquet, JSON, CSV, SQL, NoSQL data sources, and plain text files. Generally, we can classify these data formats into three categories: structured, semi-structured, and unstructured data.

Let’s have a brief about each data format:
Structured data:
An Structured data set is a set of data Data that is well organized either in the form of tables or some other way is a structured data set. This data can be easily manipulated through tables or some other method. This kind of data source defines a schema for its data, basically this data stored in a rows and columns which is easy to manage. This data will be stored and accessible in the form of fixed format.
For example, data stored in a relational database with multiple rows and columns.
Unstructured data:
Unstructured data set is a data has no defined structure, which is not organized in a predefined manner. This can have Irregular and ambiguous data.
For example, Document collections, Invoices, records, emails, productivity applications.
Semi-structured data:
Semi-structured data set could be a data that doesn’t have defined format or defined schema not just the tabular structure of data models. This data sources structures per record however doesn’t necessarily have a well–defined schema spanning all records.
For example, JSON and XML.
Reading different data format files in PySpark

Now we will see, How to Read Various File Formats in PySpark (CSV, Json, Parquet, ORC).
CSV (comma-separated values):
A CSV file is a text file that allows data to be saved in a table structured format.
Here we are going to read single csv file:
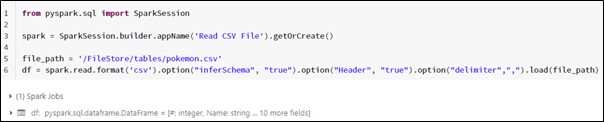
This code will read the CSV file for the given file path present in the current working directory, having delimiter as comma ‘,‘ and the first row as Header.
JSON:
JSON is an open standard file format and data interchange format that uses human-readable text to store and transmit data objects consisting of attribute–value pairs and arrays.
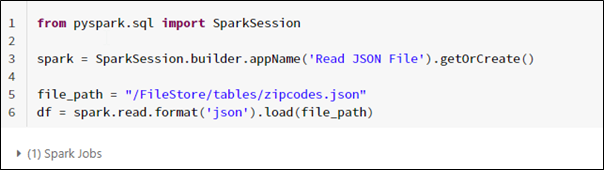
Here we are going to read single JSON file:
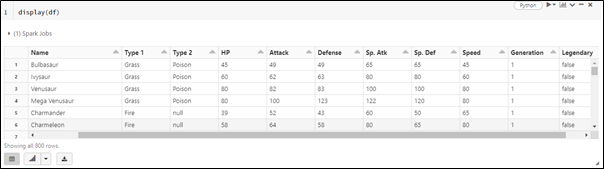
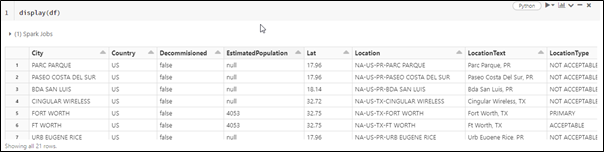
Following is the output for reading a single JSON file.
PARQUET:
Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. To handle complex data in bulk, it provides efficient compression and encoding schemes with enhanced performance.
Here we are going to read single PARQUET file:
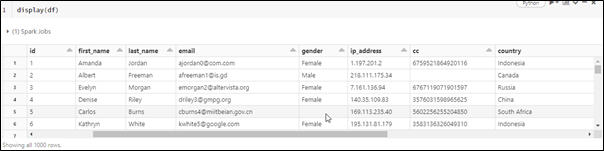
Following is the output for reading a single PARQUET file.
ORC (Optimized Row Columnar):
ORC files are a highly efficient method of storing Hive data. Someone developed the format to overcome the limitations of other Hive file formats. When Spark reads, writes, and processes data, ORC files improve performance.
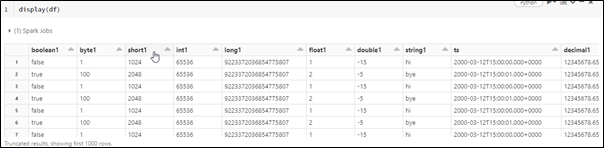
Following is the output for reading a single PARQUET file.
Really informative and well-framed. Well Done Akshay!!
very informative.. Akshay
Can someone help me with the below 2 questions:
In Pyspark:
1) How can I read the .txt file having multiple records in single row
For example:
Ram, 47, Sita, 32, Geeta 43
2) How to read multiline data present in the .txt file
For example:
Ram
37
Ayodhya
Sita
32
Mithila