
Overview:
Today the terminology “Data Analytics” becomes a buzz across all industries & enterprises. Every organization strongly believes Data Analytics greatly helps to get insight & accelerate the business strategies in order to grow & lead in their fast and ever-changing markets.
Azure Databricks:
Azure Databricks is a data analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks offers three environments for developing data intensive applications – Databricks SQL, Databricks Data Science & Engineering, and Databricks Machine Learning.
| Databricks SQL | Provides an easy-to-use platform for analysts who want to run SQL queries on their data lake, create multiple meaningful visualization types to explore query results from different perspectives, and build & share dashboards for the stakeholders to make business decisions. |
| Databricks Data Science & Engineering | Provides an interactive workspace that enables collaboration between data engineers, data scientists and machine learning engineers. In a big data pipeline, the data is ingested into Azure cloud through Azure Data Factory in batches, or streamed near real-time using Apache Kafka, Event Hub or IoT Hub. The data lands in Azure Blob Storage or Azure Data Lake Storage. For analytics, Azure Databricks read data from different data sources and turn into insights using Spark. |
| Databricks Machine Learning | An integrated end-to-end machine learning environment incorporating managed services for experiment tracking, model training, feature development & management, test ML models and serve. |
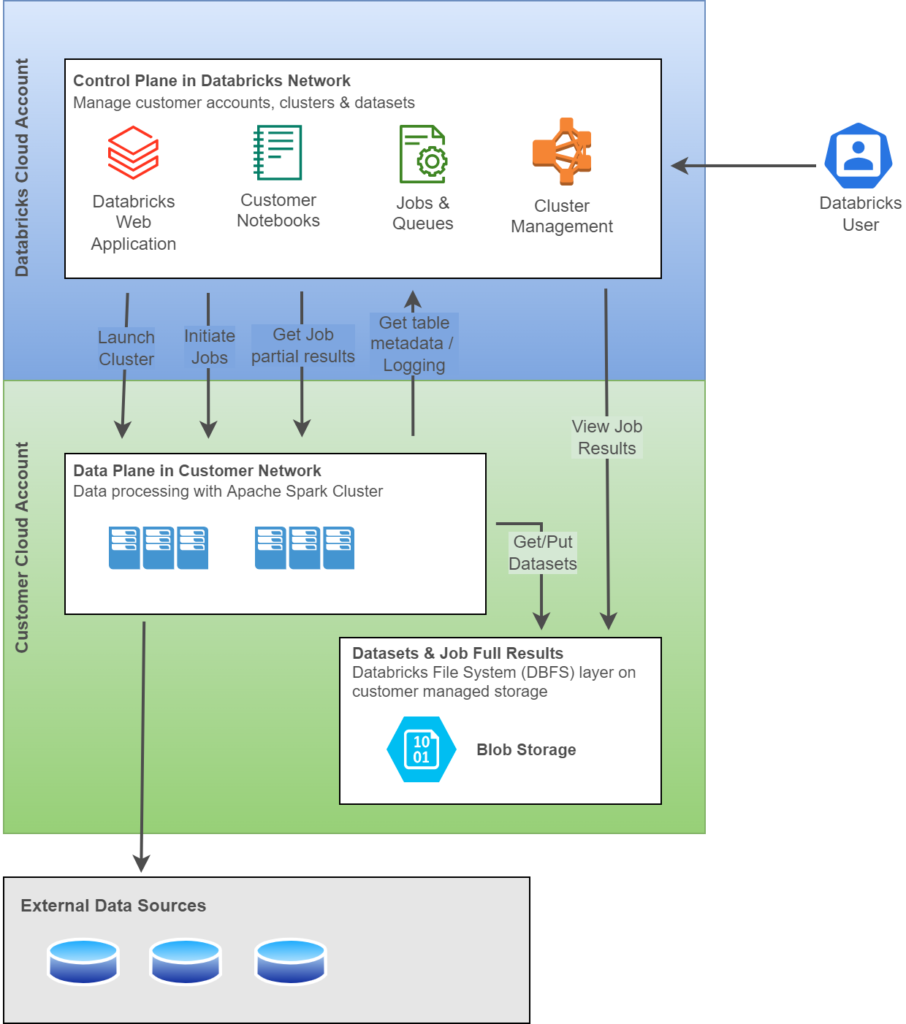
High Level Architecture:
Azure Databricks is designed to enable secure cross-functional team collaboration by keeping as many backend services managed by Azure Databricks so that Data Engineers can stay focused on data analytics tasks.
Azure Databricks operates in Control Plane and Data Plane.
- Control Plane includes the backend services that Azure Databricks manages its own Azure account. Developers’ Notebooks, Jobs & queries, Workspace configurations are stored and managed in Control plane.
- Data Plane is managed by one’s Azure account. All data are stored and processed in this plane. Also, Azure Databricks connectors could be used to connect to external data sources outside of Azure account to ingest data.
Below diagram provides high level architecture of Azure Databricks platform,
Azure Databricks – Cluster Capacity Planning:
It is highly important to choose right Cluster mode and Worker Types, when spinning up a Databricks cluster in Azure cloud to achieve desired performance with optimum cost. While building Azure Databricks Enterprise Data Analytics solution, it is the responsibility of Data Architect / Data Lead to perform cluster capacity planning, considering the business need, performance throughput and cost factors.
Azure Databricks offers multiple Worker Type options that leverages various compute & storage capabilities that can be opted for the desired performance goals.
Below is an abstract of different cluster options offered by Azure Databricks:
| General Purpose | Offers balanced CPU-to-Memory ratio. Suitable for testing & development, small to medium databases, and low to medium traffic web servers. |
| Compute Optimized | Offers High CPU-to-memory ratio. Ideal for medium traffic web servers, network appliances, batch processes and application servers. |
| Memory Optimized | Offers High memory-to-CPU ratio. Suitable for relations database servers, medium to large caches, and in-memory analytics. |
| Storage Optimized | High disk throughput and IO workloads. Ideal for Big Data, SQL, No SQL databases, data warehousing and large transactional databases. |
| GPU | Specialized virtual machines targeted for heavy graphic rendering and video editing, as well as model training and inferencing with deep learning workloads. |
| High-Performance Compute | Offers fastest and most powerful CPU virtual machines with optional high-throughput network interfaces. |
Spark Cluster:

For our discussion, let us consider General Purpose (HDD) “Standard_D16_v3” instance that offers 16 Core CPUs with RAM capacity of 64GB for cluster capacity planning exercise. However, one can choose right instance option based on their business needs. Various instance options and pricing can be referred in Azure Databricks Pricing link.
To chart out an efficient executor configuration, first step is to determine how many actual CPUs are required on the nodes in our cluster. With the above considered instance of “Standard_D16_v3”, there will be 16 CPUs available to utilize.
When a spark job is submitted, we need to allocate at least one CPU for Cluster Manager, Resource Manager, Driver program and other Operating System operations. With one CPU allocated for management operations, we need to utilize 15 available CPUs on each node during Spark processing.
CPU vs Executor:
Now comes the crucial part of capacity planning, that we need to figure out how many cores can be allocated for each executor. The ideal number will bring significant performance throughput to the cluster. With 15 CPU cores, there are 4 possible combinations of configuration:
- 1 Executor with 15 Spark Cores
- 3 Executors with 5 Spark Cores
- 5 Executors with 3 Spark Cores
- 15 Executors with 1 Spark Core
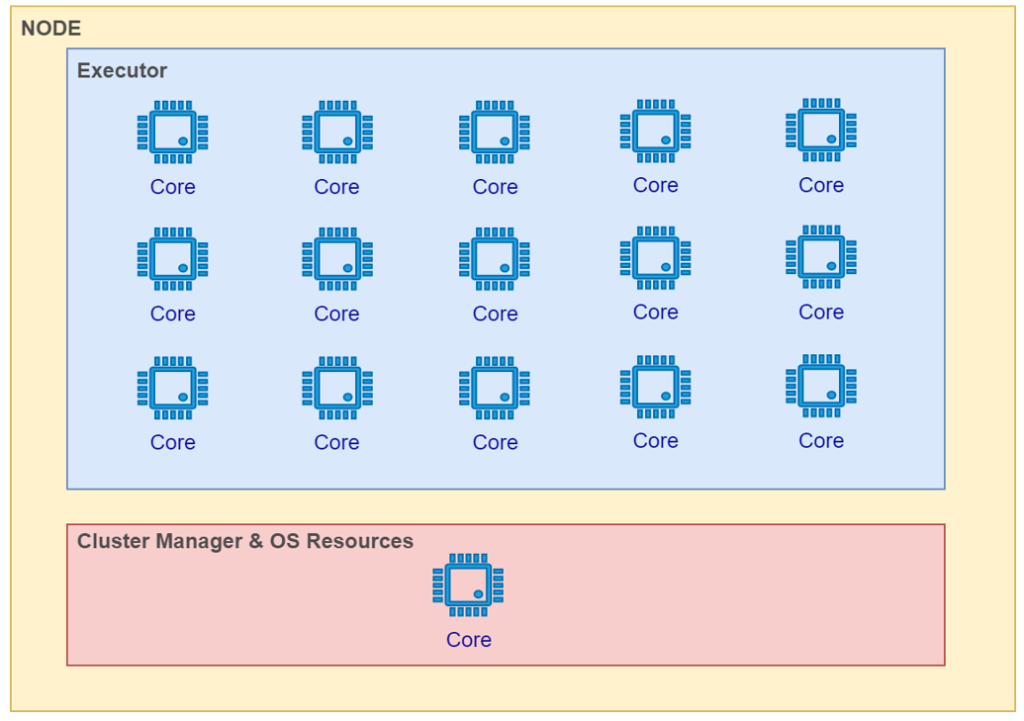
1 Executor with 15 Spark Cores:
This type of executor is called as “Fat Executor”. We may think that an executor with many cores will attain highest performance. It may do so in very few business scenarios. In contrast, ideally for most scenarios, it will degrade the performance. The reason is that an executor with many cores will have large memory pool due to which garbage collection will slow down the job execution. Such cases will be very hard to identify while performance optimization.
15 Executors with 1 Core:
This type of configuration is called as “Thin Executor”. With this setup, we will lose the advantage of parallel processing leveraged by multiple cores and considering it to be inefficient & not recommended.
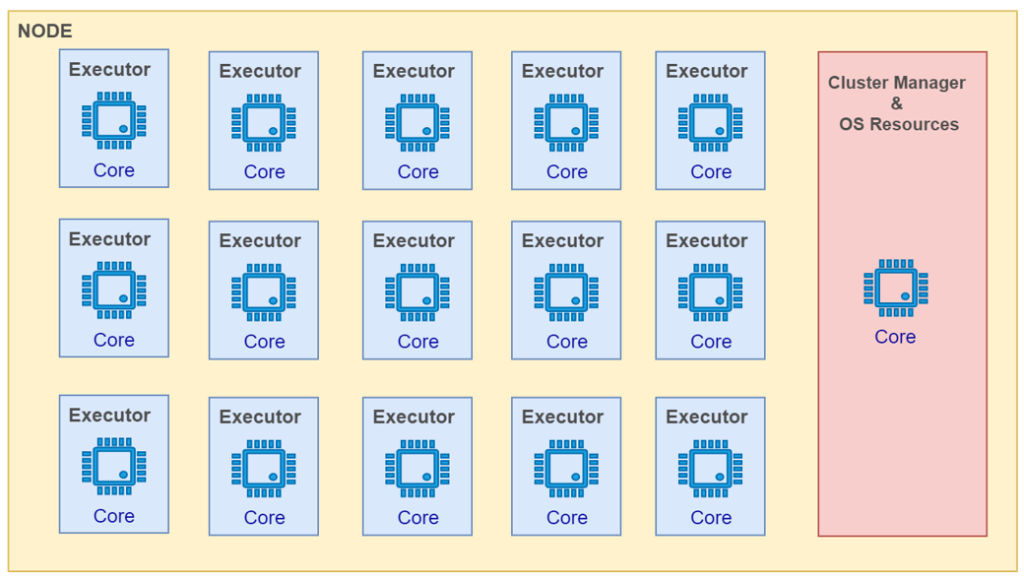
Also, finding the optimum overhead memory allocation for single core executors will be a difficult task. Generally, 10% of executor memory size will be allocated for overhead memory by default.

With 64GB node memory, the overhead memory for each executor can be calculated as below,
Consider 4GB is reserved for Cluster Manager and OS operations.
Available Node Memory = 64GB – 4GB = 60GB
Each Executor Memory = Available Node Memory / No. of Executors = 60GB / 15 = 4GB
Overhead Memory = 10% of Executor Memory = 4GB * 10% = 409MB
The overhead memory of 409MB will be small that will cause trouble while executing spark jobs. Hence, single core executor is not an optimum configuration.
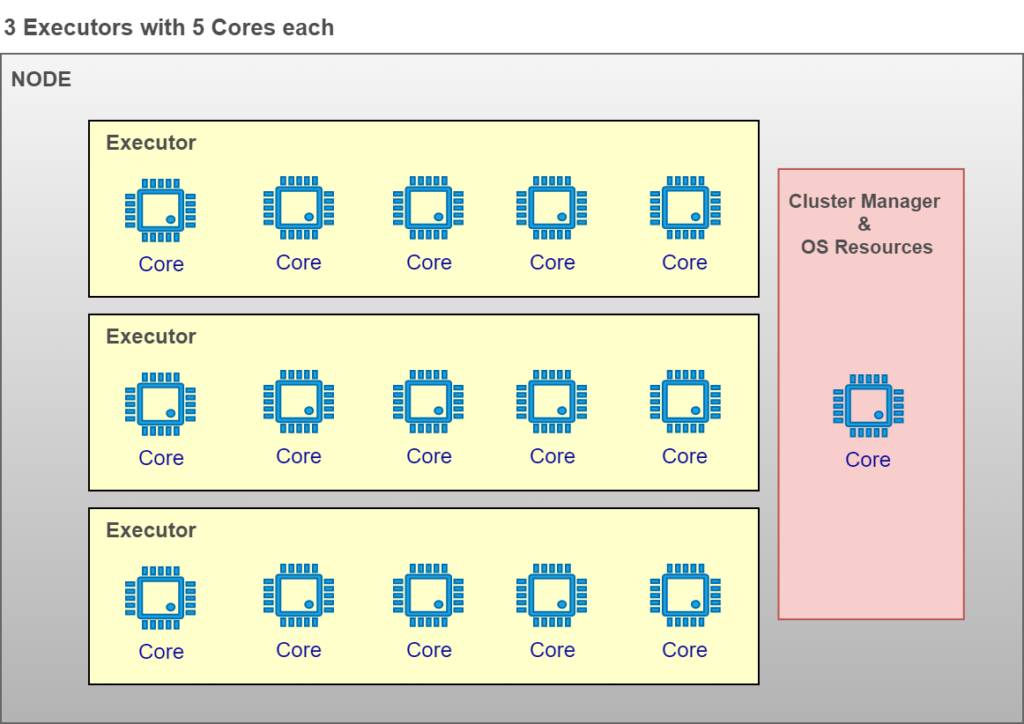
3 Executors with 5 Cores Vs 5 Executors with 3 Cores:
By eliminating Fat Executor and Thin Executor options, we can now choose ideal configuration with rest of the 2 options: 3 Executors with 5 Cores or 5 Executors with 3 Cores.
Both options may look ideal based on the business use cases. However, most of the best practices guide suggest choosing 3 Executors with 5 Cores per node option (Link)
Pic – 3 Executors with 5 Cores
Pic – 5 Executors with 3 Cores
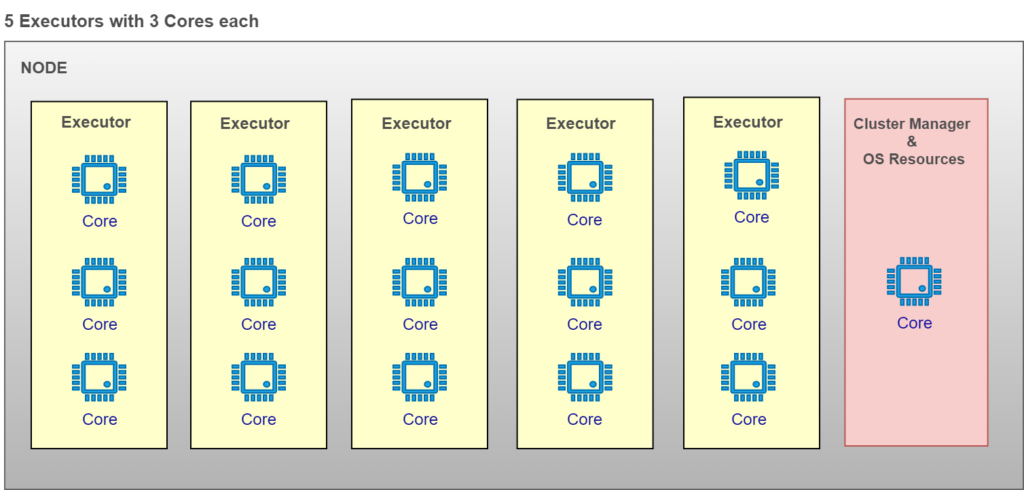
Lesser number of executors will result in lesser number of overhead memory sharing node memory and enables maximum parallel processing capability for each executor.
Conclusion:
With the above discussion, it is ideal to opt for 3 Executors with 5 Cores each per node will bring balanced performance for the given instance type. However, often the cluster sizing will be an iterative exercise by attempting multiple configurations that best suits individual’s business use case. There is no rule written on stone in sizing the Spark cluster as different use cases will require trade-offs between performance and cost to make business decision.