
This is the first blog in a series that dives into how organizations become data-driven, with insights and strategy from Perficient’s Senior Data Strategist and Solutions Architect, Dr. Chuck Brooks.
A data-driven organization is one that effectively and consistently utilizes data in its decision-making process across all levels of the organization. It means driving change, innovating new products, delighting customers, and enhancing employee productivity through the power of data. Research by the Mckinsey Global Institute says data-driven organizations are not only 23 times more likely to acquire customers, but they’re also six times as likely to retain customers and 19 times more likely to be profitable. Leveraging data enables enterprises to make more informed decisions and improve the customer experience.
So, how does a company start the cultural journey to become data-driven? Two key foundational components to the corporate data-driven journey are integrating data from data silos across the organization into a data lake and giving knowledge workers access to the data in the data lake.
Creating a Data Lake
In many organizations data is siloed in repositories of data that are controlled by one department or business unit and isolated from the rest of the organization. That makes it hard for knowledge workers in other parts of the organization to access and use the data. Data silos hinder business operations and the data analytics initiatives that support them. Silos limit the ability of knowledge workers to use data to manage business processes and make informed business decisions. Data must be extracted from data silos and ingested into an integrated data lake. 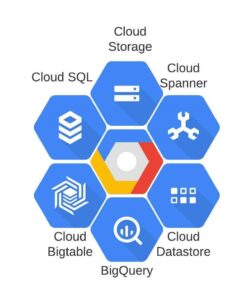
A data lake is a centralized repository designed to store, process, and secure large amounts of structured, semi-structured, and unstructured data. It can store data in its native format and process any variety of it, ignoring size limits. A data lake provides a scalable and secure platform that allows enterprises to: 1) ingest any data from any system at any speed – even if the data comes from on-premises, cloud, or edge-computing systems; 2) store any type or volume of data; 3) process data in real-time or batch mode; and 4) analyze data using SQL, Python, R, or any other language, third-party data, or analytics application. A data lake cannot be a one-trick pony that only provides online analytical processing (OLAP) capabilities.
I think the Google Cloud Platform (GCP) is “The best data management platform on the planet.” The GCP platform provides several data tools that, when combined, form an integrated, easy-to-use data lake that can handle any type of data and any type of data processing. Cloud SQL and Cloud Spanner provide online transaction processing (OLTP) capability, Bigtable and Cloud Firestore provides NoSQL capability, and BigQuery provides OLAP capabilities. GCP gives the data team the tools that it needs to collect, integrate, and deliver data to enterprise knowledge workers.
Enabling Knowledge Workers

The term “knowledge worker” was first coined by Peter Drucker in his book, The Landmarks of Tomorrow (1959). Drucker defined knowledge workers as high-level workers who analyze data and apply theoretical/analytical knowledge to develop insights, trends, products, and services. He noted that knowledge workers would be the most valuable assets of a 21st-century organization because of their high level of productivity and creativity. “Organizations that rely solely on the IT department or analytics teams to fulfill queries around analytics are likely to be dissatisfied with the results,” says Alan Jacobson, Chief Data and Analytics Officer (CDAO) at data science and analytics firm Alteryx.
Data is no longer a byproduct of transactional systems. Applications and technology need to be designed around an understanding of what data is needed in order to make better-informed, data-driven business decisions. The principle of silos or least privilege security model does not enable data-driven decision-making. Enterprises should make sure knowledge workers have access to the up-to-date and timely data they will need to run analytics, identify trends, and make informed business decisions. Data needs to be removed from disparate applications and silos and maintained in a data lake that is easily accessible by knowledge workers across the enterprise.

Read the next blog in the series, here.
Perficient’s Cloud Data Expertise
The world’s leading brands choose to partner with us because we are large enough to scale major cloud projects, yet nimble enough to provide focused expertise in specific areas of your business.
Our cloud, data, and analytics team can assist with your entire data and analytics lifecycle, from data strategy to implementation. We will help you make sense of your data and show you how to use it to solve complex business problems. We’ll assess your current data and analytics issues, and develop a strategy to guide you to your long-term goals. Learn more about our Google Data capabilities, here.
Download the guide, Becoming a Data-Driven Organization With Google Cloud Platform, to learn more about Dr. Chuck’s GCP data strategy.