Businesses and organizations now hold more personal information than ever before. Storing a lot of data may be useful in a variety of ways, such as reporting and analytics, which might expose PII that is linked to the data being analyzed. When data is being transmitted or stored, encryption is useful for protecting it, whereas anonymization is important for preserving data while it’s being utilized or released. Anonymization is better suited to smaller datasets while encryption works better with larger ones. For compliance purposes, a practical approach can be to combine encryption for data rest and in-transit and anonymization for data in use.
The goal of anonymizing data is not merely to obfuscate; it’s critical not to allow re-identify the data after anonymization. This implies considering metrics such as the amount of data, the kind of information in it, and the risk of identification while anonymizing. For most businesses, the goal will be to anonymize sensitive data such as PHI/PHI. In an earlier post, I spoke about using k-anonymity for protecting sensitive data. However, there has been research that has questioned the effectiveness of k-anonymity, particularly for large datasets.
Potential weaknesses with k-anonymity
Yves-Alexandre de Montjoye et al. (2013) found that the reidentification risk of an individual from an anonymous database may be approximated using a function of their “relative” change in information content, which means the more elements of their information are revealed, the more likely they are to be “reidentified”.
According to a 2014 research led by Mark Yatskar, k-anonymization may be easily broken down. Many of the individuals identified in the cell-phone data set created by Yatskar and his team have been reidentified.
In a 2015 study conducted by Vanessa Teague, credit card transactions from 1.1 million people in Australia were made public. For privacy reasons, the data was anonymized using a technique that removes the name, address, and account numbers of each person. If four additional details about an individual, such as the place where a purchase was made and the time it occurred were known, researchers found that 90% of credit card users could be re-identified.
The researchers were able to develop a new algorithm that did not have the same flaws as the initial one. The team unveiled a novel method for anonymizing called “l-diversity anonymization” in this study. They found that their technique “reduces transaction traceability by more than an order of magnitude” compared to other anonymization techniques. So, what is l-diversity?
What is l-diversity

The Future of Big Data
With some guidance, you can craft a data platform that is right for your organization’s needs and gets the most return from your data capital.
k-anonymity does a very good job ensuring that someone can’t reidentify a specific record. However, it’s possible to extrapolate sensitive information about an individual without necessarily accessing their specific records. The original l-diversity paper opens with a very straightforward example. In fact, the images from the k-anonymity example were taken from that very paper.
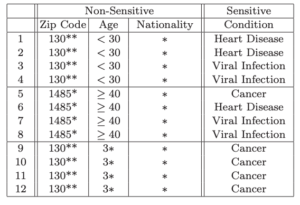
Here are how the authors envisioned two different attacks: homogeneity and background knowledge. Can you identify the condition that a 31-year-old male who lives in the 13053 zip code suffers from? Records 9-12 all share those criteria, and all have the same diagnosis: cancer. There is a lack of diversity in the sensitive information despite the 4-anonymity in the dataset. This is an example of a homogeneity attack.
Now let’s assume that the attacker has some background knowledge. Try to identify the diagnosis of a 21-year-old Japanese female also from the 13053 zip code. There are two options heart disease or viral infection, However, since the Japanese have a documented low incidence of heart disease, you can state with a high degree of confidence the person is suffering from a viral infection.
Advantages of l-diversity
The authors compare the original 4-anonymity table with their 3-diversity table to show that it does not suffer from the same attacks that k-anonymity suffers from while still preventing reidentification.
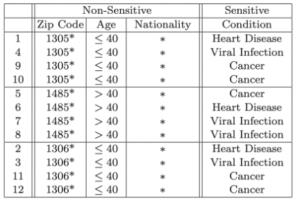
Generalizing the data, or making it less specific, is one of three ways to achieve l-diversity. This is done in the Age column. You can also delete the data (which doesn’t always work well as we saw in the beginning of the article). Finally, and most commonly, you can change the data. You can replace the data with a random value out of the standard distribution of values. This keeps the overall distribution of values for the column the same, but the row value will be wrong. Or you can just hash the data.
Potential Issues with l-diversity
When you talk to a researcher, they will confirm that l-diversity is more correct that k-anonymity. There are very few implementations of this algorithm in actual use, though. A lot of the utility of the dataset is lost. Maybe too much loss just two fix two issues with k-anonymity. And you get two more attack vectors: skewness and similarity.
Similarity attacks are based on the idea that attributed cane be l-diverse but syntactically similar. If you have three attributes: lung cancer, liver cancer and stomach cancer in a dataset, you have satisfied diversity. But an intruder can identify that a subject has cancer. In a skewness attack, there may be a grouping where half the patients have heart disease and the other half do not. If an intruder identifies the target as belonging to that group, then they can infer a 50% chance of a heart condition which if a far higher probability than average.
There is a third option, t-closeness, which addresses the skew and similarity attacks. We will discuss this is a future post.