
–Ruby Lin and Nicolas Frantzen contributed to this blog.
Overview
In life sciences, like many other industries, knowledge is power. Historically, the main challenge has been around sourcing, organizing, and meaningfully surfacing this knowledge. To solve this challenge, one needs to look at innovative and scalable ways, such as AI, to find and organize a wide variety of information from both internal and external sources.
An intelligent knowledge repository that provides relevant and accurate information for consumers, specifically for drug-related information, will require different layers of AI models that can produce predictable and accurate results while quickly adapting to the complex nature of the information.
The dynamic nature of today’s content means we have to work with both structured or unstructured data. Unstructured data (documents, articles, websites, newsletters, blogs, etc.) presents an additional challenge in that it is not readily consumable by systems (other than free-form text, keyword search, etc.). We have to extract the information and organize it first. To do this, we need to curate and structure that data before it can be stored in the knowledge repository, more specifically, a knowledge graph.
Knowledge graphs present significant benefits over traditional databases and tabular schemas in that they allow you to store and maintain relationships between data elements. Once the information is curated, you can use specialized AI models against your knowledge graph to find interesting patterns and predict relationships between pieces of information stored.
While the list of potential applications for this type of solution is vast, here are several use cases that are specific to the life sciences industry:
- Getting country-specific regulatory requirements for submitting a product for marketing approval in a specific geographic region
- Searching and retrieving literature required for authoring a document
- Understanding the state of current research and clinical trials
- Surfacing real-world evidence (RWE) data
- Addressing a product inquiry from a health care provider
And the list goes on.
While these use cases describe some real and complex challenges, there are readily available solution patterns that can be used to streamline the extraction of information.
Let’s dive further into the process of curating content and storing information into a knowledge repository.

Content Sources
The first consideration is the location of the content sources. The content could be internal or external to the company. The sources could be internal product documents, data from internal systems, medical literature documents, regulatory documents from health authority websites, intelligence from trade associations, etc.
The low-hanging fruit for gaining information would be the marketing or literature references for the drugs and medical products. These are pre-curated contents, and the company can digitalize and organize the information in an appropriate knowledge repository.
Secondly, if there is any existing content, this may need further curation before incorporating it into the repository. The common regulatory agencies, trade associations, and medical literature would provide valuable sources of information.
Due to the volume of external documents, web crawlers and other automated solutions must be leveraged (see how Perficient solved this challenge with Handshake) to automatically source documents and run them through an NLP pipeline that will enrich and organize the information extracted.
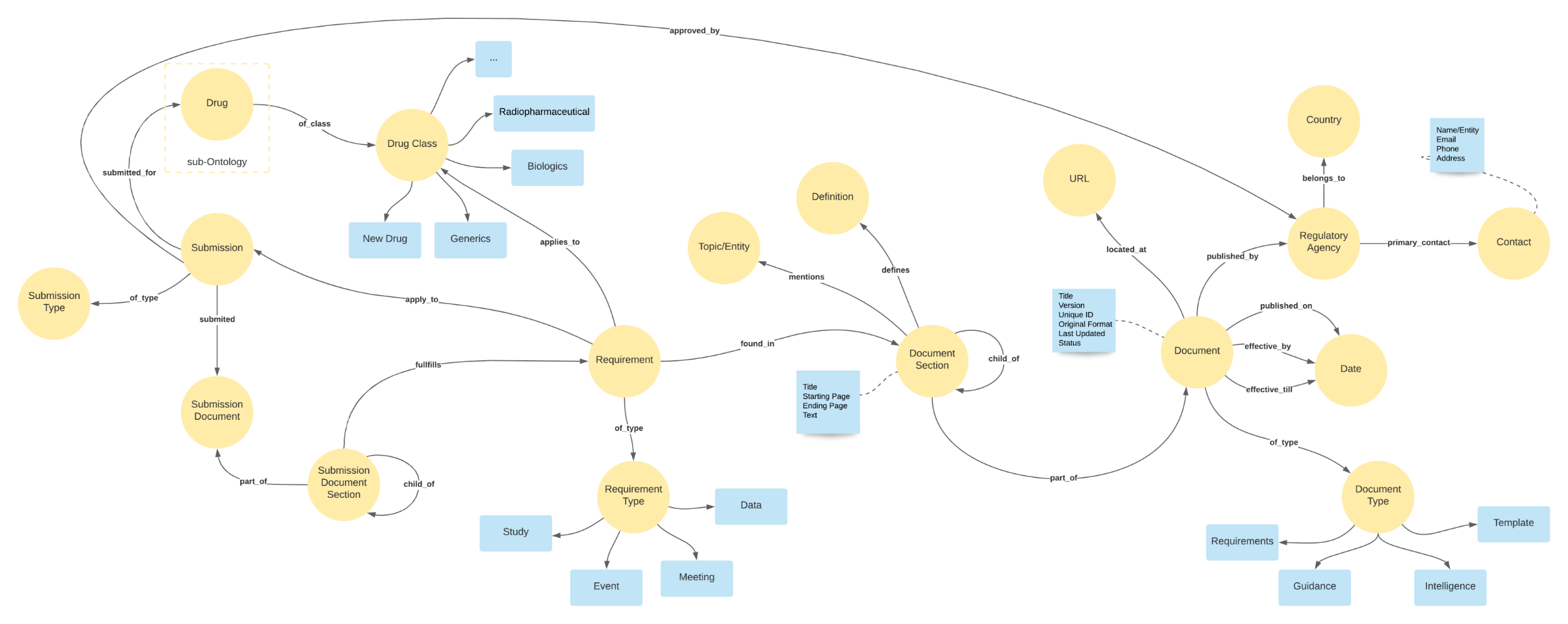
Knowledge Repository Example: Ontology
Below is an example of how structured and unstructured content (i.e., regulatory requirements documents) can be stored in the form of a graph repository.
As these documents can be from various health authorities, the ontology includes the contact details of the source (regulatory authority in this example). A hierarchical structure is defined to store documents, and their sections and a recursive hierarchy keeps sections within sections.
Each section is categorized by topic, definition, associated with a specific requirement. As the documents are curated, the ontology can also be automatically enhanced to ensure that the documents can be curated and stored using the ontology. Once the ontology is created, extracted documents can be stored following the ontology.
An AI model can then be trained to auto-curate the documents, based on the defined ontology, to look for and understand those important concepts and information elements necessary to organize and store the documents within the knowledge repository.
 Saudi Arabia IB as a Knowledge Graph
Saudi Arabia IB as a Knowledge Graph
The diagram below shows a sample document – Saudi Arabia’s Investigators Brochure (IB) – stored as a knowledge graph using the ontology defined in the previous section.
 Conclusion
Conclusion
Though the creation of the ontology is key to the content’s successful curation, AI/ML models can be trained to read any document and store it as a knowledge graph once the ontology is defined. Amazon Neptune, neo4j, Apache Cassandra are some examples of graph databases that are currently available. By combining those graph databases with an AI pipeline (composed of multiple ML and NLP models), you can build a scalable and efficient solution to source and organize information.
With knowledge properly organized, it is possible to tackle the second half of the equation: surface insights and retrieve that information efficiently to end users. Look for another blog post around that topic very soon!