
In my last blog post, I introduced data lineage. Today, I’ll share what an automated data lineage solution can look like when it’s implemented.
In order to reap the benefits obtained from integrating data lineage into the fabric of an overarching data governance program, each of the respective governance tools must be implemented, configured, and populated in its own right. Key data elements must be identified and their business terms defined, data quality rules must be configured and assigned accordingly, and the catalog must be operationalized to periodically scan all data stores, repositories, warehouses, marts, and lakes in order to compile the whereabouts of all data elements throughout the enterprise.

A comprehensive data lineage practice must be established to periodically scan program libraries and databases to create the map of data elements from creation to consumption. Any breaks in the automated handoff of data elements from one point to another – such as when files/tables are downloaded and massaged in an end-user tool such as Excel and then uploaded – have to be “stitched” to reestablish the data’s path.
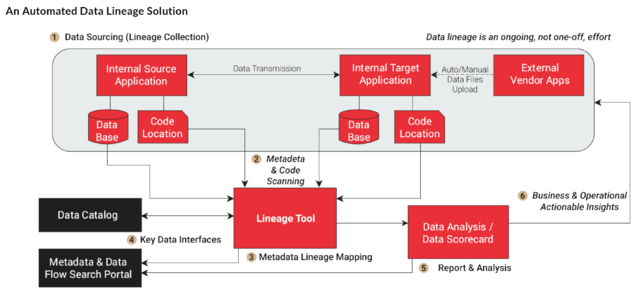
Once the foundational data governance tools have been established and populated, the power of their integration can begin to be realized. Integration points will need to be established, driven by the APIs available within each of the specific governance tools in use. Application code will need to be written to leverage the continuity of control afforded by the data lineage information within the governance toolset.
In my next post, I will discuss the importance of making your data accessible to and searchable by users across the organization.
In the meantime, if you are interested in learning more about this topic, consider downloading our Supercharging Data Governance in Financial Services With Data Lineage guide.