
In our first post, we discussed the need to move away from standalone application solution approach to search connectors. In this post, we will describe the Handshake architecture at a high level. We elected to move towards a microservice architecture for a few reasons:
- Less resource intensive
- Scheduling, component reuse, and maintenance
- Newer and growing technology landscape
- Cloud and local management are nearly interchangeable
- Easier to manage for users (single point of contact and management for many threads)
- Far more flexibility for deployment and dynamic workflows
- Better management of REST and SOAP protocols
Getting the Pieces to Talk to Each Other
Handshake can run either as a self-container or deployed to an existing Wildfly servier. It implements a pluggable component framework using Quartz, ActiveMQ Artemis, Mongo DB, and Derby. The package is bundled with source and target interfaces, transformation classes (configurable java classes that manipulate content or metadata), and a licensing engine. All of the interfaces can be extended, but have the most basic features needed to generate standard objects for processing, connect to requisite systems, and display in the UI.
The front end Angular application is deployed separately (typically within the same domain / firewall). The UI itself can communicate with any number of Wildfly servers and processors. This is choice maximizes our ability to scale and scope the framework.
Additional processors can live on shared source hardware with no penalty to performance. The end goal here is to stream any content to search engines. Our solution needed to be flexible enough to interface with a multitude of storage and communication protocols, without impacting performance. Typically, we deploy one Wildfly runtime server per source server, but this is flexible and is defined by the client’s architecture.
The application can be packaged and deployed as a locally managed .war or as dockerized container (currently ECS only, EKS is on the roadmap).
Microservice Architecture
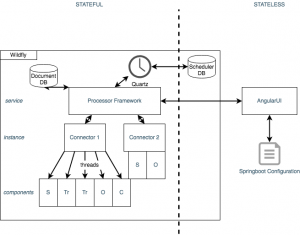
Example of two connector instances: Connector 1 has many queues, Connector 2 has only 2, sending content directly to the search engine
Handshake reads and sends data through JMS queues (ActiveMQ) to stagger processing and track content. Queues, jobs, and schedules are instances of configuration. They are spun up and managed dynamically by an overarching Processor Service (one per processor). The processor schedules Quartz jobs, sends statistics and responses to the UI, and routes content through a connector instance. It also manages traversal checkpoints, hashing, and delete checking.
Each connector instance is a single thread, though support for multi node deployments and simultaneous threading for an instance is on the roadmap. The number of connector instances (and threads) is limited only by the hardware provisioned. In future posts, we will discuss performance demands and sizing for Handshake instances.
Interface Design and Development
When we design for a new source (application to pull content out of) or target (application send content to), we identify the connection protocol (typically a REST API or Database connection), whether it is PUSH or PULL, methods of specifying subsets of data, and the details of joining content, metadata, and permissions. The job then becomes mapping these protocols to our API and the basic transformations necessary to standardize to content for consumption or transmission.
Once these details have been codified and performance tested, they are packaged and added to the project or uploaded through the management UI. They can be invoked as components in connector instances, used as many times as the use case dictates.
Minor configuration for the connector instance provides Handshake with everything it needs to spin up a thread, read and standardize the content, and write it to a JMS queue. Since Handshake has standardized the object, source and targets can be easily swapped or modified.
What’s next
Our next few posts will talk about some of underlying components of our product, the design considerations that led us to them, and reasons you might consider using the same components in your own development projects.