
I’ve said it before and I’ll say it again… it is impressively difficult to integrate data from one or more EMR systems into a cohesive analytical warehouse database. Especially if you’re doing it from scratch.
In my last two blogs (Data Integration: Taming the Beast of Healthcare & Data Integration: Taming the Beast of Healthcare – Part 2) I demonstrated how to reduce time and cost extracting data from your EMR systems and getting it into your warehouse ready for complex analytics and reporting through the use of pre-built “accelerators.”
Before any organization takes on the job to build a data warehouse there needs to be a reason to do it. In IT we sometimes call these “Business Requirements”.
Here’s How it Works.
Someone in a healthcare organization comes to IT and says “we need a bunch of reports to report to the Government and manage our procedures better. Plus, we’d like to analyze our patient and financial data to see if we can provide better service to our patients at a lower cost. We need it right away and we don’t want it to cost tons of money”.
You work with them to come up with the list of reports they want and the analysis type results their looking for.
Working from these, your technical staff looks at existing EMR systems to identify the data fields that meet the requirements and determine the scope of the project. You need Patient, Encounter, Account, Procedure, Diagnosis, Organization, Location, Claims, Medication and Medication Orders, Lab Orders, Clinical Findings and some other stuff, just to get started.
That’s somewhere in the neighborhood of 15+ systems, 353+ source tables, and 2,933+ columns. You’ll need to design a database, build hundreds of programs, test and verify the data and so on (a totally fictitious and ridiculously meaningless set of numbers but I’m trying to illustrate that it’s a bunch of work). You suddenly realize you’re going to need help or this will take forever to complete and cost millions of dollars.
To make things more complicated operational systems store and process data in a co-mingled subject state. This means an encounter focused system stores encounters with associated patient, diagnosis, procedure and supporting clinical orders and clinical finding data all designed mixed together. This makes it easier to store and update transaction data.
But a warehouse cannot be transaction focused. The data design needs to be highly normalized to reduce redundant data. Since it also requires data spread over long periods to spot trends and look for treatment and outcome patterns, the warehouse needs to store billions of records to get meaningful analytics results. This requires a different storage scheme. This is best served with a dimensional star schema design (as described in Part 2). But you will need to re-organize the data before you can load it into a dimensional structure.
So in order to load the warehouse we need to tear apart the source transactions and load the data into subject oriented (Patient, Organization, Encounter, etc.) Atomic database.

The Atomic database is a highly normalized 3rd normal form (sorry, that’s relational model terminology) making sure it is re-linked together to make sure you got it correctly stored.
Note: This is a key factor in the design of the intake gateway, the final piece of the Perficient Analytics Gateway for Healthcare.
Luck you! You read my blog (all three parts) and you know just who to call! But you’re skeptical. Can this be true? So you reach out to several healthcare organizations and they all tell you the same thing… call Perficient! These guys are amazing and you’ll love them!
When we get the call we’ll tell you what we have.
In this illustration you can see,
- The Perficient Analytics Gateway – for Healthcare, a set of pre-built processes that gets your warehouse built and loaded in significantly less time.
- A stable Industry standard Unified Data Model (the one we partnered with and built our product for).
- Nearly turn-key processes to move the data from Source to Stage to Atomic to Dimensional databases made ready for analysis and reporting.
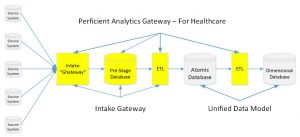
What makes this a standardized process, is it’s alignment with the Atomic database of the Unified Data Model. The stability of the Data Vault Hub & Satellite structure (as described in Part 2) allowed us to design Pre-Stage database tables using a Standard Input Format (for those of you who can’t live without acronyms, we’ll call this the SIF) that has the same columns as the Atomic. A type for a Hub & Satellite combination and another for relationships etc. We have a few others, but you get the picture.
We use the SIF to store source data in subject oriented boundaries, maintaining relationships to all of the related Hubs aligning all with the Atomic model. This makes ingestion programming easy and reusable. It also provides a mechanism for filtering and transforming source columns as preparation for warehouse processing.
The “Intake Gateway” portion of the Perficient Analytics Gateway – for Healthcare is;
- Used to extract data from your sources into the intake “SIF”. This is designed to accept data from any system.
- Processes and stores SIF records in the Pre-Stage database
- It helps filter out duplicates, clean, validate, re-format, etc. incoming data for final loading to the warehouse.
- ETL process to move the data from Pre-Stage to the Atomic.
- Standardize date formats, eliminate garbage data, validate codes and consolidate similar input from multiple systems.
Shown here is the basic data flow from Source to SIF.
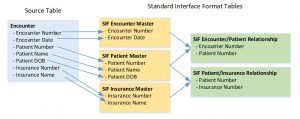
To make this all work we create mapping documents with adequate information to drive a mechanical code generating process that creates the ETL and ELT programming necessary to load the SIF tables correctly. The remaining pre-built ETL programs do the rest.
Data format in all of the columns in the SIF tables is a variable character (with some minor exceptions) at max length so no matter what length or value is coming in from a system for any given field it will be accepted. The warehouse field data types are then used to guide the programs for outgoing data types to match.
Since the warehouse model rarely changes, the programming to move the data from SIF (Pre-Stage) to Atomic works most of the time with little or no modification.
This is a tremendous time saver as shown below.
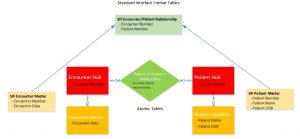
Of course, I’ve simplified this to keep it short.
Needless to say, Perficient’s BI team, source system knowledge and experience, the components of the Gateway and the Data model aren’t cheap. However, in comparison to doing it all yourself from scratch, it’s considerably faster, cleaner and less expensive than you might think.
Give us a call!