
Last September I started a blog series on data integration for Healthcare. The problem, it is impressively difficult to integrate data from one or more EMR systems into a cohesive analytical database. The fact that I’ve been doing that job for the last 2 months is a testament to that statement since it kept me so occupied I’v been unable to add to this series until now.
Let me recap part 1 “Data Integration: Taming the Beast of Healthcare”.
I told you the process of extracting data from your EMR system with its associated ancillary systems and getting it to the point of analysis and reporting can be a terrifyingly complex and time-consuming task. Not to mention extremely expensive.
You need to extract the data, consolidate, clean and verify its accuracy then load it into a well-crafted data warehouse so you can generate required and usable reports.
I hinted that it could be done in less time and reduced cost if you found someone with source system expertise and a proven repeatable process and tool set to do the job for you.
Well then… let me introduce you to the Perficient Analytics Gateway for Healthcare.
Over the past few years the Perficient Healthcare BI team has been working to build a repeatable and cost-effective methodology and tool set that lets us come to your organization, pull data from almost any source system(s) and load it into an advanced and highly scalable data warehouse. We have the experience and expertise to install, customize and implement the data model (you have to buy that) and our Gateway and Accelerator product.
We work with you to get you started then train and hand the reins to your IT staff to continue to build and refine your warehouse. But I’m getting ahead of myself. Let me explain how this works.
We designed it to work in four parts. They are:
- A stable Industry standard Unified Healthcare Data Model in two views, an Atomic relational database model and a Dimensional star schema database model.
- The Gateway product that extracts the data from your source system(s) and loads the data into a pre-stage database to compare with previous extracted data to identify the deltas.
- Programs to pull the data from the Gateway pre-stage and load it to the Atomic
- Programs to pull the data from the Atomic and load it to the Dimensional
The first part was a stable comprehensive data model that provided a complete picture of Provider (Clinical), Payer (Claims) and Accounting (Financial) data. This data model needed to be designed in such a way as to be able to keep up with the Healthcare industry’s constantly expanding data needs and structured consistently across all subject areas.
It had to have a staging database (atomic relational design). This is where you load the extracted data to cleanse and standardize formats of matching data from multiple sources. It also had to have a synchronized warehouse database (star schema design) where you perform analytics and run reports so your organization can make informed decisions to improve patient care.
We found one that was built based on HL7 data and definitions structured using a *Data Vault modeling design method. It met our design requirements and it was an industry wide design being built and maintained by one of our partners.
The data vault method is unique. In contrast, a typical relational modeling design has tables with primary key columns and all associated content. A primary key provides unique data for storage and retrieval of a record. With each retrieval from the database a row in the table is returned with all columns both key and content.

In a data vault design the primary key columns are managed in a separate table without associated content. This is referred to as a Hub. The hub contains unique business keys with additional audit or descriptive fields related to Hub columns. The Hub is stable and generic enough so that it is highly unlikely it will ever change since no data content is stored there.
The content columns are in a separate table called a Satellite which is relationally attached to its Hub. If any changes or expansion is required for content, the “navigational structure” of the database is unaffected. Satellite content changes require only minimal programming effort.
Another important component of the Data Vault design is a Relationship table called a “Link”. A Link joins Hubs together. The Link is bi-directional and always many-to-many to handle any configuration requirement. This makes it an ideal long term design as show below.
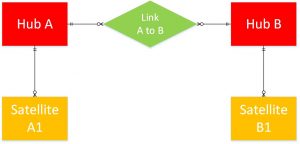
There are a few additional Data Vault Model Types but this is enough to get the general idea.
Hub and Satellite Combination.
The next cool thing is that each Hub and Satellite combination is single subject oriented or **Normalized. Patient data, Hub A & Satellite A1, is separated from Encounter data, Hub B & Satellite B1, but they are related (linked) by the Link table (A to B) so all of the encounters for a given Patient can be viewed and vice-versa
The point I’m trying to make is this structure is ideal for navigational stability which makes it ideal for subject matter data storage and reusable programming. It also means that regardless of the source system database structures or flat file formats, we can store that extracted data in this format.
In addition, the next step in the warehouse development process (Star Schema) is also provided and synchronized with the atomic model shown above. The main warehouse tables in a star schema are Fact, Dimension and Relationship Tables.
Fact tables consist of the measurements, metrics or “facts” of a business process. Fact tables typically contain two types of columns those that contain the facts of the business process and the foreign keys of dimension table(s).
In this model Dimension tables are “Conformed” meaning they are subject oriented, timestamp based and kept in sync with the matching iterations of their atomic hub & satellite counterparts. They are a single representation of that subject at any given point in time and used to support data across multiple Fact tables.
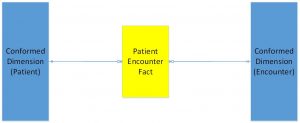
Using these backdrop models we built the Perficient Analytics Gateway for Healthcare. Since the staging model is stable and synced to the warehouse model we pre-built ETL programs to move the data from the Atomic to the Dimensional. Data stored in the Atomic is automatically moved into the Dimensional with little additional programming and only when customization is required.

We come to your shop, install the database, fire up our Perficient Analytics Gateway for Healthcare accelerator modules and BAM! Instead of taking 18 to 24 months to design a warehouse and build programming to load source data we’ve “accelerated” the process to get the data ready for analysis and reporting considerably faster. Saving time and money in the process.
There is one more key part to the Perficient Analytics Gateway for Healthcare though. That’s the part where we’ve developed a process to analyze your sources, map source data (any database) to the Data Vault database and process it through the “Gateway”, the crown jewel of the package.
Tune in for “Data Integration: Taming the Beast of Healthcare – Part 3” and I’ll tell you more about that part!
Till then…
*Data vault modeling is a database modeling method that is designed to provide long-term historical storage of data coming in from multiple operational systems.
**Normalized is a database modeling term that splits each subject data into its own table(s). In other words, in a Patient Encounter the Patient specific data is stored in a table(s) and the Encounter data is stored in another set then the Hubs are linked together. This means that the Patient specific data is reusable and only needs to be stored once where many Encounters can be related to that single Patient record.